
2022 年 Apache Spark 的 6 個改變遊戲規則的特性 [你應該如何使用]
已發表: 2021-01-07自從大數據席捲科技和商業世界以來,大數據工具和平台出現了巨大的熱潮,尤其是 Apache Hadoop 和 Apache Spark。 今天,我們將只關注 Apache Spark,並詳細討論其業務優勢和應用程序。
Apache Spark 於 2009 年成為眾人矚目的焦點,從那時起,它逐漸在行業中為自己開闢了一片天地。 根據 Apache org.,Spark 是一個“閃電般快速的統一分析引擎”,專為處理海量大數據而設計。 得益於活躍的社區,今天,Spark 是世界上最大的開源大數據平台之一。
目錄
什麼是 Apache Spark?
Spark 最初由加州大學(伯克利)AMPLab 開發,被設計為強大的 Hadoop 數據處理引擎,特別注重速度和易用性。 它是 Hadoop 的 MapReduce 的開源替代品。 從本質上講,Spark 是一個並行數據處理框架,可以與 Apache Hadoop 協作,以促進在 Hadoop 上順利快速地開發複雜的大數據應用程序。
Spark 包含大量用於機器學習 (ML) 算法和圖形算法的庫。 不僅如此,它還分別通過 Spark Streaming 和 Shark 支持實時流和 SQL 應用程序。 使用 Spark 的最佳之處在於,您可以使用 Java、Scala 甚至 Python 編寫 Spark 應用程序,這些應用程序的運行速度(在磁盤上)和在內存中的速度比 MapReduce 應用程序快近 10 倍(在內存中)。
Apache Spark 非常通用,因為它可以以多種方式部署,並且它還為 Java、Scala、Python 和 R 編程語言提供本機綁定。 它支持 SQL、圖形處理、數據流和機器學習。 這就是為什麼 Spark 被廣泛應用於行業各個部門的原因,包括銀行、電信公司、遊戲開發公司、政府機構,當然還有科技界的所有頂級公司——蘋果、Facebook、IBM 和微軟。
Apache Spark 的 6 個最佳特性
使 Spark 成為使用最廣泛的大數據平台之一的特性是:

1. 閃電般的處理速度
大數據處理就是處理大量複雜數據。 因此,在大數據處理方面,組織和企業需要這樣的框架,可以高速處理大量數據。 正如我們之前提到的,在 Hadoop 集群中,Spark 應用程序在內存中的運行速度可以提高 100 倍,在磁盤上的運行速度可以提高 10 倍。
它依賴於彈性分佈式數據集 (RDD),它允許 Spark 透明地將數據存儲在內存上,並僅在需要時將其讀/寫到磁盤。 這有助於減少數據處理過程中的大部分磁盤讀寫時間。
2. 易用性
Spark 允許您使用 Java、Scala、Python 和 R 編寫可擴展的應用程序。因此,開發人員可以使用他們喜歡的編程語言創建和運行 Spark 應用程序。 此外,Spark 內置了 80 多個高級算子。 您可以交互式地使用 Spark 從 Scala、Python、R 和 SQL shell 中查詢數據。
3. 它為複雜的分析提供支持
Spark 不僅支持簡單的“map”和“reduce”操作,還支持 SQL 查詢、流數據和高級分析,包括 ML 和圖形算法。 它帶有強大的庫堆棧,例如 SQL & DataFrames 和 MLlib(用於 ML)、GraphX 和 Spark Streaming。 令人著迷的是,Spark 允許您在單個工作流/應用程序中組合所有這些庫的功能。
4.實時流處理
Spark 旨在處理實時數據流。 雖然 MapReduce 是為處理和處理已經存儲在 Hadoop 集群中的數據而構建的,但 Spark 可以同時執行這兩項操作,還可以通過 Spark Streaming 實時處理數據。
與其他流解決方案不同,Spark Streaming 可以恢復丟失的工作並提供開箱即用的確切語義,而無需額外的代碼或配置。 此外,它還允許您重用相同的代碼進行批處理和流處理,甚至將流數據連接到歷史數據。
5.靈活
Spark可以在集群模式下獨立運行,也可以在Hadoop YARN、Apache Mesos、Kubernetes甚至雲端運行。 此外,它可以訪問各種數據源。 例如,Spark 可以在 YARN 集群管理器上運行並讀取任何現有的 Hadoop 數據。 它可以從任何 Hadoop 數據源中讀取數據,例如 HBase、HDFS、Hive 和 Cassandra。 Spark 的這一方面使其成為遷移純 Hadoop 應用程序的理想工具,前提是應用程序的用例對 Spark 友好。
6. 活躍和擴大的社區
來自300 多家公司的開發人員為設計和構建 Apache Spark 做出了貢獻。 自 2009 年以來,已有超過 1200 名開發人員為使 Spark 成為今天的樣子做出了積極貢獻! 自然,Spark 得到了一個活躍的開發人員社區的支持,他們致力於不斷改進其功能和性能。 要聯繫 Spark 社區,您可以使用郵件列表進行任何查詢,還可以參加 Spark 聚會小組和會議。

Spark 應用剖析
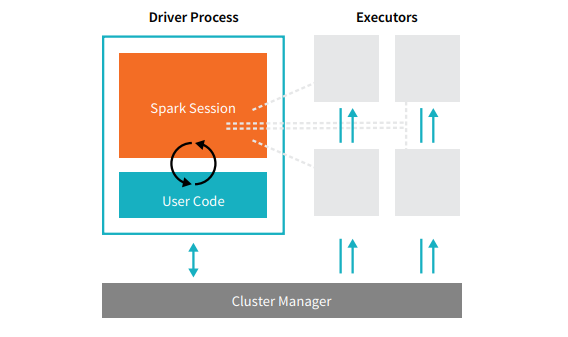
每個 Spark 應用程序都包含兩個核心進程——一個主驅動進程和一組執行進程。
資源
位於集群中節點上的驅動程序進程負責運行 main() 函數。 它還處理其他三項任務——維護有關 Spark 應用程序的信息、響應用戶的代碼或輸入,以及跨執行程序分析、分發和調度工作。 驅動程序進程構成了 Spark 應用程序的核心——它包含並維護了涵蓋 Spark 應用程序生命週期的所有關鍵信息。
執行者或執行者進程是次要項,必須執行驅動程序分配給它們的任務。 基本上,每個執行程序執行兩個關鍵功能——運行驅動程序分配給它的代碼,並將計算狀態(在該執行程序上)報告給驅動程序節點。 用戶可以決定和配置每個節點應該有多少個執行器。
在 Spark 應用程序中,集群管理器控制所有機器並將資源分配給應用程序。 在這裡,集群管理器可以是 Spark 的任何核心集群管理器,包括 YARN(Spark 的獨立集群管理器)或 Mesos。 這意味著一個集群可以同時運行多個 Spark 應用程序。
真實世界的 Apache Spark 應用程序
Spark 是現代行業中評價最高且應用廣泛的 Big Dara 平台。 Apache Spark 應用程序的一些最受好評的真實世界示例是:
機器學習 Spark
Apache Spark 擁有一個可擴展的機器學習庫——MLlib。 該庫明確設計用於簡單性、可擴展性和促進與其他工具的無縫集成。 MLlib 不僅具有 Spark 的可擴展性、語言兼容性和速度,而且還可以執行許多高級分析任務,如分類、聚類、降維。 多虧了 MLlib,Spark 可用於預測分析、情緒分析、客戶細分和預測智能。
Apache Spark 另一個令人印象深刻的特性在於網絡安全領域。 Spark Streaming 允許用戶在將數據包推送到存儲之前對其進行實時監控。 在此過程中,它可以成功識別已知威脅源產生的任何可疑或惡意活動。 即使在數據包被發送到存儲之後,Spark 也會使用 MLlib 進一步分析數據並識別網絡的潛在風險。 此功能還可用於欺詐和事件檢測。
用於霧計算的 Spark
Apache Spark 是用於霧計算的出色工具,尤其是在涉及物聯網 (IoT) 時。 物聯網嚴重依賴大規模並行處理的概念。 由於物聯網網絡是由成千上萬的連接設備組成的,這個網絡每秒產生的數據是無法理解的。
自然,要處理物聯網設備產生的如此大量數據,您需要一個支持並行處理的可擴展平台。 還有什麼比 Spark 強大的架構和霧計算能力更能處理如此大量的數據!
霧計算將數據和存儲分散,而不是使用雲處理,而是在網絡邊緣(主要嵌入物聯網設備)執行數據處理功能。
為此,霧計算需要三種能力,即低延遲、ML 的並行處理和復雜的圖形分析算法——每一種都存在於 Spark 中。 此外,Spark Streaming、Shark(一種可以實時運行的交互式查詢工具)、MLlib 和 GraphX(一種圖分析引擎)的存在進一步增強了 Spark 的霧計算能力。
交互式分析 Spark
與處理速度相對較低的 MapReduce、Hive 或 Pig 不同,Spark 可以擁有高速交互式分析。 它能夠處理探索性查詢,而無需對數據進行採樣。 此外,Spark 兼容幾乎所有流行的開發語言,包括 R、Python、SQL、Java 和 Scala。
最新版本的 Spark – Spark 2.0 – 具有稱為結構化流的新功能。 借助此功能,用戶可以實時對流數據運行結構化和交互式查詢。
Spark的用戶
既然您已經對 Spark 的特性和能力瞭如指掌,那麼讓我們來談談 Spark 的四個傑出用戶吧!
1.雅虎
雅虎在其兩個項目中使用 Spark,一個用於為訪問者個性化新聞頁面,另一個用於運行廣告分析。 為了定制新聞頁面,雅虎利用在 Spark 上運行的高級 ML 算法來了解個人用戶的興趣、偏好和需求,並相應地對故事進行分類。
對於第二個用例,Yahoo 利用 Hive on Spark 的交互功能(與任何插入 Hive 的工具集成)來查看和查詢 Yahoo 在 Hadoop 上收集的廣告分析數據。
2.優步
Uber 使用 Spark Streaming 與 Kafka 和 HDFS 相結合,將離散事件的大量實時數據 ETL(提取、轉換和加載)轉化為結構化和可用數據,以供進一步分析。 這些數據幫助優步為客戶設計改進的解決方案。

3. 康維瓦
作為一家視頻流媒體公司,Conviva 每月平均獲得超過 400 萬條視頻源,這導致了巨大的客戶流失。 管理實時視頻流量的問題進一步加劇了這一挑戰。 為了有效應對這些挑戰,Conviva 使用 Spark Streaming 實時了解網絡狀況並相應地優化其視頻流量。 這使 Conviva 能夠為用戶提供一致且高質量的觀看體驗。
4.品脫
在 Pinterest 上,用戶可以在瀏覽網絡和社交媒體時隨心所欲地固定他們最喜歡的主題。 為了提供個性化和增強的客戶體驗,Pinterest 利用 Spark 的 ETL 功能來識別個人用戶的獨特需求和興趣,並在 Pinterest 上向他們提供相關建議。
結論
總而言之,Spark 是一個極其通用的大數據平台,具有令人印象深刻的功能。 由於它是一個開源框架,因此它不斷改進和發展,並添加了新的特性和功能。 隨著大數據的應用變得更加多樣化和廣泛,Apache Spark 的用例也將如此。
如果您有興趣了解有關大數據的更多信息,請查看我們的 PG 大數據軟件開發專業文憑課程,該課程專為在職專業人士設計,提供 7 多個案例研究和項目,涵蓋 14 種編程語言和工具,實用的動手操作研討會,超過 400 小時的嚴格學習和頂級公司的就業幫助。
在 upGrad 查看我們的其他軟件工程課程。