
6 особенностей Apache Spark, которые изменят правила игры в 2022 году [как использовать]
Опубликовано: 2021-01-07С тех пор, как большие данные штурмом захватили мир технологий и бизнеса, произошел огромный рост инструментов и платформ больших данных, особенно Apache Hadoop и Apache Spark. Сегодня мы сосредоточимся исключительно на Apache Spark и подробно обсудим его бизнес-преимущества и приложения.
Apache Spark стал известен в 2009 году и с тех пор постепенно занял свою нишу в отрасли. Согласно Apache org., Spark — это «молниеносный унифицированный аналитический механизм», предназначенный для обработки колоссальных объемов больших данных. Благодаря активному сообществу сегодня Spark является одной из крупнейших в мире платформ больших данных с открытым исходным кодом.
Оглавление
Что такое Apache Spark?
Первоначально разработанный в AMPLab Калифорнийского университета (Беркли), Spark был разработан как надежный механизм обработки данных Hadoop с особым акцентом на скорость и простоту использования. Это альтернатива MapReduce от Hadoop с открытым исходным кодом. По сути, Spark — это инфраструктура параллельной обработки данных, которая может взаимодействовать с Apache Hadoop для облегчения плавной и быстрой разработки сложных приложений для работы с большими данными в Hadoop.
Spark поставляется с широким набором библиотек для алгоритмов машинного обучения (ML) и графовых алгоритмов. Мало того, он также поддерживает потоковую передачу в реальном времени и приложения SQL через Spark Streaming и Shark соответственно. Самое приятное в использовании Spark заключается в том, что вы можете писать приложения Spark на Java, Scala или даже Python, и эти приложения будут работать почти в десять раз быстрее (на диске) и в 100 раз быстрее (в памяти), чем приложения MapReduce.
Apache Spark довольно универсален, поскольку его можно развернуть разными способами, а также он предлагает собственные привязки для языков программирования Java, Scala, Python и R. Он поддерживает SQL, обработку графов, потоковую передачу данных и машинное обучение. Вот почему Spark широко используется в различных секторах отрасли, включая банки, телекоммуникационные компании, фирмы по разработке игр, государственные учреждения и, конечно же, во всех ведущих компаниях технологического мира — Apple, Facebook, IBM и Microsoft.
6 лучших функций Apache Spark
Особенности, которые делают Spark одной из наиболее широко используемых платформ больших данных:

1. Молниеносная скорость обработки
Обработка больших данных — это обработка больших объемов сложных данных. Следовательно, когда дело доходит до обработки больших данных, организациям и предприятиям нужны такие платформы, которые могут обрабатывать огромные объемы данных с высокой скоростью. Как мы упоминали ранее, приложения Spark могут работать в 100 раз быстрее в памяти и в 10 раз быстрее на диске в кластерах Hadoop.
Он основан на отказоустойчивом распределенном наборе данных (RDD), который позволяет Spark прозрачно хранить данные в памяти и считывать/записывать их на диск только при необходимости. Это помогает сократить большую часть времени чтения и записи диска во время обработки данных.
2. Простота использования
Spark позволяет писать масштабируемые приложения на Java, Scala, Python и R. Таким образом, разработчики получают возможность создавать и запускать приложения Spark на предпочитаемых ими языках программирования. Более того, Spark оснащен встроенным набором из более чем 80 высокоуровневых операторов. Вы можете использовать Spark в интерактивном режиме для запроса данных из оболочек Scala, Python, R и SQL.
3. Он предлагает поддержку сложной аналитики
Spark поддерживает не только простые операции «карты» и «уменьшения», но также поддерживает SQL-запросы, потоковую передачу данных и расширенную аналитику, включая алгоритмы машинного обучения и графов. Он поставляется с мощным стеком библиотек, таких как SQL & DataFrames и MLlib (для машинного обучения), GraphX и Spark Streaming. Удивительно то, что Spark позволяет объединить возможности всех этих библиотек в одном рабочем процессе/приложении.
4. Обработка потоков в реальном времени
Spark предназначен для обработки потоковой передачи данных в реальном времени. В то время как MapReduce создан для обработки данных, которые уже хранятся в кластерах Hadoop, Spark может делать и то, и другое, а также управлять данными в режиме реального времени с помощью Spark Streaming.
В отличие от других потоковых решений, Spark Streaming может восстанавливать потерянную работу и предоставлять точную семантику «из коробки», не требуя дополнительного кода или настройки. Кроме того, он также позволяет повторно использовать один и тот же код для пакетной и потоковой обработки и даже для объединения потоковых данных с историческими данными.
5. Он гибкий
Spark может работать независимо в кластерном режиме, а также на Hadoop YARN, Apache Mesos, Kubernetes и даже в облаке. Кроме того, он может получить доступ к различным источникам данных. Например, Spark может работать в менеджере кластера YARN и считывать любые существующие данные Hadoop. Он может считывать данные из любых источников данных Hadoop, таких как HBase, HDFS, Hive и Cassandra. Этот аспект Spark делает его идеальным инструментом для переноса чистых приложений Hadoop, при условии, что вариант использования приложения совместим со Spark.
6. Активное и расширяющееся сообщество
Разработчики из более чем 300 компаний участвовали в разработке и создании Apache Spark. С 2009 года более 1200 разработчиков внесли активный вклад в то, чтобы сделать Spark тем, чем он является сегодня! Естественно, Spark поддерживается активным сообществом разработчиков, которые постоянно работают над улучшением его функций и производительности. Чтобы связаться с сообществом Spark, вы можете использовать списки рассылки для любых запросов, а также посещать группы встреч и конференции Spark.
Анатомия приложений Spark
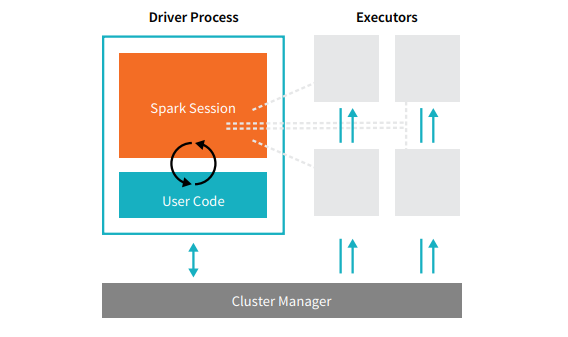
Каждое приложение Spark состоит из двух основных процессов — основного процесса- драйвера и набора процессов- исполнителей .
Источник
Процесс драйвера, который находится на узле в кластере, отвечает за выполнение функции main(). Он также выполняет три другие задачи: хранение информации о приложении Spark, реагирование на пользовательский код или ввод, а также анализ, распределение и планирование работы между исполнителями. Процесс драйвера образует сердце приложения Spark — он содержит и поддерживает всю важную информацию, охватывающую жизненный цикл приложения Spark.

Исполнители или процессы -исполнители — это второстепенные элементы, которые должны выполнять задачу, назначенную им драйвером. По сути, каждый исполнитель выполняет две важные функции — запускает код, назначенный ему драйвером, и сообщает о состоянии вычислений (на этом исполнителе) узлу драйвера. Пользователи могут решить и настроить, сколько исполнителей должно быть на каждом узле.
В приложении Spark менеджер кластера контролирует все машины и выделяет ресурсы приложению. Здесь менеджером кластера может быть любой из основных менеджеров кластера Spark, включая YARN (автономный менеджер кластера Spark) или Mesos. Это означает, что кластер может одновременно запускать несколько приложений Spark.
Реальные приложения Apache Spark
Spark — это популярная и широко используемая платформа Big Dara в современной индустрии. Некоторые из наиболее известных реальных примеров приложений Apache Spark:
Искра для машинного обучения
Apache Spark может похвастаться масштабируемой библиотекой машинного обучения — MLlib. Эта библиотека специально разработана для простоты, масштабируемости и облегчения интеграции с другими инструментами. MLlib не только обладает масштабируемостью, языковой совместимостью и скоростью Spark, но также может выполнять множество расширенных аналитических задач, таких как классификация, кластеризация, уменьшение размерности. Благодаря MLlib Spark можно использовать для прогнозного анализа, анализа настроений, сегментации клиентов и прогнозной аналитики.
Еще одна впечатляющая функция Apache Spark связана с сетевой безопасностью. Spark Streaming позволяет пользователям отслеживать пакеты данных в режиме реального времени, прежде чем отправлять их в хранилище. В ходе этого процесса он может успешно выявлять любые подозрительные или вредоносные действия, происходящие из известных источников угроз. Даже после отправки пакетов данных в хранилище Spark использует MLlib для дальнейшего анализа данных и выявления потенциальных рисков для сети. Эту функцию также можно использовать для обнаружения мошенничества и событий.
Spark для туманных вычислений
Apache Spark — отличный инструмент для туманных вычислений, особенно когда речь идет об Интернете вещей (IoT). Интернет вещей в значительной степени опирается на концепцию крупномасштабной параллельной обработки. Поскольку сеть IoT состоит из тысяч и миллионов подключенных устройств, данные, генерируемые этой сетью каждую секунду, не поддаются пониманию.
Естественно, для обработки таких больших объемов данных, создаваемых IoT-устройствами, требуется масштабируемая платформа, поддерживающая параллельную обработку. И что может быть лучше, чем надежная архитектура Spark и возможности туманных вычислений для обработки таких огромных объемов данных!
Туманные вычисления децентрализуют данные и хранилище, и вместо использования облачной обработки они выполняют функцию обработки данных на границе сети (в основном встроенной в устройства IoT).
Для этого туманным вычислениям требуются три возможности, а именно низкая задержка, параллельная обработка ML и сложные алгоритмы графовой аналитики — каждая из которых присутствует в Spark. Кроме того, наличие Spark Streaming, Shark (интерактивный инструмент запросов, который может работать в режиме реального времени), MLlib и GraphX (механизм анализа графов) еще больше расширяет возможности Spark для туманных вычислений.
Spark для интерактивного анализа
В отличие от MapReduce, Hive или Pig, которые имеют относительно низкую скорость обработки, Spark может похвастаться высокоскоростной интерактивной аналитикой. Он способен обрабатывать исследовательские запросы, не требуя выборки данных. Кроме того, Spark совместим практически со всеми популярными языками разработки, включая R, Python, SQL, Java и Scala.
В последней версии Spark — Spark 2.0 — появилась новая функция, известная как структурированная потоковая передача. С помощью этой функции пользователи могут выполнять структурированные и интерактивные запросы к потоковым данным в режиме реального времени.
Пользователи искры
Теперь, когда вы хорошо знакомы с функциями и возможностями Spark, давайте поговорим о четырех выдающихся пользователях Spark!
1. Яху
Yahoo использует Spark для двух своих проектов: один для персонализации новостных страниц для посетителей, а другой — для аналитики рекламы. Для настройки новостных страниц Yahoo использует передовые алгоритмы машинного обучения, работающие в Spark, чтобы понять интересы, предпочтения и потребности отдельных пользователей и соответствующим образом классифицировать истории.
Во втором случае Yahoo использует интерактивные возможности Hive on Spark (для интеграции с любым инструментом, подключаемым к Hive) для просмотра и запроса рекламных аналитических данных Yahoo, собранных на Hadoop.
2. Убер
Uber использует Spark Streaming в сочетании с Kafka и HDFS для ETL (извлечение, преобразование и загрузка) огромных объемов данных дискретных событий в реальном времени в структурированные и пригодные для дальнейшего анализа данные. Эти данные помогают Uber разрабатывать улучшенные решения для клиентов.

3. Конвива
Как компания, занимающаяся потоковым видео, Conviva ежемесячно получает в среднем более 4 миллионов видеопотоков, что приводит к массовому оттоку клиентов. Эта проблема еще более усугубляется проблемой управления видеотрафиком в режиме реального времени. Чтобы эффективно бороться с этими проблемами, Conviva использует Spark Streaming для изучения состояния сети в режиме реального времени и соответствующей оптимизации видеотрафика. Это позволяет Conviva обеспечивать стабильно высокое качество просмотра для пользователей.
4. Пинтерест
На Pinterest пользователи могут прикреплять свои любимые темы, когда им заблагорассудится, во время просмотра веб-страниц и социальных сетей. Чтобы предложить персонализированный и расширенный опыт работы с клиентами, Pinterest использует возможности Spark ETL для определения уникальных потребностей и интересов отдельных пользователей и предоставления им соответствующих рекомендаций в Pinterest.
Заключение
В заключение можно сказать, что Spark — это чрезвычайно универсальная платформа для работы с большими данными, функции которой созданы для того, чтобы впечатлять. Поскольку это платформа с открытым исходным кодом, она постоянно совершенствуется и развивается, в нее добавляются новые функции и функции. По мере того, как приложения больших данных становятся все более разнообразными и обширными, будут расширяться и варианты использования Apache Spark.
Если вам интересно узнать больше о больших данных, ознакомьтесь с нашей программой PG Diploma в области разработки программного обеспечения со специализацией в области больших данных, которая предназначена для работающих профессионалов и включает более 7 тематических исследований и проектов, охватывает 14 языков и инструментов программирования, практические занятия. семинары, более 400 часов интенсивного обучения и помощь в трудоустройстве в ведущих фирмах.
Ознакомьтесь с другими нашими курсами по программной инженерии на upGrad.