
2022'de Apache Spark'ın Oyunu Değiştiren 6 Özelliği [Nasıl Kullanmalısınız]
Yayınlanan: 2021-01-07Büyük Veri, teknoloji ve iş dünyalarını kasıp kavurduğundan beri, özellikle Apache Hadoop ve Apache Spark olmak üzere Büyük Veri araçları ve platformlarında muazzam bir artış oldu. Bugün, yalnızca Apache Spark'a odaklanacağız ve ticari faydaları ve uygulamaları hakkında uzun uzun tartışacağız.
Apache Spark, 2009'da ilgi odağı oldu ve o zamandan beri yavaş yavaş endüstride kendine bir yer edindi. Apache org.'a göre Spark, devasa miktarda Büyük Veriyi işlemek için tasarlanmış "yıldırım hızında birleşik bir analitik motorudur". Aktif bir topluluk sayesinde bugün Spark, dünyanın en büyük açık kaynaklı Büyük Veri platformlarından biridir.
İçindekiler
Apache Spark nedir?
Aslen California Üniversitesi'nin (Berkeley) AMPLab'ında geliştirilen Spark, hız ve kullanım kolaylığına özel olarak odaklanılarak Hadoop verileri için sağlam bir işleme motoru olarak tasarlanmıştır. Hadoop'un MapReduce'una açık kaynaklı bir alternatiftir. Temel olarak Spark, Hadoop'ta gelişmiş Büyük Veri uygulamalarının sorunsuz ve hızlı bir şekilde geliştirilmesini kolaylaştırmak için Apache Hadoop ile işbirliği yapabilen paralel bir veri işleme çerçevesidir.
Spark, Machine Learning (ML) algoritmaları ve grafik algoritmaları için çok çeşitli kitaplıklar ile birlikte gelir. Sadece bu değil, aynı zamanda sırasıyla Spark Streaming ve Shark aracılığıyla gerçek zamanlı akış ve SQL uygulamalarını da destekler. Spark kullanmanın en iyi yanı, Spark uygulamalarını Java, Scala ve hatta Python'da yazabilmenizdir ve bu uygulamalar MapReduce uygulamalarından neredeyse on kat (diskte) ve 100 kat (bellekte) daha hızlı çalışır.
Apache Spark, birçok şekilde dağıtılabildiğinden oldukça çok yönlüdür ve ayrıca Java, Scala, Python ve R programlama dilleri için yerel bağlamalar sunar. SQL, grafik işleme, veri akışı ve Makine Öğrenimi'ni destekler. Spark'ın bankalar, telekomünikasyon şirketleri, oyun geliştirme şirketleri, devlet kurumları ve tabii ki teknoloji dünyasının tüm önde gelen şirketlerinde - Apple, Facebook, IBM ve Microsoft dahil olmak üzere endüstrinin çeşitli sektörlerinde yaygın olarak kullanılmasının nedeni budur.
Apache Spark'ın En İyi 6 Özelliği
Spark'ı en yaygın kullanılan Büyük Veri platformlarından biri yapan özellikler şunlardır:

1. Aydınlatma hızında işlem hızı
Büyük Veri işleme, büyük hacimli karmaşık verilerin işlenmesiyle ilgilidir. Bu nedenle, Büyük Veri işleme söz konusu olduğunda, kuruluşlar ve kuruluşlar, büyük miktarda veriyi yüksek hızda işleyebilen bu tür çerçeveler ister. Daha önce de belirttiğimiz gibi, Spark uygulamaları Hadoop kümelerinde bellekte 100 kata kadar ve diskte 10 kata kadar daha hızlı çalışabilir.
Spark'ın verileri şeffaf bir şekilde bellekte depolamasına ve yalnızca gerektiğinde diske okumasına/yazmasına olanak tanıyan Esnek Dağıtılmış Veri Kümesine (RDD) dayanır. Bu, veri işleme sırasında disk okuma ve yazma süresinin çoğunu azaltmaya yardımcı olur.
2. Kullanım kolaylığı
Spark, Java, Scala, Python ve R'de ölçeklenebilir uygulamalar yazmanıza olanak tanır. Böylece geliştiriciler, Spark uygulamalarını tercih ettikleri programlama dillerinde oluşturma ve çalıştırma kapsamına sahip olurlar. Ayrıca Spark, 80'den fazla üst düzey operatörden oluşan yerleşik bir setle donatılmıştır. Scala, Python, R ve SQL kabuklarından veri sorgulamak için Spark'ı etkileşimli olarak kullanabilirsiniz.
3. Gelişmiş analitik için destek sunar
Spark yalnızca basit "harita" ve "azaltma" işlemlerini desteklemekle kalmaz, aynı zamanda SQL sorgularını, veri akışını ve makine öğrenimi ve grafik algoritmaları dahil olmak üzere gelişmiş analitiği de destekler. SQL & DataFrames ve MLlib (ML için), GraphX ve Spark Streaming gibi güçlü bir kitaplık yığınıyla birlikte gelir. Büyüleyici olan, Spark'ın tüm bu kitaplıkların yeteneklerini tek bir iş akışı/uygulama içinde birleştirmenize izin vermesidir.
4. Gerçek zamanlı akış işleme
Spark, gerçek zamanlı veri akışını işlemek için tasarlanmıştır. MapReduce, Hadoop kümelerinde depolanan verileri işlemek ve işlemek için oluşturulmuş olsa da Spark, Spark Streaming aracılığıyla hem verileri hem de gerçek zamanlı olarak işleyebilir.
Diğer akış çözümlerinden farklı olarak, Spark Streaming, kaybolan işi kurtarabilir ve ek kod veya yapılandırma gerektirmeden tam anlamı kutudan çıkar çıkmaz sunabilir. Ayrıca, aynı kodu toplu ve akış işleme için ve hatta akış verilerini geçmiş verilerle birleştirmek için yeniden kullanmanıza da olanak tanır.
5. Esnektir
Spark, küme modunda bağımsız olarak çalışabilir ve ayrıca Hadoop YARN, Apache Mesos, Kubernetes ve hatta bulutta çalışabilir. Ayrıca, çeşitli veri kaynaklarına erişebilir. Örneğin, Spark, YARN küme yöneticisinde çalışabilir ve mevcut tüm Hadoop verilerini okuyabilir. HBase, HDFS, Hive ve Cassandra gibi herhangi bir Hadoop veri kaynağından okuyabilir. Spark'ın bu yönü, uygulamaların kullanım durumunun Spark dostu olması koşuluyla, saf Hadoop uygulamalarını geçirmek için onu ideal bir araç haline getirir.
6. Aktif ve genişleyen topluluk
300'den fazla şirketten geliştiriciler, Apache Spark'ın tasarlanmasına ve oluşturulmasına katkıda bulundu. 2009'dan beri, 1200'den fazla geliştirici, Spark'ın bugünkü haline gelmesine aktif olarak katkıda bulundu! Doğal olarak Spark, özelliklerini ve performansını sürekli olarak geliştirmek için çalışan aktif bir geliştirici topluluğu tarafından desteklenmektedir. Spark topluluğuna ulaşmak için herhangi bir sorunuz için e- posta listelerinden yararlanabilir ve ayrıca Spark buluşma gruplarına ve konferanslarına katılabilirsiniz.
Spark Uygulamalarının Anatomisi
Her Spark uygulaması, iki temel süreçten oluşur: bir birincil sürücü süreci ve bir yürütücü süreç koleksiyonu .
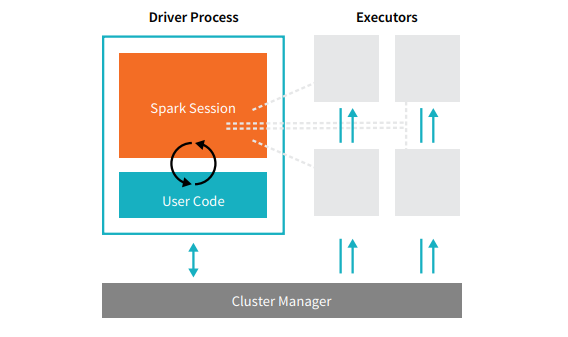
Kaynak
Kümedeki bir düğümde bulunan sürücü işlemi, main() işlevini çalıştırmaktan sorumludur. Ayrıca, Spark Uygulaması hakkındaki bilgileri korumak, bir kullanıcının koduna veya girdisine yanıt vermek ve yürütücüler arasında işi analiz etmek, dağıtmak ve planlamak gibi üç görevi daha yerine getirir. Sürücü süreci, Spark Uygulamasının kalbini oluşturur – Spark uygulamasının kullanım ömrü boyunca tüm kritik bilgileri içerir ve muhafaza eder.

Yürütücüler veya yürütücü işlemler , sürücü tarafından kendilerine atanan görevi yürütmesi gereken ikincil öğelerdir . Temel olarak, her yürütücü iki önemli işlevi yerine getirir - sürücü tarafından kendisine atanan kodu çalıştırın ve hesaplamanın durumunu (o yürütücüde) sürücü düğümüne bildirin. Kullanıcılar, her bir düğümün kaç tane yürütücüsü olması gerektiğine karar verebilir ve yapılandırabilir.
Bir Spark uygulamasında, küme yöneticisi tüm makineleri kontrol eder ve kaynakları uygulamaya tahsis eder. Burada küme yöneticisi, YARN (Spark'ın bağımsız küme yöneticisi) veya Mesos dahil olmak üzere Spark'ın çekirdek küme yöneticilerinden herhangi biri olabilir. Bu, bir kümenin aynı anda birden çok Spark Uygulamasını çalıştırabilmesini gerektirir.
Gerçek dünya Apache Spark Uygulamaları
Spark, modern endüstride en yüksek puan alan ve yaygın olarak kullanılan bir Big Dara platformudur. Apache Spark uygulamalarının en beğenilen gerçek dünyadaki örneklerinden bazıları şunlardır:
Makine Öğrenimi için Kıvılcım
Apache Spark, ölçeklenebilir bir Makine Öğrenimi kitaplığı olan MLlib'e sahiptir. Bu kitaplık, basitlik, ölçeklenebilirlik ve diğer araçlarla sorunsuz entegrasyonu kolaylaştırmak için açıkça tasarlanmıştır. MLlib yalnızca Spark'ın ölçeklenebilirliğine, dil uyumluluğuna ve hızına sahip olmakla kalmaz, aynı zamanda sınıflandırma, kümeleme, boyut azaltma gibi bir dizi gelişmiş analitik görevini de gerçekleştirebilir. MLlib sayesinde Spark, tahmine dayalı analiz, duygu analizi, müşteri segmentasyonu ve tahmine dayalı zeka için kullanılabilir.
Apache Spark'ın bir başka etkileyici özelliği de ağ güvenliği alanında yatmaktadır. Spark Streaming, kullanıcıların veri paketlerini depolamaya göndermeden önce gerçek zamanlı olarak izlemelerine olanak tanır. Bu işlem sırasında, bilinen tehdit kaynaklarından kaynaklanan şüpheli veya kötü niyetli faaliyetleri başarıyla tespit edebilir. Veri paketleri depoya gönderildikten sonra bile Spark, verileri daha fazla analiz etmek ve ağ için olası riskleri belirlemek için MLlib'i kullanır. Bu özellik aynı zamanda dolandırıcılık ve olay tespiti için de kullanılabilir.
Sis Bilişimi için Kıvılcım
Apache Spark, özellikle Nesnelerin İnterneti (IoT) ile ilgili olduğunda, sis hesaplama için mükemmel bir araçtır. IoT, büyük ölçüde büyük ölçekli paralel işleme kavramına dayanır. IoT ağı binlerce ve milyonlarca bağlı cihazdan oluştuğundan, bu ağ tarafından her saniye üretilen veriler anlaşılmazdır.
Doğal olarak, IoT cihazları tarafından üretilen bu kadar büyük hacimli verileri işlemek için paralel işlemeyi destekleyen ölçeklenebilir bir platforma ihtiyacınız vardır. Ve bu kadar büyük miktarda veriyi işlemek için Spark'ın sağlam mimarisi ve sis hesaplama yeteneklerinden daha iyi ne olabilir!
Sis bilişim, verileri ve depolamayı merkezden uzaklaştırır ve bulut işlemeyi kullanmak yerine, ağın kenarında (esas olarak IoT cihazlarına gömülü) veri işleme işlevini gerçekleştirir.
Bunu yapmak için sis hesaplama, düşük gecikme süresi, makine öğreniminin paralel işlenmesi ve her biri Spark'ta bulunan karmaşık grafik analitik algoritmaları olmak üzere üç yetenek gerektirir. Ayrıca, Spark Streaming, Shark (gerçek zamanlı olarak çalışabilen etkileşimli bir sorgulama aracı), MLlib ve GraphX'in (bir grafik analiz motoru) varlığı, Spark'ın sis hesaplama yeteneğini daha da geliştirir.
Etkileşimli Analiz için Kıvılcım
Göreceli olarak düşük işlem hızına sahip MapReduce, Hive veya Pig'in aksine Spark, yüksek hızlı etkileşimli analitikle övünebilir. Verilerin örneklenmesini gerektirmeden keşif sorgularını işleme yeteneğine sahiptir. Ayrıca Spark, R, Python, SQL, Java ve Scala dahil olmak üzere neredeyse tüm popüler geliştirme dilleriyle uyumludur.
Spark - Spark 2.0'ın en son sürümü, Yapılandırılmış Akış olarak bilinen yeni bir işlevselliğe sahiptir. Bu özellik sayesinde kullanıcılar, gerçek zamanlı olarak akış verilerine karşı yapılandırılmış ve etkileşimli sorgular çalıştırabilir.
Spark kullanıcıları
Artık Spark'ın özelliklerini ve yeteneklerini çok iyi bildiğinize göre, Spark'ın öne çıkan dört kullanıcısından bahsedelim!
1. Yahoo
Yahoo, biri ziyaretçiler için haber sayfalarını kişiselleştirmek ve diğeri reklam için analitik çalıştırmak için olmak üzere iki projesi için Spark'ı kullanıyor. Yahoo, haber sayfalarını özelleştirmek için bireysel kullanıcıların ilgi alanlarını, tercihlerini ve ihtiyaçlarını anlamak ve hikayeleri buna göre kategorize etmek için Spark üzerinde çalışan gelişmiş ML algoritmalarından yararlanır.
İkinci kullanım durumu için, Yahoo, Hadoop'ta toplanan Yahoo'nun reklam analitik verilerini görüntülemek ve sorgulamak için Hive on Spark'ın etkileşimli yeteneğinden (Hive'a bağlanan herhangi bir araçla bütünleşmek için) yararlanır.
2. Über
Uber, Spark Streaming'i Kafka ve HDFS'den ETL'ye (ayıklayın, dönüştürün ve yükleyin) birlikte, ayrık olayların büyük miktarlarda gerçek zamanlı verilerini daha fazla analiz için yapılandırılmış ve kullanılabilir verilere kullanır. Bu veriler, Uber'in müşteriler için geliştirilmiş çözümler geliştirmesine yardımcı olur.

3. Conviva
Bir video akışı şirketi olarak Conviva, her ay ortalama 4 milyonun üzerinde video beslemesi alıyor ve bu da büyük müşteri kaybına yol açıyor. Bu zorluk, canlı video trafiğini yönetme sorunuyla daha da ağırlaşıyor. Bu zorluklarla etkin bir şekilde mücadele etmek için Conviva, ağ koşullarını gerçek zamanlı olarak öğrenmek ve video trafiğini buna göre optimize etmek için Spark Streaming'i kullanır. Bu, Conviva'nın kullanıcılara tutarlı ve yüksek kaliteli bir görüntüleme deneyimi sunmasını sağlar.
4. Pinterest
Pinterest'te kullanıcılar, Web'de ve sosyal medyada gezinirken en sevdikleri konuları istedikleri zaman ve istedikleri zaman sabitleyebilirler. Kişiselleştirilmiş ve gelişmiş bir müşteri deneyimi sunmak için Pinterest, bireysel kullanıcıların benzersiz ihtiyaçlarını ve ilgi alanlarını belirlemek ve onlara Pinterest'te ilgili önerilerde bulunmak için Spark'ın ETL yeteneklerini kullanır.
Çözüm
Sonuç olarak, Spark, etkilemek için oluşturulmuş özelliklere sahip son derece çok yönlü bir Büyük Veri platformudur. Açık kaynaklı bir çerçeve olduğu için sürekli olarak gelişiyor ve gelişiyor, buna yeni özellikler ve işlevler ekleniyor. Büyük Veri uygulamaları daha çeşitli ve kapsamlı hale geldikçe, Apache Spark'ın kullanım durumları da artacaktır.
Büyük Veri hakkında daha fazla bilgi edinmek istiyorsanız, çalışan profesyoneller için tasarlanmış ve 7+ vaka çalışması ve proje sağlayan, 14 programlama dili ve aracını kapsayan, pratik uygulamalı Büyük Veride Yazılım Geliştirme Uzmanlığı programında PG Diplomamıza göz atın çalıştaylar, en iyi firmalarla 400 saatten fazla titiz öğrenim ve işe yerleştirme yardımı.
upGrad'daki diğer Yazılım Mühendisliği Kurslarımıza göz atın.