
Panduan Utama untuk Pembelajaran Mendalam dengan Neural Network pada tahun 2022
Diterbitkan: 2021-01-03Dalam pembelajaran mendalam dengan Keras , Anda tidak perlu banyak membuat kode, tetapi ada beberapa langkah yang perlu Anda lewati secara perlahan sehingga dalam waktu dekat, Anda dapat membuat model Anda. Alur pemodelan adalah memuat data, mendefinisikan model Keras, mengkompilasi model Keras, menyesuaikan model Keras, mengevaluasinya, mengikat semuanya bersama-sama, dan membuat prediksi darinya.
Namun terkadang, Anda mungkin merasa bingung karena tidak menguasai dasar-dasar deep learning dengan baik. Sebelum memulai pembelajaran mendalam baru Anda dengan proyek Keras , pastikan untuk membaca panduan pamungkas ini yang akan membantu Anda merevisi dasar-dasar pembelajaran mendalam dengan Keras .
Di bidang Kecerdasan Buatan, pembelajaran mendalam telah menjadi kata kunci yang selalu ditemukan dalam berbagai percakapan. Dalam hal menanamkan kecerdasan ke mesin, sudah sejak bertahun-tahun kami menggunakan Machine Learning (ML).
Namun, mengingat periode saat ini, karena keunggulannya dalam prediksi, pembelajaran mendalam dengan Keras menjadi lebih disukai dan terkenal dibandingkan dengan teknik ML lama dan tradisional.
Daftar isi
Pembelajaran Mendalam
Pembelajaran mesin memiliki subset di mana Jaringan Syaraf Tiruan (JST) dilatih dengan sejumlah besar data. Subset ini tidak lain adalah pembelajaran yang mendalam. Karena algoritme pembelajaran mendalam belajar dari pengalaman, ia melakukan tugas berulang kali; setiap kali tweak itu sedikit berniat untuk meningkatkan hasilnya.
Ini disebut sebagai 'pembelajaran mendalam' karena jaringan saraf memiliki banyak lapisan dalam yang memungkinkan pembelajaran. Pembelajaran yang mendalam dapat memecahkan masalah apa pun yang membutuhkan pemikiran untuk memecahkan masalah tersebut.

Baca: Teknik Pembelajaran Mendalam Teratas
Keras
Ada banyak API, kerangka kerja, dan pustaka yang tersedia untuk memulai pembelajaran mendalam. Tapi inilah mengapa pembelajaran mendalam dengan Keras bermanfaat . Keras adalah antarmuka pemrograman aplikasi jaringan saraf (API) tingkat tinggi yang berjalan di atas TensorFlow – yang merupakan platform pembelajaran mesin ujung ke ujung dan merupakan sumber terbuka. Tidak hanya Tensorflow, tetapi juga CNTK, Theano, PlaidML, dll.
Ini membantu dalam komoditi kecerdasan buatan (AI) dan pembelajaran yang mendalam. Pengkodean di Keras bersifat portabel, artinya dengan menggunakan Keras Anda dapat mengimplementasikan jaringan saraf saat menggunakan Theano sebagai backend dan kemudian menjalankannya di Tensorflow dengan menentukan backend. Juga lebih lanjut, itu tidak wajib, tidak diperlukan sama sekali untuk mengubah kode.
Jika Anda bertanya-tanya mengapa pembelajaran mendalam adalah istilah penting dalam Kecerdasan Buatan atau jika Anda kehilangan motivasi untuk mulai belajar pembelajaran mendalam dengan Keras , jepretan tren google ini menunjukkan bagaimana minat orang pada pembelajaran mendalam telah berkembang dengan mantap di seluruh dunia selama beberapa tahun terakhir.
Ada banyak bidang seperti pemrosesan bahasa alami (NLP), visi komputer, pengenalan suara, desain obat, bioinformatika, dll di mana pembelajaran mendalam telah berhasil diterapkan.

Belajar Mendalam dengan Keras
Seperti yang dibahas sebelumnya, dalam pembelajaran mendalam, jaringan saraf tiruan dilatih dengan sejumlah besar data. Saat dilatih, prediksi pada data yang tidak terlihat dapat dengan mudah dicairkan oleh jaringan. Diberikan di bawah ini adalah beberapa istilah penting yang biasanya digunakan dalam pelatihan jaringan saraf yang diperlukan dalam pembelajaran mendalam dengan Keras .
Baca juga: 15 Ide Proyek Pembelajaran Mesin yang Menarik Untuk Pemula
Jaringan Saraf
Itu adalah jaringan saraf di otak kita yang memunculkan ide jaringan saraf tiruan. Biasanya, ada tiga lapisan dalam jaringan saraf. Ketiga lapisan tersebut adalah – lapisan masukan, lapisan keluaran, dan lapisan tersembunyi. Contoh dari jaringan saraf adalah seperti yang ditunjukkan pada gambar di bawah ini.

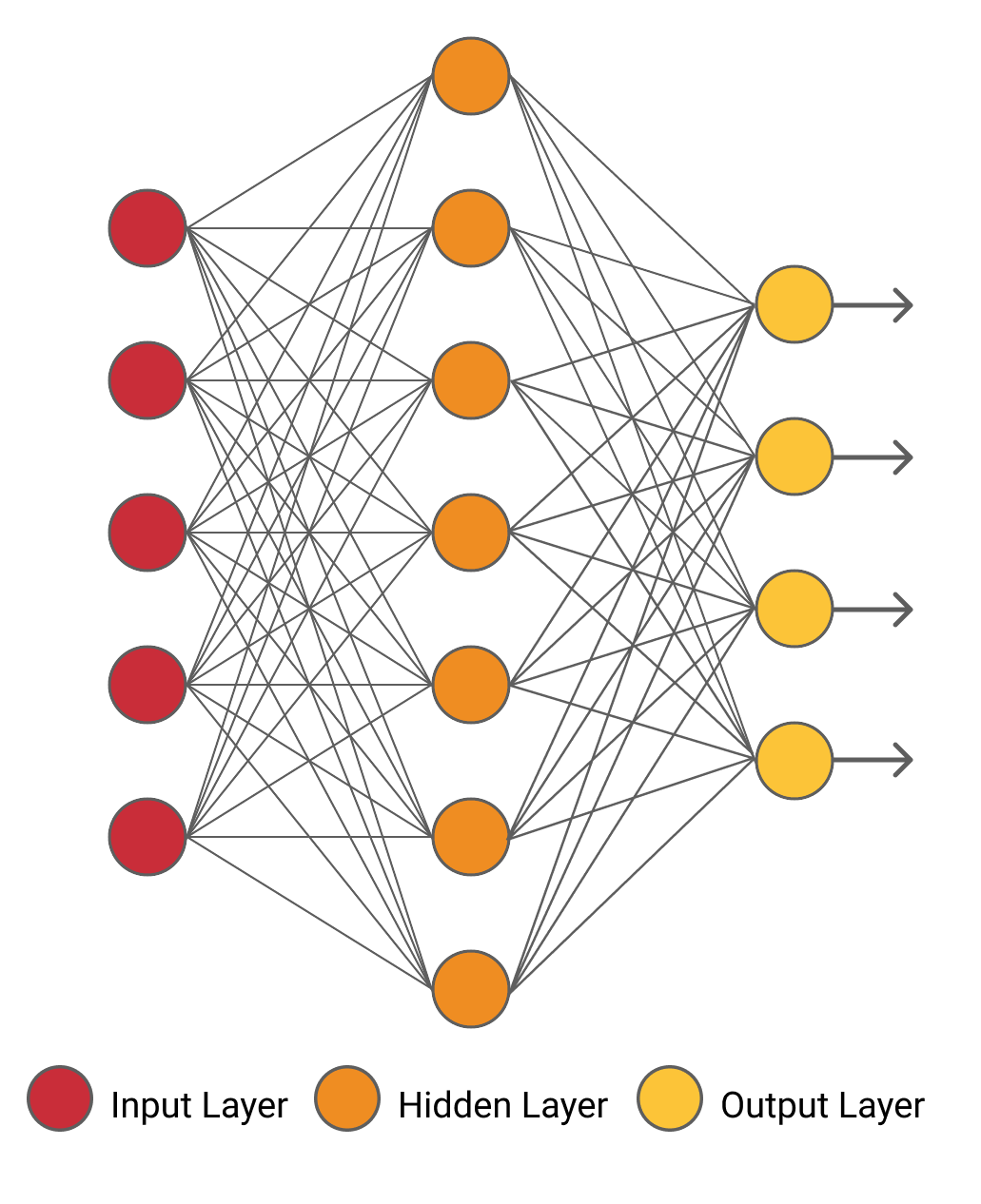
Karena jaringan saraf yang ditunjukkan di atas hanya terdiri dari satu lapisan tersembunyi, itu disebut sebagai "jaringan saraf dangkal". Lebih banyak lapisan tersembunyi ditambahkan dalam arsitektur tersebut untuk membuat arsitektur yang lebih kompleks.
Jaringan Dalam
Dalam jaringan yang dalam, ada beberapa lapisan tersembunyi yang ditambahkan. Ketika jumlah lapisan tersembunyi meningkat dalam jaringan, pelatihan arsitektur tersebut menjadi kompleks tidak hanya dalam hal waktu yang dibutuhkan untuk melatih jaringan sepenuhnya, tetapi juga membutuhkan lebih banyak sumber daya. Diberikan di bawah ini adalah jaringan dalam yang terdiri dari input, empat lapisan tersembunyi, dan output.

Pelatihan Jaringan
Setelah arsitektur jaringan Anda ditentukan, diperlukan pelatihan untuk jenis prediksi tertentu. Dalam proses pelatihan jaringan, bobot yang tepat untuk setiap tautan ditemukan untuk jaringan.
Selama pelatihan berlangsung, data mengalir dalam arah standar, yaitu dari lapisan input ke lapisan keluaran dan melewati banyak lapisan tersembunyi. Jaringan ini disebut jaringan Feed-Forward Network karena data selalu mengalir dalam satu arah yaitu dari input ke output layer. Perambatan data di sini disebut Perambatan Maju.
Fungsi Aktivasi
Pada satu dan semua lapisan, Anda perlu menghitung jumlah tertimbang dari input dan meneruskannya ke fungsi Aktivasi. Fungsi aktivasi ini membuat jaringan menjadi nonlinier. Ini hanyalah fungsi matematika yang mengambil output dan mendiskritkannya. Beberapa fungsi aktivasi yang paling umum digunakan adalah hiperbolik, sigmoid, tangen (tanh), Softmax, dan ReLU.
propagasi balik
Pada backpropagation, kesalahan propagasi dalam arah mundur, yaitu dari output ke lapisan input. Dalam pembelajaran terawasi, backpropagation adalah sebuah algoritma. Untuk fungsi kesalahan tertentu, gradien fungsi kesalahan dihitung sehubungan dengan bobot yang ditetapkan pada setiap koneksi.
Melalui jaringan, bahkan perhitungan gradien berjalan ke arah belakang. Gradien bobot lapisan terakhir dihitung terlebih dahulu dan gradien bobot lapisan pertama dihitung paling akhir.
Pada setiap lapisan, dalam menentukan gradien untuk lapisan sebelumnya, menggunakan kembali perhitungan parsial gradien. Ini tidak lain adalah "Gradient Descent".
Mendefinisikan model dalam deep learning dengan Keras
Pendefinisian model dalam deep learning dapat dibagi menjadi beberapa karakteristik:
- Jumlah lapisan.
- Jenis lapisan.
- Jumlah neuron pada setiap lapisan.
- Fungsi aktivasi setiap lapisan.
- Ukuran masukan dan Ukuran keluaran.
Baca: Regularisasi dalam Deep Learning
Garis bawah
Mempelajari pembelajaran mendalam dengan Keras sangat penting karena Keras adalah pustaka python gratis dan open source yang mudah digunakan dan kuat untuk mengevaluasi dan mengembangkan model pembelajaran mendalam. Keras juga membungkus perpustakaan komputasi numerik yang banyak digunakan seperti TensorFlow dan Theano yang memungkinkan Anda untuk melatih serta menentukan model jaringan saraf hanya dengan beberapa baris kode pemrograman.
Setelah Anda menginstal dan mengonfigurasi python 2 atau 3, Anda siap untuk memulai pembelajaran mendalam Anda dengan proyek Keras . Anda hanya perlu menambahkan SciPy yang diinstal dan dikonfigurasi, termasuk NumPy dan memiliki Keras dengan backend TensorFlow atau Theano yang diinstal dan dikonfigurasi.
Jika Anda tertarik untuk mempelajari lebih lanjut tentang teknik pembelajaran mendalam, pembelajaran mesin, lihat PG Diploma IIIT-B & upGrad dalam Pembelajaran Mesin & AI yang dirancang untuk profesional yang bekerja dan menawarkan 450+ jam pelatihan ketat, 30+ studi kasus & tugas, status Alumni IIIT-B, 5+ proyek batu penjuru praktis & bantuan pekerjaan dengan perusahaan-perusahaan top.