
기계 학습의 의사 결정 트리 설명 [예제 포함]
게시 됨: 2020-12-21소개
의사결정 트리 학습은 주류 데이터 마이닝 기술이며 지도 머신 러닝의 한 형태입니다. 의사 결정 트리는 사람들이 통계적 확률을 나타내거나 발생 과정, 조치 또는 결과를 찾는 데 사용하는 다이어그램과 같습니다. 의사 결정 트리 예제를 통해 개념을 더 명확하게 이해할 수 있습니다.
의사 결정 트리 다이어그램의 분기는 가능한 결과, 가능한 결정 또는 반응을 보여줍니다. 의사 결정 트리의 끝에 있는 분기는 예측 또는 결과를 표시합니다. 의사 결정 트리는 일반적으로 수동으로 해결하기가 복잡해지는 문제에 대한 솔루션을 찾는 데 사용됩니다. 몇 가지 의사 결정 트리 예제를 통해 이를 자세히 이해해 보겠습니다.
의사 결정 트리는 데이터 또는 이벤트의 예측 및 분류에 사용되는 널리 사용되는 강력한 도구 중 하나입니다. 순서도와 비슷하지만 트리 구조를 가지고 있습니다. 트리의 내부 노드는 속성에 대한 테스트 또는 질문을 나타냅니다. 각 분기는 질문의 가능한 결과이며 리프 노드라고도 하는 터미널 노드는 클래스 레이블을 나타냅니다.
의사 결정 트리에는 여러 예측 변수가 있습니다. 이러한 예측 변수에 따라 소위 응답 변수를 예측하려고 합니다.
관련 읽기: 의사 결정 트리 분류: 알아야 할 모든 것
ML의 의사 결정 트리
몇 가지 단계를 시퀀스 형태로 표현함으로써 의사 결정 트리는 가능한 의사 결정 옵션과 범위의 잠재적 결과를 이해하고 시각화하는 쉽고 효과적인 방법이 됩니다. 의사 결정 트리는 또한 가능한 옵션을 식별하고 얻을 수 있는 각 작업 과정에 대한 보상과 위험을 평가하는 데 도움이 됩니다.

의사 결정 트리는 의사 결정을 지원하는 일종의 지원 시스템으로 대규모 조직뿐만 아니라 많은 소규모 조직에 배포됩니다. 의사결정 트리의 예 는 구조화된 모델 이기 때문에 독자는 차트를 이해하고 특정 옵션이 해당 결정으로 이어질 수 있는 방법과 이유를 분석할 수 있습니다. 또한 의사 결정 트리 예제 를 통해 독자는 단일 문제에 대해 가능한 여러 솔루션을 예측하고 얻을 수 있으며 형식 및 의사 결정과 다른 이벤트 및 데이터 간의 관계를 이해할 수 있습니다.
트리의 각 결과에는 보상과 위험 번호 또는 가중치가 할당됩니다. 의사 결정 트리를 사용한 적이 있다면 가능한 단점과 이점이 있는 모든 최종 결과를 얻게 될 것입니다. 트리를 적절하게 결론짓기 위해 이벤트와 데이터 양에 따라 필요한 만큼 짧게 또는 길게 확장할 수 있습니다. 더 잘 이해하기 위해 간단한 의사 결정 트리 예 를 들어 보겠습니다.
음주, 흡연 여부, 체중, 사망한 연령과 같은 사람들의 세부 정보로 구성된 주어진 데이터를 고려하십시오.
| 이름 | 술꾼 | 흡연자 | 무게 | 나이(사망) |
| 샘 | 네 | 네 | 120 | 44 |
| 메리 | 아니요 | 아니요 | 70 | 96 |
| 조나스 | 네 | 아니요 | 72 | 88 |
| 테일러 | 네 | 네 | 55 | 52 |
| 조 | 아니요 | 네 | 94 | 56 |
| 괴롭히다 | 아니요 | 아니요 | 62 | 93 |
사람들이 더 어린 나이에 죽을지 아니면 더 나이가 들면 죽을지 예측해 봅시다. 음주자, 흡연자, 체중과 같은 특성이 예측 변수로 작용합니다. 이것을 사용하여 우리는 나이를 응답 변수로 고려할 것입니다.
70세 이전에 사망한 사람은 "젊음"으로 사망하고 70세 이후에 사망한 사람은 "노인"으로 사망했다고 표시합시다. 이제 예측 변수를 기반으로 응답 변수를 예측해 보겠습니다. 다음은 데이터를 학습한 후 만들어진 의사결정 트리입니다.
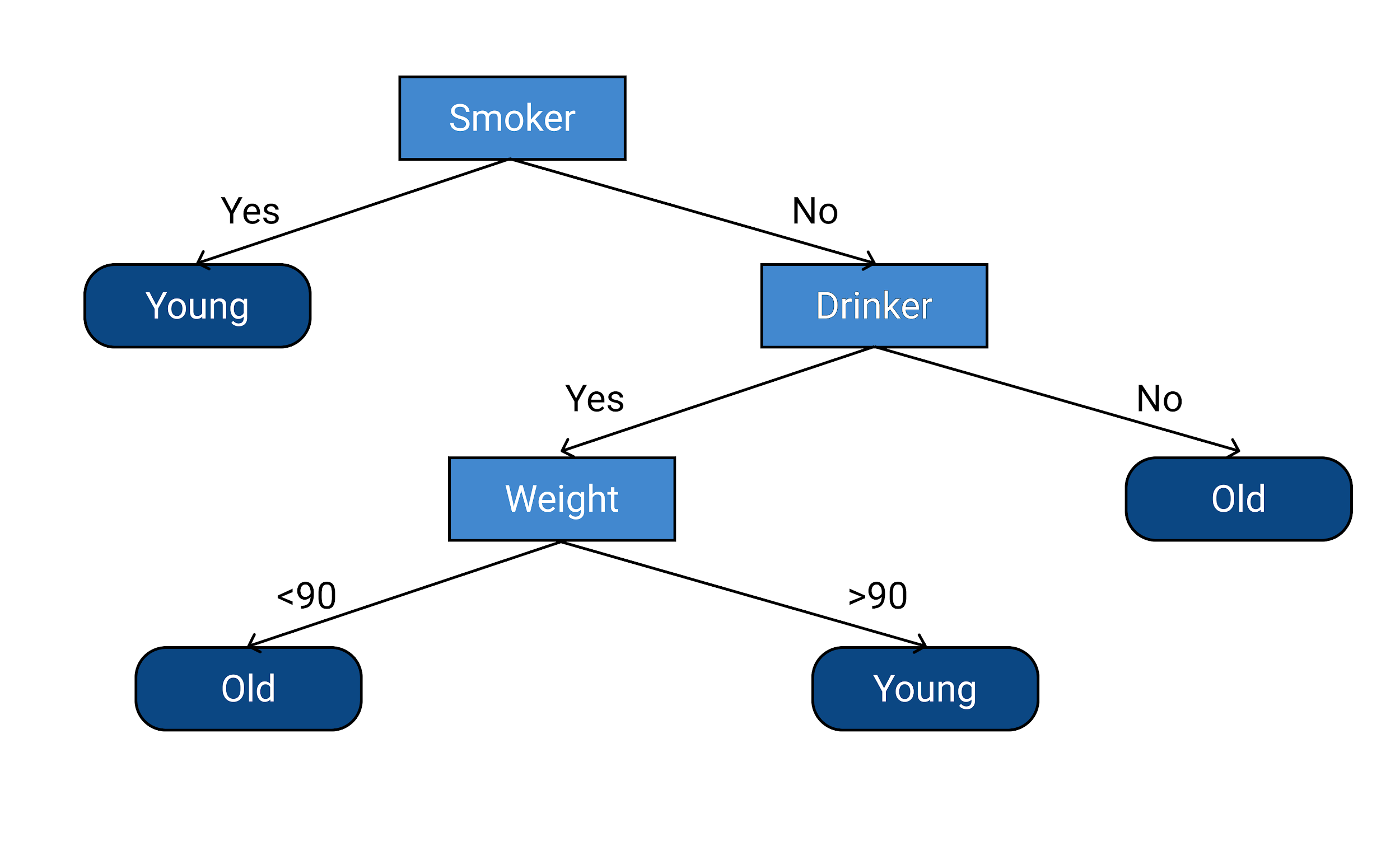
위의 의사결정나무는 흡연자인 경우 일찍 죽는다고 설명합니다. 사람이 흡연자가 아닌 경우 고려되는 다음 요소는 그 사람이 음주자인지 여부입니다. 담배를 피우지 않고 술을 마시지 않는 사람은 늙어 죽는다.
사람이 흡연자가 아니고 술꾼이면 사람의 체중이 고려됩니다. 사람이 흡연자가 아니고 음주자이며 체중이 90kg 미만이면 노인으로 사망합니다. 그리고 마지막으로 비흡연자, 음주자, 체중 90kg 이상인 사람은 젊어서 죽는다.
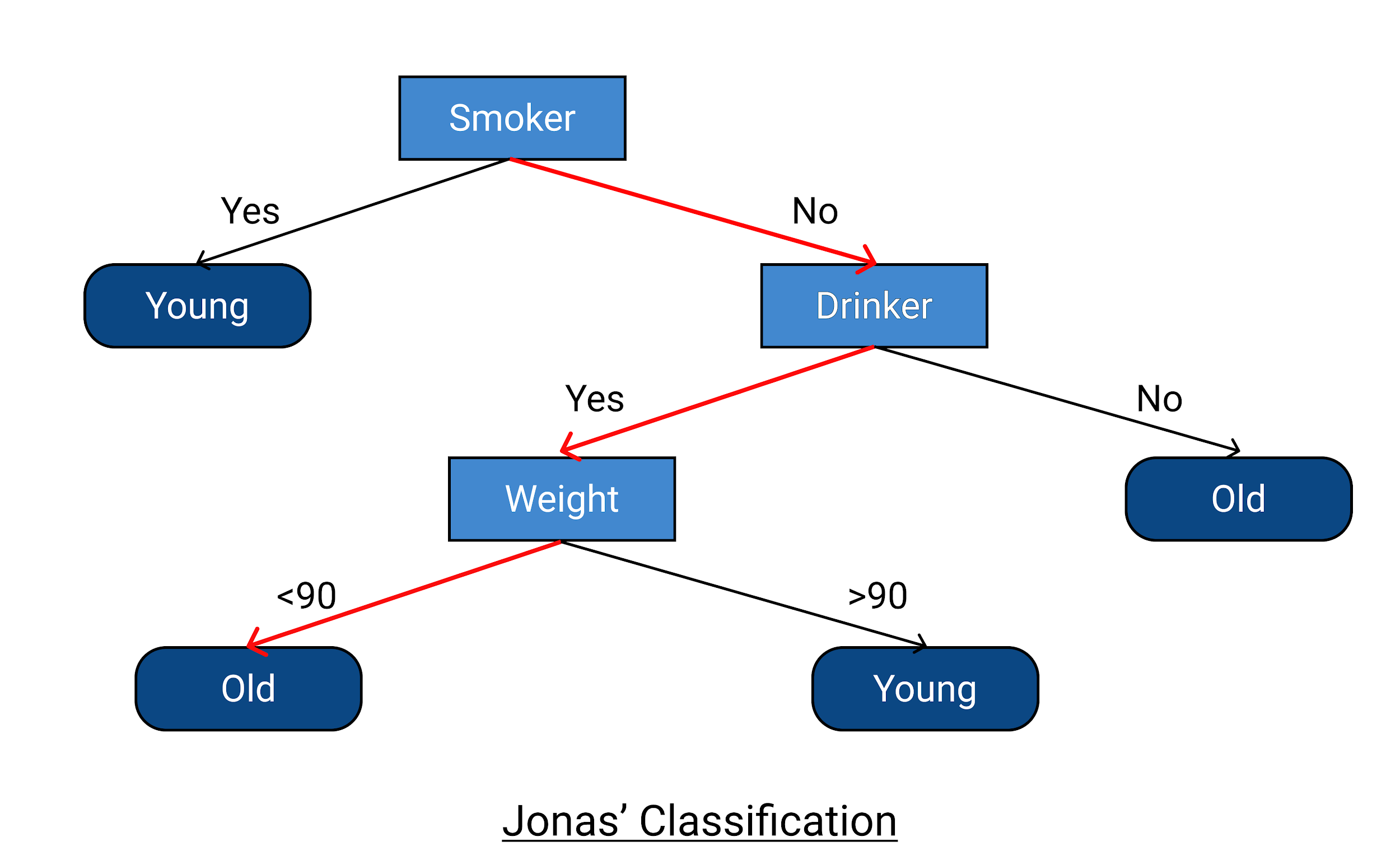
주어진 데이터에서 Jonas의 예를 들어 결정 트리가 올바르게 분류되고 응답 변수를 올바르게 예측하는지 확인하겠습니다. Jonas는 흡연자가 아니며 음주자이며 체중이 90kg 미만입니다. 의사 결정 트리에 따르면 그는 늙어 죽을 것입니다(죽는 나이> 70). 또한 데이터에 따르면 그는 88세에 사망했습니다. 이는 의사결정 트리 예제 가 올바르게 분류되고 완벽하게 작동했음을 의미합니다.
그러나 의사 결정 트리의 작동 이면에 있는 기본 아이디어에 대해 궁금한 적이 있습니까? 의사 결정 트리에서 인스턴스 집합은 각 하위 집합의 변동이 작아지는 방식으로 하위 집합으로 분할됩니다. 즉, 엔트로피를 줄이고자 하므로 변동을 줄이고 사건이나 사례를 순수하게 만들려고 합니다.
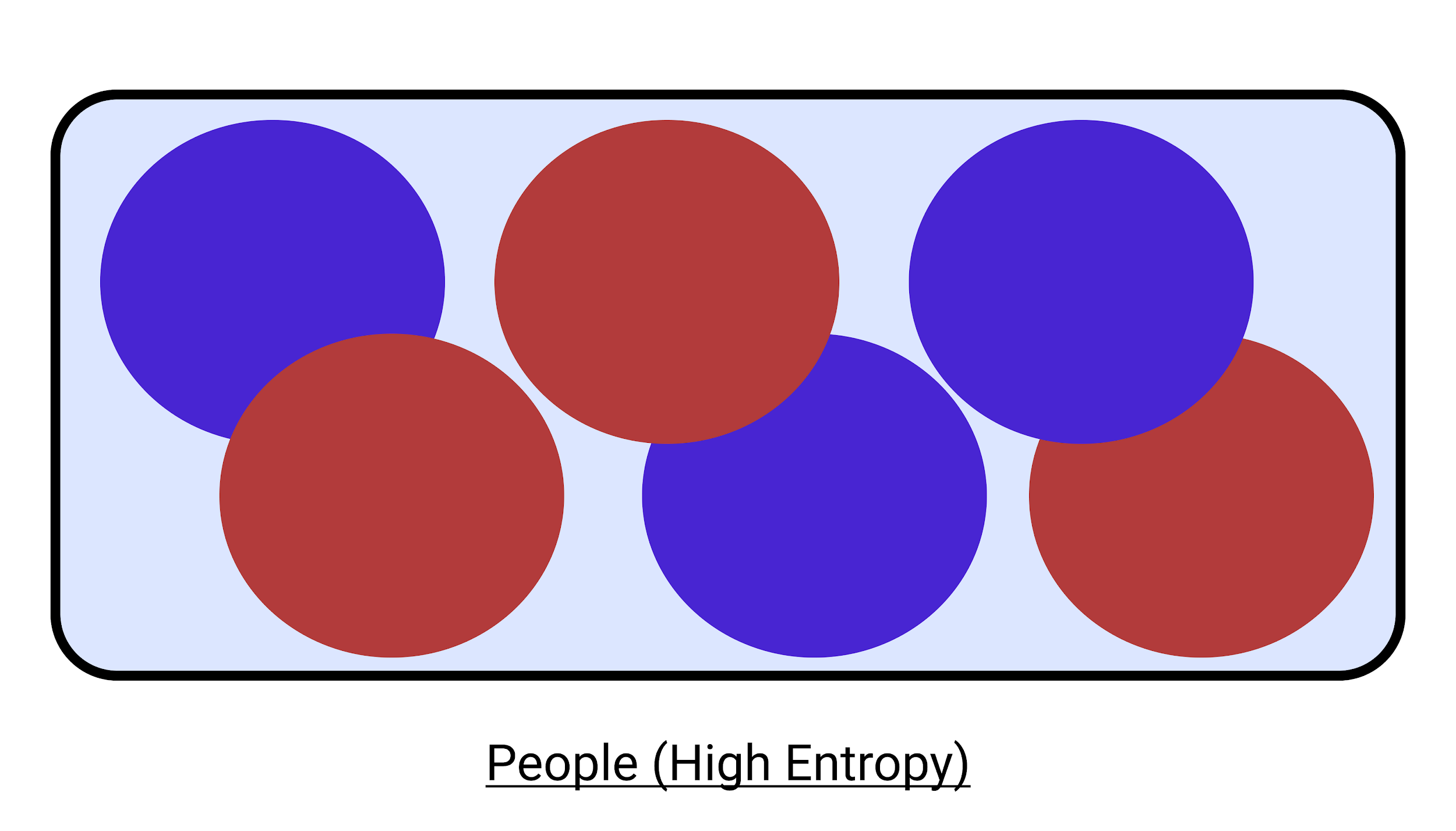
유사한 의사 결정 트리 예를 살펴보겠습니다 . 먼저 그 사람이 흡연자인지 여부를 고려합니다.

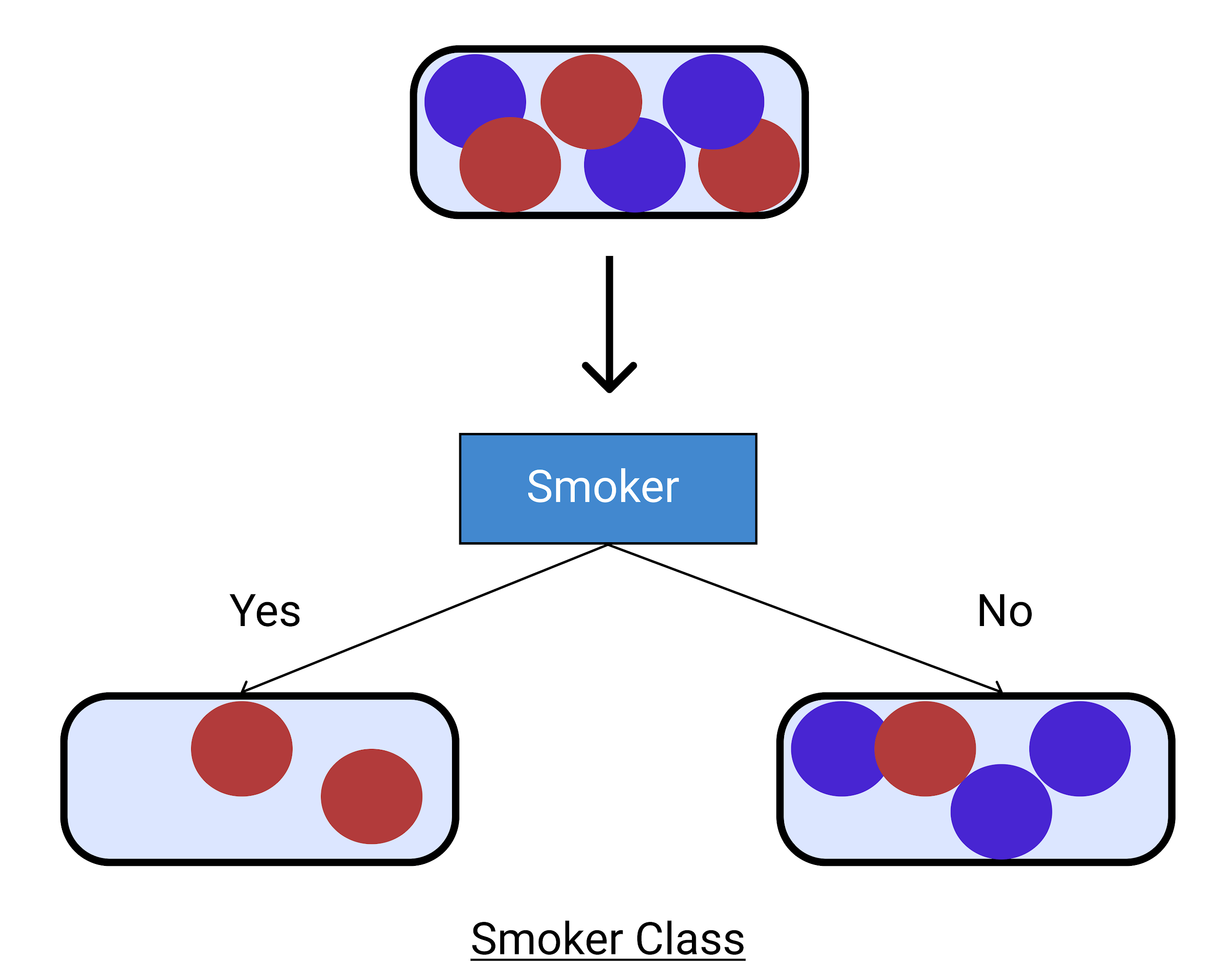
여기서 우리는 비흡연자에 대해 불확실합니다. 그래서 우리는 그것을 음주자와 비음주자로 나눕니다.
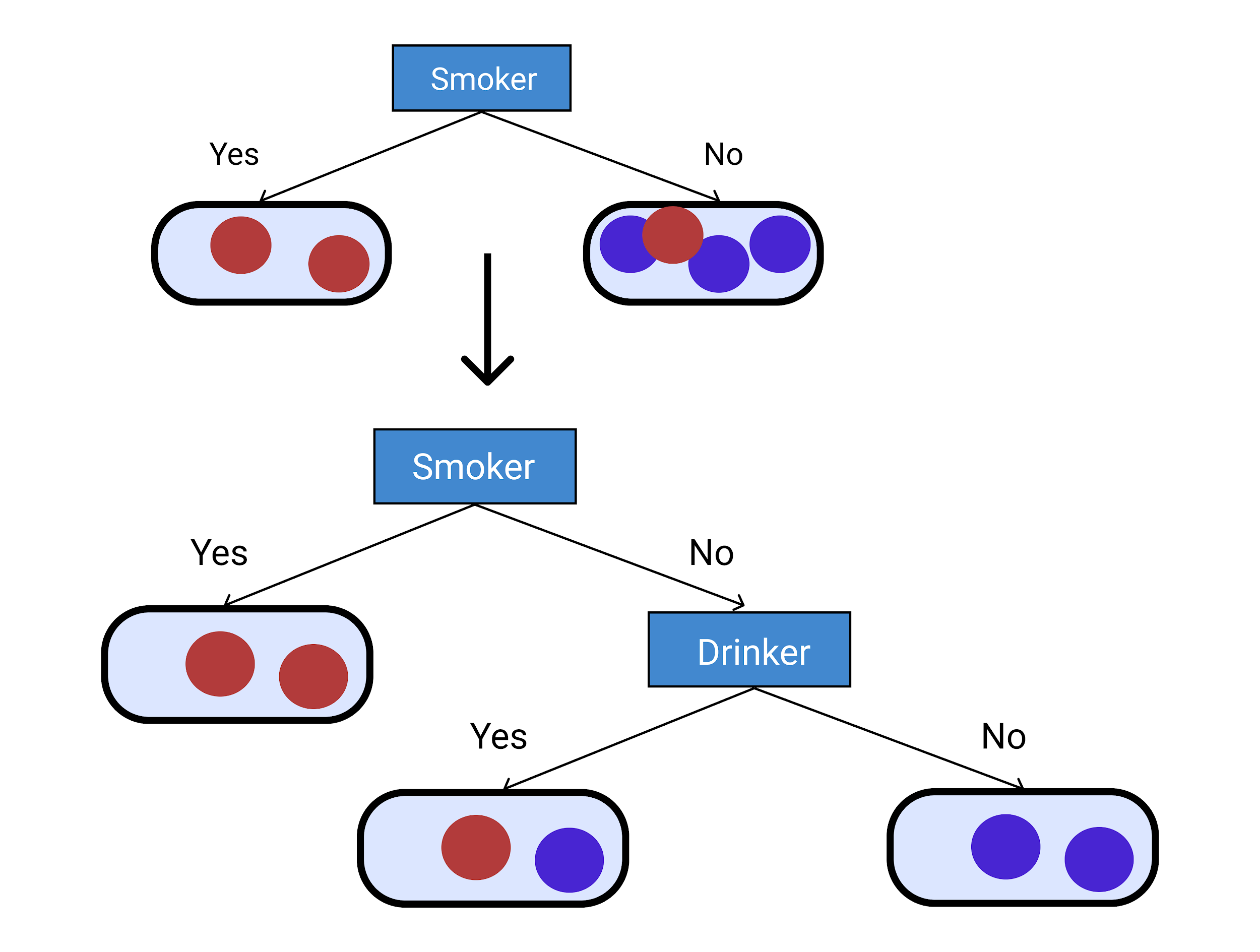
우리는 아래에 주어진 다이어그램에서 큰 변동을 갖는 높은 엔트로피에서 우리가 더 확신할 수 있는 더 작은 클래스로 감소시켰음을 알 수 있습니다. 이러한 방식으로 의사 결정 트리 예제 를 점진적으로 구축할 수 있습니다 .
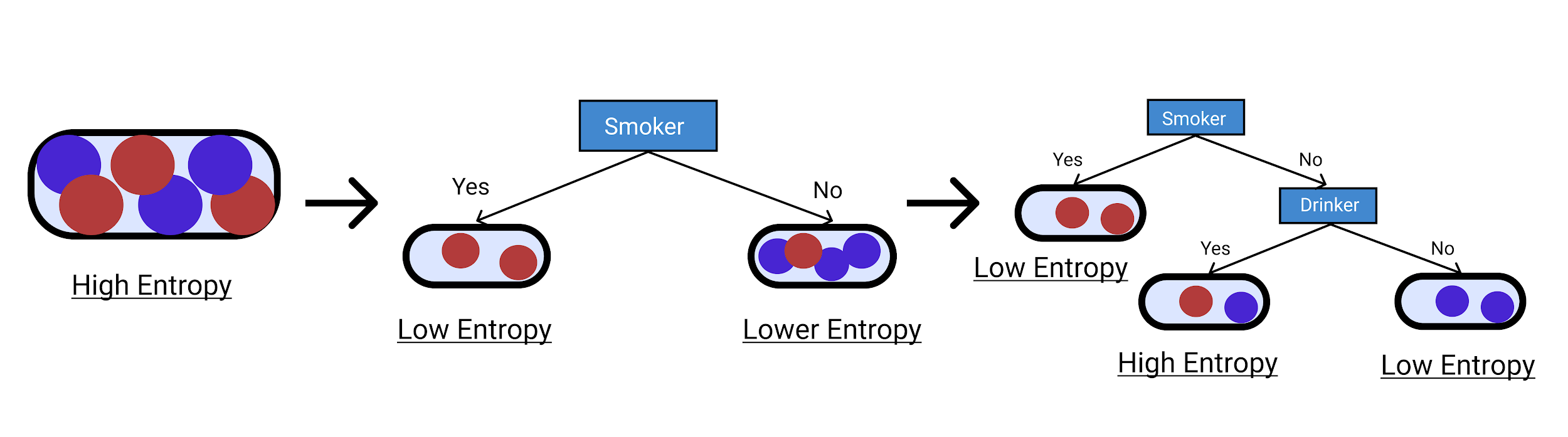
ID3 알고리즘을 사용하여 의사 결정 트리를 구성해 보겠습니다. 의사 결정 트리에서 더 중요한 것은 엔트로피에 대한 강한 이해입니다. 엔트로피는 불확실성의 정도일 뿐입니다. 그것은 다음과 같이 주어진다:
![]()
(때때로 "E"로 표시되기도 함)
위의 예에 적용하면 다음과 같이 됩니다.
어떤 범주로 분류된 사람이 없는 경우를 생각해 보십시오. 두 유형의 사람들이 같은 양을 가질 때 최악의 시나리오(높은 엔트로피)입니다. 여기서 비율은 3:3입니다.
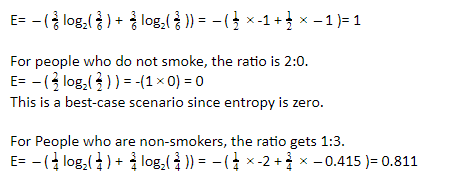
마찬가지로 술을 마시지 않는 사람의 비율은 1:1이고 엔트로피는 1이 됩니다. 따라서 불확실성으로 인해 추가 분할이 필요합니다. 술을 마시지 않는 사람의 비율은 2:0입니다. 따라서 엔트로피는 0입니다.
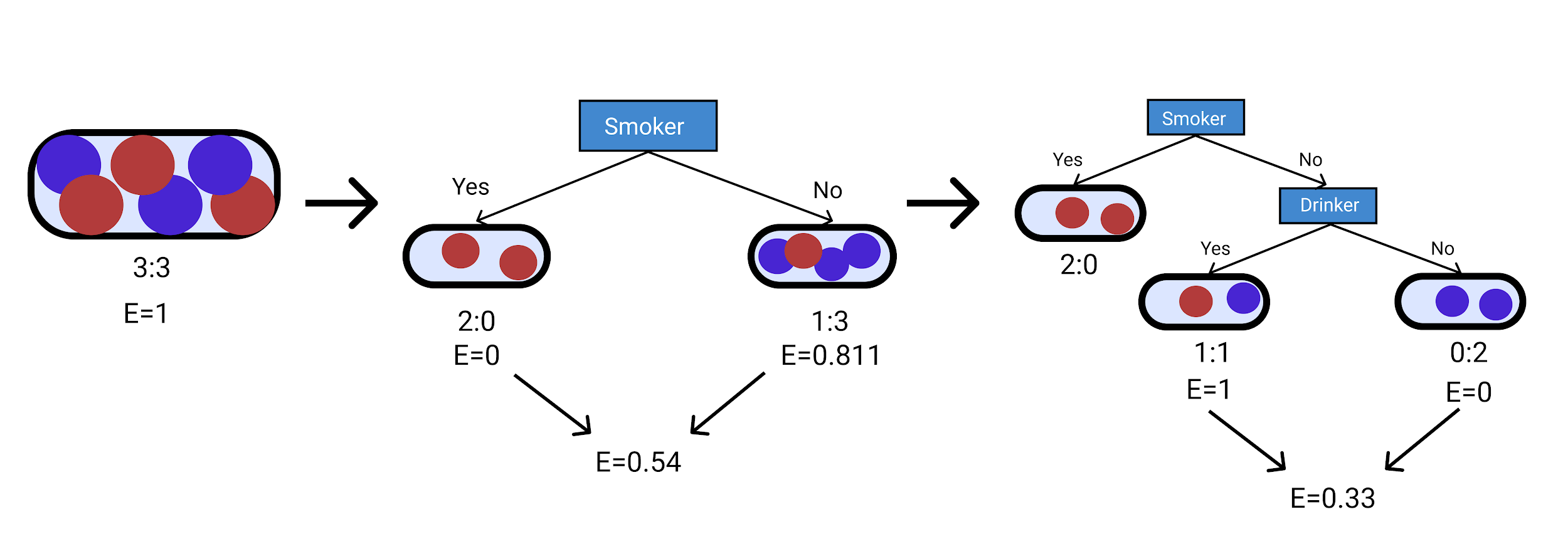
이제 서로 다른 경우에 대한 엔트로피를 계산했으므로 동일한 경우에 대한 가중 평균을 계산할 수 있습니다.
첫 번째 분기의 경우 E= 6 6 1=1
흡연자 등급의 경우 E= 2 6 0+ 4 6 0.811=0.54
흡연자 및 음주자 등급의 경우 E= 2 6 0+ 2 6 1+ 2 6 0=0.33
아래 다이어그램은 위의 계산을 빠르게 이해하는 데 도움이 됩니다.
마지막으로 정보 이득:
| 수업 | 엔트로피 | 정보 획득(E2-E1) |
| 사람들 | 1 | 0.46 |
| 흡연자 | 0.54 | 0.21 |
| 흡연자+음주자 | 0.33 | – |
더 읽어보기: 의사결정나무 인터뷰 질문 및 답변
결론
우리는 이론에서 실제 의사 결정 트리 예제 에 이르기까지 의사 결정 트리를 깊이 있게 성공적으로 연구했습니다 . 또한 ID3 알고리즘을 사용하여 의사 결정 트리를 구성했습니다. 이것이 흥미롭다면 데이터 과학을 자세히 탐구하고 싶을 것입니다.
의사 결정 트리, 기계 학습에 대해 자세히 알아보려면 작업 전문가를 위해 설계되었으며 450시간 이상의 엄격한 교육, 30개 이상의 사례 연구 및 과제를 제공하는 IIIT-B & upGrad의 기계 학습 및 AI PG 디플로마를 확인하십시오. , IIIT-B 동문 자격, 5개 이상의 실용적인 실습 캡스톤 프로젝트 및 최고의 기업과의 취업 지원.
의사결정나무란?
의사 결정 트리는 의사 결정 정보를 시각적으로 구성하고 구성하는 데 사용됩니다. 나무는 뿌리가 위쪽에 있고 잎이 아래쪽에 있도록 그려집니다. 결정 트리는 왼쪽에서 오른쪽으로 아래에서 위로 읽습니다. 트리의 각 수준은 추가 테스트를 위한 기반이며 각 수준의 결정은 질문에 대한 답변이 나올 때까지 범위를 좁힐 것입니다. 의사 결정 트리는 문제 또는 결정을 여러 하위 결정으로 나누고 기본 목표인 루트에 대한 논리적 경로를 따릅니다. 의사 결정 트리는 비즈니스 환경을 분석하고 우선 순위를 지정하고 통찰력을 제공하여 어떤 방향으로 가야 할지 결정하는 데 사용됩니다.
머신 러닝에서 의사 결정 트리 학습의 문제는 무엇입니까?
의사결정나무는 새로운 전략을 테스트하거나 다른 사람에게 전략을 설명하기 위한 기초로 사용할 수 있습니다. 의사 결정 트리는 주어진 가정 하에서 어떤 일이 일어날지 설명합니다. 또한 과거에 사용된 전략의 성과를 평가하는 데 사용할 수도 있습니다. 의사 결정 트리는 모든 분기로 인해 오류에 너무 취약한 것으로 알려져 있습니다. 의사 결정 트리가 항상 정확한 것은 아닙니다. 때로는 모든 가능한 변수를 고려하지 않고 의사 결정 트리를 분석하는 사람이 특정 상황의 모든 측면에서 경험하지 못할 수도 있기 때문입니다.
어떤 종류의 데이터가 의사결정나무에 가장 적합합니까?
의사 결정 트리는 구조와 같은 순서도를 사용하여 데이터에서 패턴을 찾는 데 도움이 됩니다. 가장 좋은 유형의 데이터는 정성적, 범주적 및 수치적입니다. 의사결정나무는 모든 유형의 데이터에서 작동하지만 숫자 데이터에서 가장 잘 작동합니다. 숫자 값을 가질 수 있거나 숫자로 변환하는 방법이 있어야 합니다. 의사 결정 트리는 데이터 유형과 수량에 크게 의존합니다. 데이터 포인트 수가 100개 이상이면 의사결정나무가 좋은 모델이 됩니다.