
Guia definitivo para aprendizado profundo com rede neural em 2022
Publicados: 2021-01-03No aprendizado profundo com Keras , você não precisa codificar muito, mas há algumas etapas nas quais você precisa avançar lentamente para que, em um futuro próximo, você possa criar seus modelos. O fluxo de modelagem é carregar dados, definir o modelo Keras, compilar o modelo Keras, ajustar o modelo Keras, avaliá-lo, unir tudo e fazer as previsões a partir dele.
Mas, às vezes, você pode achar confuso por não ter um bom domínio sobre os fundamentos do aprendizado profundo. Antes de iniciar seu novo projeto de aprendizado profundo com o Keras , certifique-se de ler este guia definitivo que o ajudará a revisar os fundamentos do aprendizado profundo com o Keras .
No campo da Inteligência Artificial, o aprendizado profundo se tornou uma palavra da moda que sempre encontra seu caminho em várias conversas. Quando se trata de transmitir inteligência às máquinas, há muitos anos usamos Machine Learning (ML).
Mas, considerando o período atual, devido à sua supremacia nas previsões, o aprendizado profundo com Keras tornou-se mais apreciado e famoso em comparação com as antigas e tradicionais técnicas de ML.
Índice
Aprendizado Profundo
O aprendizado de máquina possui um subconjunto no qual as Redes Neurais Artificiais (RNA) são treinadas com uma grande quantidade de dados. Esse subconjunto nada mais é do que aprendizado profundo. Como um algoritmo de aprendizado profundo aprende com a experiência, ele executa a tarefa repetidamente; toda vez que ele ajusta um pouco com a intenção de melhorar o resultado.
É denominado como 'aprendizado profundo' porque as redes neurais têm muitas camadas profundas que permitem o aprendizado. O aprendizado profundo pode resolver qualquer problema em que o pensamento seja necessário para descobrir o problema.

Leia: Principais técnicas de aprendizado profundo
Keras
Existem muitas APIs, frameworks e bibliotecas disponíveis para começar com o aprendizado profundo. Mas eis por que o aprendizado profundo com Keras é benéfico . Keras é uma interface de programação de aplicativos (API) de rede neural de alto nível que é executada no topo do TensorFlow – que é uma plataforma de aprendizado de máquina de ponta a ponta e é de código aberto. Não apenas Tensorflow, mas também CNTK, Theano, PlaidML, etc.
Ele ajuda a comoditizar a inteligência artificial (IA) e o aprendizado profundo. A codificação no Keras é portátil, o que significa que usando o Keras você pode implementar uma rede neural enquanto usa o Theano como back-end e depois executá-lo no Tensorflow especificando o back-end. Além disso, não é obrigatório, não é necessário alterar o código.
Se você está se perguntando por que o aprendizado profundo é um termo importante em Inteligência Artificial ou se está com pouca motivação para começar a aprender aprendizado profundo com Keras , este snap de tendências do Google mostra como o interesse das pessoas pelo aprendizado profundo vem crescendo de forma constante em todo o mundo nos últimos anos.
Existem muitas áreas, como processamento de linguagem natural (NLP), visão computacional, reconhecimento de fala, design de medicamentos, bioinformática, etc., onde o aprendizado profundo foi aplicado com sucesso.

Entrando no Deep Learning com Keras
Conforme discutido anteriormente, no aprendizado profundo, as redes neurais artificiais são treinadas com uma grande quantidade de dados. Ao ser treinado, as previsões sobre dados não vistos podem ser facilmente aproveitadas pela rede. Abaixo estão alguns termos importantes geralmente usados no treinamento de uma rede neural necessária em aprendizado profundo com Keras .
Leia também: 15 ideias interessantes de projetos de aprendizado de máquina para iniciantes
Redes neurais
Foram as redes neurais em nosso cérebro que deram origem à ideia de redes neurais artificiais. Normalmente, existem três camadas em uma rede neural. Essas três camadas são: camada de entrada, camada de saída e camada oculta. Um exemplo da rede neural é mostrado na figura abaixo.

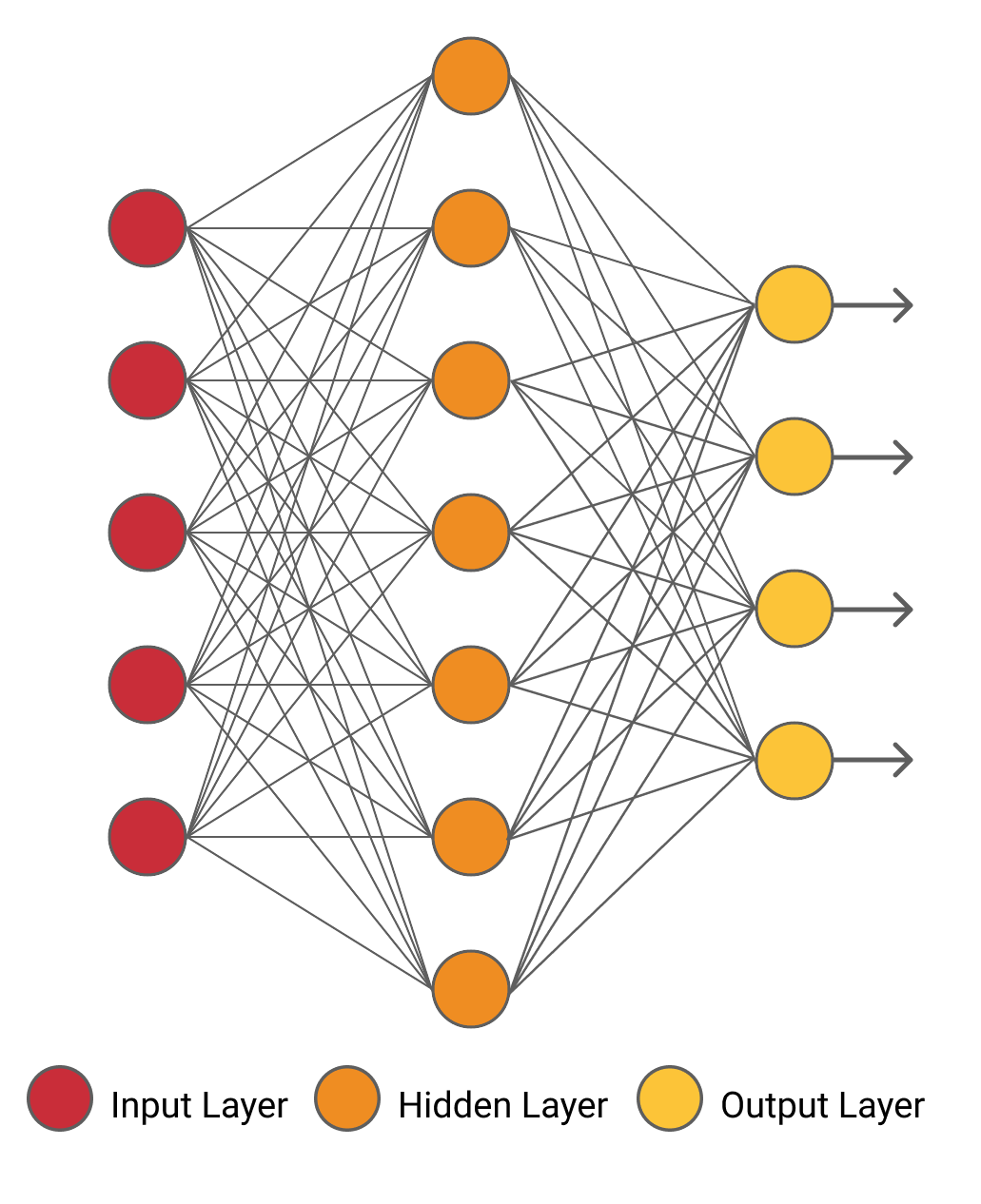
Como a rede neural mostrada acima consiste apenas em uma camada oculta, ela é denominada “rede neural rasa”. Mais camadas ocultas são adicionadas a essas arquiteturas para criar arquiteturas mais complexas.
Redes profundas
Em uma rede profunda, há várias camadas ocultas adicionadas. Quando o número de camadas ocultas aumenta na rede, o treinamento de tais arquiteturas torna-se complexo não apenas pelo tempo gasto para treinar a rede completamente, mas também requer mais recursos. Dada a seguir é uma rede profunda que consiste em uma entrada, quatro camadas ocultas e uma saída.

Treinamento de rede
Uma vez que sua arquitetura de rede tenha sido definida, ela precisa de treinamento para certos tipos de previsões. No processo de treinamento de uma rede, os pesos adequados para cada enlace são encontrados para a rede.
Durante o treinamento, os dados fluem na direção padrão, ou seja, da camada de entrada para a camada de saída e passam por muitas camadas ocultas. Essa rede é chamada de rede Feed-Forward, pois os dados sempre fluem em uma direção que é da camada de entrada para a camada de saída. A propagação de dados aqui é chamada de propagação direta.
Função de ativação
Em uma e em todas as camadas, você precisa calcular a soma ponderada das entradas e passá-la para uma função de ativação. Esta função de ativação torna a rede não linear. É simplesmente uma função matemática que pega a saída e a discretiza. Poucas das funções de ativação mais comumente usadas são hiperbólica, sigmóide, tangente (tanh), Softmax e ReLU.
Retropropagação
Na retropropagação, a propagação dos erros é no sentido inverso, ou seja, da saída para a camada de entrada. No aprendizado supervisionado, a retropropagação é um algoritmo. Para uma determinada função de erro, o gradiente da função de erro é calculado em relação ao peso atribuído em cada conexão.
Através da rede, até mesmo o cálculo do gradiente procede no sentido inverso. O gradiente de peso da última camada é calculado primeiro e o gradiente de peso da primeira camada é calculado por último.
Em cada camada, ao determinar o gradiente para a camada anterior, ele reutiliza os cálculos parciais do gradiente. Isso nada mais é do que “Descida Gradiente”.
Definindo o modelo em aprendizado profundo com Keras
A definição do modelo em deep learning pode ser dividida em várias características:
- Número de camadas.
- Tipos de camadas.
- Número de neurônios em cada camada.
- Função de ativação de cada camada.
- Tamanho de entrada e tamanho de saída.
Leia: Regularização em Deep Learning
A linha inferior
Aprender deep learning com Keras é essencial porque Keras é uma biblioteca python de código aberto e poderosa, fácil de usar e gratuita para avaliar e desenvolver modelos de deep learning. Keras também envolve as bibliotecas de computação numérica amplamente usadas, como TensorFlow e Theano, que permitem treinar e definir os modelos de rede neural com a necessidade de apenas algumas linhas de código de programação.
Depois de ter o python 2 ou 3 instalado e configurado, você está pronto para começar seu aprendizado profundo com o projeto Keras. Você só precisa adicionar o SciPy instalado e configurado, incluindo o NumPy e ter Keras com um backend TensorFlow ou Theano instalado e configurado.
Se você estiver interessado em aprender mais sobre técnicas de aprendizado profundo, aprendizado de máquina, confira o Diploma PG do IIIT-B e do upGrad em aprendizado de máquina e IA, projetado para profissionais que trabalham e oferece mais de 450 horas de treinamento rigoroso, mais de 30 estudos de caso e atribuições, status de ex-alunos do IIIT-B, mais de 5 projetos práticos práticos e assistência de trabalho com as principais empresas.