
Ghid suprem pentru învățare profundă cu rețeaua neuronală în 2022
Publicat: 2021-01-03În deep learning cu Keras , nu trebuie să codificați mult, dar există câțiva pași pe care trebuie să treceți încet, astfel încât, în viitorul apropiat, să vă puteți crea modelele. Fluxul modelării constă în încărcarea datelor, definirea modelului Keras, compilarea modelului Keras, potrivirea modelului Keras, evaluarea acestuia, legarea totul împreună și realizarea predicțiilor din acesta.
Dar uneori, s-ar putea să găsești confuză din cauza faptului că nu ai o stăpânire bună asupra fundamentelor învățării profunde. Înainte de a începe noul proiect de deep learning cu Keras , asigurați-vă că parcurgeți acest ghid final care vă va ajuta să revizuiți elementele fundamentale ale învățării profunde cu Keras .
În domeniul inteligenței artificiale, învățarea profundă a devenit un cuvânt la modă care își găsește întotdeauna drumul în diverse conversații. Când vine vorba de a oferi inteligență mașinilor, de mulți ani am folosit Machine Learning (ML).
Dar, având în vedere perioada actuală, datorită supremației sale în predicții, învățarea profundă cu Keras a devenit mai apreciată și mai faimoasă în comparație cu tehnicile vechi și tradiționale ML.
Cuprins
Invatare profunda
Învățarea automată are un subset în care rețelele neuronale artificiale (ANN) sunt antrenate cu o cantitate mare de date. Acest subset nu este altceva decât învățare profundă. Deoarece un algoritm de învățare profundă învață din experiență, îndeplinește sarcina în mod repetat; de fiecare dată când îl modifică puțin cu intenția de a îmbunătăți rezultatul.
Este denumită „învățare profundă” deoarece rețelele neuronale au multe straturi profunde care permit învățarea. Învățarea profundă poate rezolva orice problemă în care este necesară gândirea pentru a-ți da seama.

Citiți: Top tehnici de învățare profundă
Keras
Există multe API-uri, cadre și biblioteci disponibile pentru a începe cu deep learning. Dar iată de ce învățarea profundă cu Keras este benefică . Keras este o interfață de programare a aplicațiilor de rețea neuronală de nivel înalt (API) care rulează pe partea de sus a TensorFlow – care este o platformă de învățare automată end-to-end și este o sursă deschisă. Nu doar Tensorflow, ci și CNTK, Theano, PlaidML etc.
Ajută la comercializarea inteligenței artificiale (AI) și a învățării profunde. Codarea din Keras este portabilă, înseamnă că folosind Keras puteți implementa o rețea neuronală în timp ce utilizați Theano ca backend și apoi o puteți rula pe Tensorflow specificând backend-ul. De asemenea, nu este obligatoriu, mai degrabă, deloc necesar pentru a schimba codul.
Dacă vă întrebați de ce învățarea profundă este un termen important în inteligența artificială sau dacă întârziați motivația de a începe să învățați învățarea profundă cu Keras , acest snap Google trends arată cum interesul oamenilor pentru învățarea profundă a crescut constant la nivel mondial în ultimii câțiva ani.
Există multe domenii precum procesarea limbajului natural (NLP), viziunea computerizată, recunoașterea vorbirii, proiectarea medicamentelor, bioinformatica etc. în care învățarea profundă a fost aplicată cu succes.

Introducerea în Deep Learning cu Keras
După cum sa discutat mai devreme, în învățarea profundă, rețelele neuronale artificiale sunt antrenate cu o cantitate mare de date. La pregătire, previziunile privind datele nevăzute pot fi utilizate cu ușurință de către rețea. Mai jos sunt câțiva termeni importanți utilizați de obicei în formarea unei rețele neuronale necesare în învățarea profundă cu Keras .
Citește și: 15 idei interesante de proiecte de învățare automată pentru începători
Rețele neuronale
Rețelele neuronale din creierul nostru au dat naștere ideii de rețele neuronale artificiale. De obicei, există trei straturi într-o rețea neuronală. Aceste trei straturi sunt: stratul de intrare, stratul de ieșire și stratul ascuns. Un exemplu de rețea neuronală este prezentat în figura de mai jos.

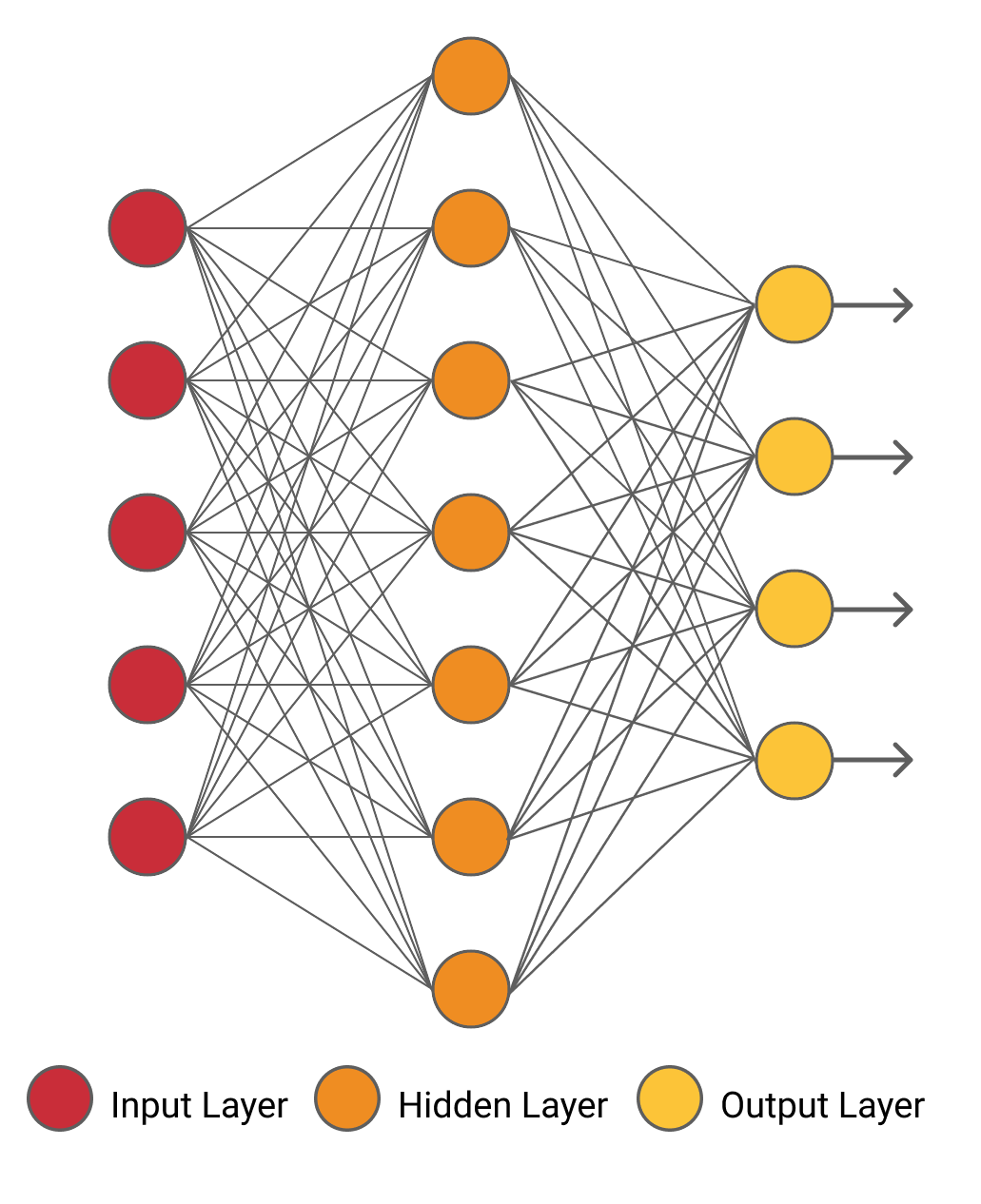
Deoarece rețeaua neuronală prezentată mai sus constă doar dintr-un strat ascuns, este numită „rețea neuronală superficială”. Mai multe straturi ascunse sunt adăugate în astfel de arhitecturi pentru a crea arhitecturi mai complexe.
Rețele profunde
Într-o rețea profundă, sunt adăugate mai multe straturi ascunse. Atunci când numărul de straturi ascunse crește în rețea, antrenarea unor astfel de arhitecturi devine complexă nu numai în ceea ce privește timpul necesar pentru antrenarea completă a rețelei, dar necesită și mai multe resurse. Mai jos este o rețea profundă care constă dintr-o intrare, patru straturi ascunse și o ieșire.

Training in retea
Odată ce arhitectura dvs. de rețea a fost definită, are nevoie de pregătire pentru anumite tipuri de predicții. În procesul de antrenament al unei rețele, ponderile adecvate pentru fiecare legătură sunt găsite pentru rețea.
În timp ce antrenamentul se desfășoară, datele circulă în direcția standard, adică de la stratul de intrare la nivelul de ieșire și trec multe straturi ascunse. Această rețea se numește rețea Feed-Forward Network deoarece datele circulă întotdeauna într-o singură direcție, care este de la nivelul de intrare la nivelul de ieșire. Propagarea datelor aici se numește Forward Propagation.
Funcția de activare
La unul și la toate straturile, trebuie să calculați suma ponderată a intrărilor și să o transmiteți unei funcții de activare. Această funcție de activare face rețeaua neliniară. Este pur și simplu o funcție matematică care preia rezultatul și o discretizează. Puține dintre cele mai frecvent utilizate funcții de activare sunt hiperbolice, sigmoidă, tangentă (tanh), Softmax și ReLU.
Propagarea inversă
În retropropagarea, propagarea erorilor este în direcția înapoi, adică de la nivelul de ieșire la nivelul de intrare. În învățarea supravegheată, retropropagarea este un algoritm. Pentru o funcție de eroare dată, gradientul funcției de eroare este calculat în raport cu greutatea atribuită la fiecare conexiune.
Prin intermediul rețelei, chiar și calculul gradientului decurge în direcția înapoi. Primul gradient de greutate al ultimului strat este calculat, iar gradientul de greutate al primului strat este calculat la ultimul.
La fiecare strat, la determinarea gradientului pentru stratul precedent, reutiliza calculele parțiale ale gradientului. Aceasta nu este altceva decât „Coborâre în gradient”.
Definirea modelului în deep learning cu Keras
Definirea modelului în deep learning poate fi împărțită în mai multe caracteristici:
- Numărul de straturi.
- Tipuri de straturi.
- Numărul de neuroni din fiecare strat.
- Funcția de activare a fiecărui strat.
- Dimensiunea de intrare și dimensiunea de ieșire.
Citiți: Regularizarea în deep learning
Concluzia
Învățarea învățării profunde cu Keras este esențială, deoarece Keras este o bibliotecă python puternică, open source și gratuită, ușor de utilizat, pentru evaluarea și dezvoltarea modelelor de deep learning. Keras include, de asemenea, bibliotecile de calcul numeric utilizate pe scară largă, cum ar fi TensorFlow și Theano, care vă permit să antrenați și să definiți modelele de rețele neuronale, având nevoie de doar câteva linii de cod de programare.
Odată ce ați instalat și configurat python 2 sau 3, sunteți gata să începeți cu proiectul de deep learning cu Keras . Trebuie doar să adăugați SciPy instalat și configurat, inclusiv NumPy și să aveți Keras cu un backend TensorFlow sau Theano instalat și configurat.
Dacă sunteți interesat să aflați mai multe despre tehnicile de învățare profundă, învățarea automată, consultați Diploma PG de la IIIT-B și upGrad în Învățare automată și AI, care este concepută pentru profesioniști care lucrează și oferă peste 450 de ore de formare riguroasă, peste 30 de studii de caz și misiuni, statutul de absolvenți IIIT-B, peste 5 proiecte practice practice și asistență la locul de muncă cu firme de top.