
Reaktywność na żądanie w Vue 3
Opublikowany: 2022-03-11Oprócz godnych podziwu ulepszeń wydajności, niedawno wydany Vue 3 przyniósł także kilka nowych funkcji. Prawdopodobnie najważniejszym wprowadzeniem jest interfejs Composition API . W pierwszej części tego artykułu podsumowujemy standardową motywację dla nowego API: lepsza organizacja i ponowne wykorzystanie kodu. W drugiej części skupimy się na mniej dyskutowanych aspektach korzystania z nowego interfejsu API, takich jak implementacja funkcji opartych na reaktywności, które były niewyrażalne w systemie reaktywności Vue 2.
Nazywamy to reaktywnością na żądanie . Po wprowadzeniu odpowiednich nowych funkcji, zbudujemy prostą aplikację arkusza kalkulacyjnego, aby zademonstrować nową ekspresję systemu reaktywności Vue. Na samym końcu omówimy, jakie może być rzeczywiste wykorzystanie tej poprawy reaktywności na żądanie.
Co nowego w Vue 3 i dlaczego ma to znaczenie
Vue 3 to główna przeróbka Vue 2, wprowadzająca mnóstwo ulepszeń przy jednoczesnym zachowaniu kompatybilności wstecznej ze starym API prawie w całości.
Jedną z najważniejszych nowych funkcji w Vue 3 jest Composition API . Jego wprowadzenie wywołało wiele kontrowersji, gdy po raz pierwszy zostało omówione publicznie. Jeśli nie znasz jeszcze nowego interfejsu API, najpierw opiszemy jego motywację.
Typową jednostką organizacji kodu jest obiekt JavaScript, którego klucze reprezentują różne możliwe typy elementu komponentu. W ten sposób obiekt może mieć jedną sekcję na dane reaktywne ( data ), inną sekcję na obliczane właściwości ( computed ), jeszcze jedną na metody składowe ( methods ) itp.
Zgodnie z tym paradygmatem komponent może mieć wiele niepowiązanych lub luźno powiązanych funkcjonalności, których wewnętrzne działanie jest rozdzielone pomiędzy wyżej wymienione sekcje komponentów. Na przykład możemy mieć komponent do przesyłania plików, który implementuje dwie zasadniczo oddzielne funkcje: zarządzanie plikami i system kontrolujący animację stanu przesyłania.
Część <script> może zawierać coś takiego:
export default { data () { return { animation_state: 'playing', animation_duration: 10, upload_filenames: [], upload_params: { target_directory: 'media', visibility: 'private', } } }, computed: { long_animation () { return this.animation_duration > 5; }, upload_requested () { return this.upload_filenames.length > 0; }, }, ... } To tradycyjne podejście do organizacji kodu ma swoje zalety, głównie w tym, że programista nie musi martwić się o to, gdzie napisać nowy fragment kodu. Jeśli dodajemy zmienną reaktywną, wstawiamy ją w sekcji data . Jeśli szukamy istniejącej zmiennej, wiemy, że musi ona znajdować się w sekcji data .
To tradycyjne podejście polegające na dzieleniu implementacji funkcjonalności na sekcje ( data , computed itp.) nie jest odpowiednie we wszystkich sytuacjach.
Często przytaczane są następujące wyjątki:
- Radzenie sobie z komponentem o dużej liczbie funkcjonalności. Jeśli chcemy uaktualnić nasz kod animacji o możliwość opóźnienia rozpoczęcia animacji, na przykład, będziemy musieli przewijać/przeskakiwać między wszystkimi odpowiednimi sekcjami komponentu w edytorze kodu. W przypadku naszego komponentu do wgrywania plików, sam komponent jest niewielki, podobnie jak ilość implementowanych przez niego funkcjonalności. Tak więc w tym przypadku przeskakiwanie między sekcjami nie stanowi problemu. Ta kwestia fragmentacji kodu staje się istotna, gdy mamy do czynienia z dużymi komponentami.
- Inną sytuacją, w której brakuje tradycyjnego podejścia, jest ponowne wykorzystanie kodu. Często musimy stworzyć konkretną kombinację danych reaktywnych, obliczonych właściwości, metod itp., dostępnych w więcej niż jednym komponencie.
Vue 2 (oraz kompatybilny wstecznie Vue 3) oferują rozwiązanie większości problemów związanych z organizacją kodu i ponownym wykorzystaniem: mixins .
Plusy i minusy mixinów w Vue 3
Domieszki umożliwiają wyodrębnienie funkcjonalności komponentu w oddzielnej jednostce kodu. Każda funkcja jest umieszczona w osobnym mixinie, a każdy komponent może korzystać z jednego lub więcej mixinów. Kawałki zdefiniowane w mieszance mogą być używane w komponencie tak, jakby były zdefiniowane w samym komponencie. Domieszki przypominają trochę klasy w językach obiektowych, ponieważ gromadzą kod związany z daną funkcjonalnością. Podobnie jak klasy, domieszki mogą być dziedziczone (używane) w innych jednostkach kodu.
Jednak rozumowanie za pomocą domieszek jest trudniejsze, ponieważ w przeciwieństwie do klas, domieszki nie muszą być projektowane z myślą o enkapsulacji. Mixiny mogą być zbiorami luźno powiązanych fragmentów kodu bez dobrze zdefiniowanego interfejsu do świata zewnętrznego. Użycie więcej niż jednej mieszanki na raz w tym samym komponencie może skutkować powstaniem komponentu trudnego do zrozumienia i użycia.
Większość języków zorientowanych obiektowo (np. C# i Java) zniechęca, a nawet nie zezwala na wielokrotne dziedziczenie, pomimo faktu, że paradygmat programowania obiektowego ma narzędzia do radzenia sobie z taką złożonością. (Niektóre języki pozwalają na wielokrotne dziedziczenie, takie jak C++, ale kompozycja jest nadal preferowana nad dziedziczeniem).
Bardziej praktycznym problemem, który może wystąpić podczas używania domieszek w Vue, jest kolizja nazw, która pojawia się, gdy używa się dwóch lub więcej domieszek deklarujących nazwy pospolite. Należy tutaj zauważyć, że jeśli domyślna strategia Vue dotycząca radzenia sobie z kolizjami nazw nie jest idealna w danej sytuacji, programista może ją dostosować. Odbywa się to kosztem wprowadzenia większej złożoności.
Inną kwestią jest to, że domieszki nie oferują czegoś podobnego do konstruktora klas. Jest to problem, ponieważ często potrzebujemy funkcjonalności, która jest bardzo podobna, ale nie dokładnie taka sama, aby była obecna w różnych komponentach. Można to obejść w niektórych prostych przypadkach przy użyciu fabryk mieszanek.
Dlatego mixiny nie są idealnym rozwiązaniem do organizacji i ponownego wykorzystania kodu, a im większy projekt, tym poważniejsze stają się ich problemy. Vue 3 wprowadza nowy sposób rozwiązywania tych samych problemów dotyczących organizacji i ponownego wykorzystania kodu.
Composition API: odpowiedź Vue 3 na organizację i ponowne użycie kodu
Interfejs Composition API pozwala nam (ale nie wymaga od nas) całkowicie oddzielić części komponentu. Każdy fragment kodu — zmienną, obliczoną właściwość, zegarek itp. — można zdefiniować niezależnie.
Na przykład, zamiast mieć obiekt, który zawiera sekcję data , która zawiera klucz animation_state z (domyślną) wartością „playing”, możemy teraz napisać (w dowolnym miejscu w naszym kodzie JavaScript):
const animation_state = ref('playing'); Efekt jest prawie taki sam, jak zadeklarowanie tej zmiennej w sekcji data jakiegoś składnika. Jedyną istotną różnicą jest to, że musimy udostępnić ref zdefiniowany poza komponentem w komponencie, w którym zamierzamy go używać. Robimy to, importując jego moduł do miejsca, w którym jest zdefiniowany komponent i zwracamy ref z sekcji setup komponentu. Na razie pominiemy tę procedurę i przez chwilę skupimy się na nowym interfejsie API. Reaktywność w Vue 3 nie wymaga komponentu; to właściwie samowystarczalny system.
Możemy użyć zmiennej animation_state w dowolnym zakresie, do którego importujemy tę zmienną. Po skonstruowaniu ref otrzymujemy i ustawiamy jego rzeczywistą wartość za pomocą ref.value , na przykład:
animation_state.value = 'paused'; console.log(animation_state.value); Potrzebujemy sufiksu „.value”, ponieważ w przeciwnym razie operator przypisania przypisałby (niereaktywną) wartość „paused” do zmiennej animation_state . Reaktywność w JavaScript (zarówno gdy jest zaimplementowana poprzez defineProperty jak w Vue 2, jak i gdy bazuje na Proxy jak w Vue 3) wymaga obiektu, z którego kluczami możemy pracować reaktywnie.
Zauważ, że tak było również w Vue 2; tam mieliśmy komponent jako prefiks do dowolnego reaktywnego członka danych ( component.data_member ). Dopóki standard języka JavaScript nie wprowadzi możliwości przeciążenia operatora przypisania, wyrażenia reaktywne będą wymagały, aby obiekt i klucz (np. animation_state i value jak powyżej) pojawiały się po lewej stronie każdej operacji przypisania, w której chcemy zachować reaktywność.
W szablonach możemy pominąć .value , ponieważ Vue musi wstępnie przetworzyć kod szablonu i może automatycznie wykryć referencje:
<animation :state='animation_state' /> Teoretycznie kompilator Vue mógłby wstępnie przetworzyć część <script> komponentu pojedynczego pliku (SFC) w podobny sposób, wstawiając w razie potrzeby .value . Jednak użycie refs się wtedy w zależności od tego, czy używamy SFC, czy nie, więc być może taka funkcja nie jest nawet pożądana.
Czasami mamy encję (na przykład obiekt JavaScript lub tablicę), której nigdy nie zamierzamy zastąpić zupełnie inną instancją. Zamiast tego możemy być zainteresowani tylko modyfikacją jego pól z kluczami. W tym przypadku jest skrót: użycie reactive zamiast ref pozwala nam zrezygnować z .value :
const upload_params = reactive({ target_directory: 'media', visibility: 'private', }); upload_params.visibility = 'public'; // no `.value` needed here // if we did not make `upload_params` constant, the following code would compile but we would lose reactivity after the assignment; it is thus a good idea to make reactive variables ```const``` explicitly: upload_params = { target_directory: 'static', visibility: 'public', }; Oddzielona reaktywność z ref i reactive nie jest całkowicie nową funkcją Vue 3. Została częściowo wprowadzona w Vue 2.6, gdzie takie oddzielone instancje danych reaktywnych nazywano „observables”. W większości można zastąpić Vue.observable reactive . Jedną z różnic jest to, że dostęp i mutowanie obiektu przekazanego bezpośrednio do Vue.observable jest reaktywne, podczas gdy nowy interfejs API zwraca obiekt proxy, więc mutowanie oryginalnego obiektu nie będzie miało skutków reaktywnych.
Całkowitą nowością w Vue 3 jest to, że inne reaktywne elementy komponentu można teraz również definiować niezależnie, oprócz reaktywnych danych. Obliczone właściwości są implementowane w oczekiwany sposób:
const x = ref(5); const x_squared = computed(() => x.value * x.value); console.log(x_squared.value); // outputs 25Podobnie można zaimplementować różne typy zegarków, metody cyklu życia i wstrzykiwanie zależności. Ze względu na zwięzłość nie będziemy ich tutaj omawiać.
Załóżmy, że używamy standardowego podejścia SFC do tworzenia Vue. Możemy nawet używać tradycyjnego interfejsu API, z oddzielnymi sekcjami dla danych, obliczanych właściwości itp. Jak zintegrować małe fragmenty reaktywności interfejsu Composition API z SFC? Vue 3 wprowadza kolejną sekcję właśnie w tym celu: setup . Nowa sekcja może być traktowana jako nowa metoda cyklu życia (która jest wykonywana przed każdym innym przechwyceniem — w szczególności przed created ).
Oto przykład kompletnego komponentu, który integruje tradycyjne podejście z Composition API:
<template> <input v-model="x" /> <div>Squared: {{ x_squared }}, negative: {{ x_negative }}</div> </template> <script> import { ref, computed } from 'vue'; export default { name: "Demo", computed: { x_negative() { return -this.x; } }, setup() { const x = ref(0); const x_squared = computed(() => x.value * x.value); return {x, x_squared}; } } </script>Rzeczy, które należy wziąć z tego przykładu:
- Cały kod interfejsu Composition API jest teraz
setup. Możesz chcieć utworzyć oddzielny plik dla każdej funkcji, zaimportować ten plik do SFC i zwrócić żądane bity reaktywności zsetup(aby udostępnić je pozostałej części komponentu). - Możesz połączyć nowe i tradycyjne podejście w tym samym pliku. Zauważ, że
x, mimo że jest odwołaniem, nie wymaga.value, gdy jest mowa w kodzie szablonu lub w tradycyjnych sekcjach komponentu, takich jakcomputed. - Na koniec zauważ, że w naszym szablonie mamy dwa główne węzły DOM; możliwość posiadania wielu węzłów głównych to kolejna nowa funkcja Vue 3.
Reaktywność jest bardziej wyrazista w Vue 3
W pierwszej części tego artykułu poruszyliśmy standardową motywację dla interfejsu Composition API, którą jest ulepszona organizacja kodu i ponowne wykorzystanie. Rzeczywiście, głównym punktem sprzedaży nowego API nie jest jego moc, ale wygoda organizacyjna, jaką zapewnia: możliwość bardziej przejrzystej struktury kodu. Mogłoby się wydawać, że to wszystko – że Composition API umożliwia sposób implementacji komponentów, który omija ograniczenia już istniejących rozwiązań, takich jak mixiny.
Jednak w nowym interfejsie API jest coś więcej. Kompozycji API w rzeczywistości umożliwia nie tylko lepiej zorganizowane, ale także bardziej wydajne systemy reaktywne. Kluczowym składnikiem jest możliwość dynamicznego zwiększania reaktywności aplikacji. Wcześniej należało zdefiniować wszystkie dane, wszystkie wyliczone właściwości itp. przed załadowaniem komponentu. Dlaczego dodawanie obiektów reaktywnych na późniejszym etapie miałoby być przydatne? W dalszej części przyjrzymy się bardziej złożonemu przykładowi: arkuszom kalkulacyjnym.
Tworzenie arkusza kalkulacyjnego w Vue 2
Narzędzia do arkuszy kalkulacyjnych, takie jak Microsoft Excel, LibreOffice Calc i Arkusze Google, mają jakiś system reaktywności. Narzędzia te prezentują użytkownikowi tabelę z kolumnami indeksowanymi według A–Z, AA–ZZ, AAA–ZZZ itp. oraz wierszami indeksowanymi numerycznie.
Każda komórka może zawierać zwykłą wartość lub formułę. Komórka z formułą jest zasadniczo obliczoną właściwością, która może zależeć od wartości lub innych obliczonych właściwości. W przypadku standardowych arkuszy kalkulacyjnych (w przeciwieństwie do systemu reaktywności w Vue) te obliczone właściwości mogą nawet zależeć od siebie! Takie samoodniesienie jest przydatne w niektórych scenariuszach, w których pożądaną wartość uzyskuje się przez przybliżenie iteracyjne.

Gdy zawartość komórki ulegnie zmianie, wszystkie komórki zależne od danej komórki wywołają aktualizację. Jeśli nastąpią dalsze zmiany, dalsze aktualizacje mogą zostać zaplanowane.
Gdybyśmy mieli zbudować aplikację arkusza kalkulacyjnego za pomocą Vue, naturalnym byłoby zapytać, czy możemy użyć własnego systemu reaktywności Vue i uczynić z Vue silnik aplikacji arkusza kalkulacyjnego. Dla każdej komórki mogliśmy zapamiętać jej surową, edytowalną wartość, a także odpowiadającą jej wartość obliczoną. Wartości obliczone będą odzwierciedlać wartość surową, jeśli jest to wartość zwykła, a w przeciwnym razie wartości obliczone są wynikiem wyrażenia (formuły) zapisanego zamiast zwykłej wartości.
W Vue 2 sposobem na zaimplementowanie arkusza kalkulacyjnego jest posiadanie raw_values dwuwymiarowej tablicy ciągów, a computed_values (obliczonej) dwuwymiarowej tablicy wartości komórek.
Jeśli liczba komórek jest mała i ustalona przed załadowaniem odpowiedniego komponentu Vue, moglibyśmy mieć jedną surową i jedną obliczoną wartość dla każdej komórki tabeli w naszej definicji komponentu. Poza estetyczną potwornością, jaką taka implementacja spowodowałaby, tabela ze stałą liczbą komórek w czasie kompilacji prawdopodobnie nie liczy się jako arkusz kalkulacyjny.
Występują również problemy z dwuwymiarową tablicą computed_values . Obliczona właściwość jest zawsze funkcją, której ocena w tym przypadku zależy od niej samej (obliczenie wartości komórki będzie na ogół wymagało obliczenia innych wartości). Nawet jeśli Vue zezwoli na obliczone właściwości autoreferencyjne, aktualizacja pojedynczej komórki spowoduje ponowne obliczenie wszystkich komórek (niezależnie od tego, czy istnieją zależności, czy nie). Byłoby to wyjątkowo nieefektywne. W ten sposób moglibyśmy wykorzystać reaktywność do wykrywania zmian w surowych danych za pomocą Vue 2, ale wszystko inne pod względem reaktywności musiałoby zostać zaimplementowane od zera.
Modelowanie wartości obliczanych w Vue 3
Dzięki Vue 3 możemy wprowadzić nową obliczoną właściwość dla każdej komórki. Jeśli tabela rośnie, wprowadzane są nowe obliczone właściwości.
Załóżmy, że mamy komórki A1 i A2 i chcemy, aby komórka A2 wyświetlała kwadrat komórki A1 o wartości 5. Szkic tej sytuacji:
let A1 = computed(() => 5); let A2 = computed(() => A1.value * A1.value); console.log(A2.value); // outputs 25 Załóżmy, że przez chwilę pozostajemy w tym prostym scenariuszu. Tutaj jest problem; co jeśli chcemy zmienić A1 tak, aby zawierał cyfrę 6? Załóżmy, że piszemy to:
A1 = computed(() => 6); console.log(A2.value); // outputs 25 if we already ran the code above To nie tylko zmieniło wartość 5 na 6 w A1 . Zmienna A1 ma teraz zupełnie inną tożsamość: obliczoną właściwość, która rozwiązuje się do liczby 6. Jednak zmienna A2 nadal reaguje na zmiany dawnej tożsamości zmiennej A1 . Zatem A2 nie powinno odwoływać się bezpośrednio do A1 , ale raczej do jakiegoś specjalnego obiektu, który zawsze będzie dostępny w kontekście i powie nam, czym jest w tej chwili A1 . Innymi słowy, potrzebujemy poziomu niebezpośredniości przed uzyskaniem dostępu do A1 , coś w rodzaju wskaźnika. Nie ma wskaźników jako pierwszorzędnych jednostek w JavaScript, ale łatwo je zasymulować. Jeśli chcemy mieć pointer wskazujący na value , możemy utworzyć pointer = {points_to: value} . Przekierowanie wskaźnika sprowadza się do przypisania do pointer.points_to , a wyłuskanie (uzyskiwanie dostępu do wskazywanej wartości) sprowadza się do pobrania wartości pointer.points_to . W naszym przypadku postępujemy następująco:
let A1 = reactive({points_to: computed(() => 5)}); let A2 = reactive({points_to: computed(() => A1.points_to * A1.points_to)}); console.log(A2.points_to); // outputs 25Teraz możemy zastąpić 5 przez 6.
A1.points_to = computed(() => 6); console.log(A2.points_to); // outputs 36Na serwerze Discord firmy Vue użytkownik redblobgames zasugerował inne interesujące podejście: zamiast używać wartości obliczanych, użyj referencji, które otaczają zwykłe funkcje. W ten sposób można w podobny sposób zamienić funkcję bez zmiany tożsamości samej referencji.
Nasza implementacja arkusza kalkulacyjnego będzie zawierała komórki, do których odwołują się klucze jakiejś dwuwymiarowej tablicy. Ta tablica może zapewnić wymagany przez nas poziom pośredniości. Dzięki temu w naszym przypadku nie będziemy potrzebować dodatkowej symulacji wskaźnika. Moglibyśmy nawet mieć jedną tablicę, która nie rozróżnia wartości surowych i obliczonych. Wszystko może być wartością obliczoną:
const cells = reactive([ computed(() => 5), computed(() => cells[0].value * cells[0].value) ]); cells[0] = computed(() => 6); console.log(cells[1].value); // outputs 36Jednak naprawdę chcemy rozróżnić wartości surowe i obliczone, ponieważ chcemy mieć możliwość powiązania wartości surowej z elementem wejściowym HTML. Co więcej, jeśli mamy osobną tablicę dla wartości surowych, nigdy nie musimy zmieniać definicji obliczanych właściwości; zaktualizują się automatycznie na podstawie nieprzetworzonych danych.
Wdrażanie arkusza kalkulacyjnego
Zacznijmy od kilku podstawowych definicji, które w większości nie wymagają wyjaśnień.
const rows = ref(30), cols = ref(26); /* if a string codes a number, return the number, else return a string */ const as_number = raw_cell => /^[0-9]+(\.[0-9]+)?$/.test(raw_cell) ? Number.parseFloat(raw_cell) : raw_cell; const make_table = (val = '', _rows = rows.value, _cols = cols.value) => Array(_rows).fill(null).map(() => Array(_cols).fill(val)); const raw_values = reactive(make_table('', rows.value, cols.value)); const computed_values = reactive(make_table(undefined, rows.value, cols.value)); /* a useful metric for debugging: how many times did cell (re)computations occur? */ const calculations = ref(0); Plan polega na tym, że każda computed_values[row][column] ma być obliczana w następujący sposób. Jeśli raw_values[row][column] nie zaczyna się od = , zwróć raw_values[row][column] . W przeciwnym razie przeanalizuj formułę, skompiluj ją do JavaScript, oceń skompilowany kod i zwróć wartość. Krótko mówiąc, będziemy trochę oszukiwać formułami parsowania i nie będziemy tutaj robić oczywistych optymalizacji, takich jak pamięć podręczna kompilacji.
Założymy, że użytkownicy mogą wprowadzić dowolne prawidłowe wyrażenie JavaScript jako formułę. Możemy zastąpić odniesienia do nazw komórek, które pojawiają się w wyrażeniach użytkownika, takich jak A1, B5 itp., na odniesienie do rzeczywistej wartości komórki (obliczonej). Poniższa funkcja wykonuje tę pracę, zakładając, że łańcuchy przypominające nazwy komórek naprawdę zawsze identyfikują komórki (i nie są częścią jakiegoś niepowiązanego wyrażenia JavaScript). Dla uproszczenia przyjmiemy, że indeksy kolumn składają się z jednej litery.
const letters = Array(26).fill(0) .map((_, i) => String.fromCharCode("A".charCodeAt(0) + i)); const transpile = str => { let cell_replacer = (match, prepend, col, row) => { col = letters.indexOf(col); row = Number.parseInt(row) - 1; return prepend + ` computed_values[${row}][${col}].value `; }; return str.replace(/(^|[^AZ])([AZ])([0-9]+)/g, cell_replacer); }; Używając funkcji transpile , możemy uzyskać czyste wyrażenia JavaScript z wyrażeń napisanych w naszym małym „rozszerzeniu” JavaScript z odwołaniami do komórek.
Następnym krokiem jest wygenerowanie obliczonych właściwości dla każdej komórki. Ta procedura będzie miała miejsce raz w życiu każdej komórki. Możemy stworzyć fabrykę, która zwróci żądane wyliczone właściwości:
const computed_cell_generator = (i, j) => { const computed_cell = computed(() => { // we don't want Vue to think that the value of a computed_cell depends on the value of `calculations` nextTick(() => ++calculations.value); let raw_cell = raw_values[i][j].trim(); if (!raw_cell || raw_cell[0] != '=') return as_number(raw_cell); let user_code = raw_cell.substring(1); let code = transpile(user_code); try { // the constructor of a Function receives the body of a function as a string let fn = new Function(['computed_values'], `return ${code};`); return fn(computed_values); } catch (e) { return "ERROR"; } }); return computed_cell; }; for (let i = 0; i < rows.value; ++i) for (let j = 0; j < cols.value; ++j) computed_values[i][j] = computed_cell_generator(i, j); Jeśli umieścimy cały powyższy kod w metodzie setup , musimy zwrócić {raw_values, computed_values, rows, cols, letters, calculations} .
Poniżej przedstawiamy kompletny komponent wraz z podstawowym interfejsem użytkownika.
Kod jest dostępny na GitHub, a także możesz sprawdzić demo na żywo.
<template> <div> <div>Calculations: {{ calculations }}</div> <table class="table" border="0"> <tr class="row"> <td></td> <td class="column" v-for="(_, j) in cols" :key="'header' + j" > {{ letters[j] }} </td> </tr> <tr class="row" v-for="(_, i) in rows" :key="i" > <td class="column"> {{ i + 1 }} </td> <td class="column" v-for="(__, j) in cols" :key="i + '-' + j" :class="{ column_selected: active(i, j), column_inactive: !active(i, j), }" @click="activate(i, j)" > <div v-if="active(i, j)"> <input :ref="'input' + i + '-' + j" v-model="raw_values[i][j]" @keydown.enter.prevent="ui_enter()" @keydown.esc="ui_esc()" /> </div> <div v-else v-html="computed_value_formatter(computed_values[i][j].value)"/> </td> </tr> </table> </div> </template> <script> import {ref, reactive, computed, watchEffect, toRefs, nextTick, onUpdated} from "vue"; export default { name: 'App', components: {}, data() { return { ui_editing_i: null, ui_editing_j: null, } }, methods: { get_dom_input(i, j) { return this.$refs['input' + i + '-' + j]; }, activate(i, j) { this.ui_editing_i = i; this.ui_editing_j = j; nextTick(() => this.get_dom_input(i, j).focus()); }, active(i, j) { return this.ui_editing_i === i && this.ui_editing_j === j; }, unselect() { this.ui_editing_i = null; this.ui_editing_j = null; }, computed_value_formatter(str) { if (str === undefined || str === null) return 'none'; return str; }, ui_enter() { if (this.ui_editing_i < this.rows - 1) this.activate(this.ui_editing_i + 1, this.ui_editing_j); else this.unselect(); }, ui_esc() { this.unselect(); }, }, setup() { /*** All the code we wrote above goes here. ***/ return {raw_values, computed_values, rows, cols, letters, calculations}; }, } </script> <style> .table { margin-left: auto; margin-right: auto; margin-top: 1ex; border-collapse: collapse; } .column { box-sizing: border-box; border: 1px lightgray solid; } .column:first-child { background: #f6f6f6; min-width: 3em; } .column:not(:first-child) { min-width: 4em; } .row:first-child { background: #f6f6f6; } #empty_first_cell { background: white; } .column_selected { border: 2px cornflowerblue solid !important; padding: 0px; } .column_selected input, .column_selected input:active, .column_selected input:focus { outline: none; border: none; } </style>A co z użytkowaniem w świecie rzeczywistym?
Widzieliśmy, jak oddzielony system reaktywności Vue 3 umożliwia nie tylko czystszy kod, ale także pozwala na bardziej złożone systemy reaktywne oparte na nowym mechanizmie reaktywności Vue. Od wprowadzenia Vue minęło około siedmiu lat, a wzrost ekspresji nie był wyraźnie pożądany.
Przykład arkusza kalkulacyjnego jest prostą demonstracją tego, do czego Vue jest teraz zdolny. Możesz także sprawdzić demo na żywo.
Ale jako prawdziwy przykład jest to nieco niszowe. W jakich sytuacjach może się przydać nowy system? Najbardziej oczywistym przypadkiem użycia reaktywności na żądanie może być wzrost wydajności w przypadku złożonych aplikacji.
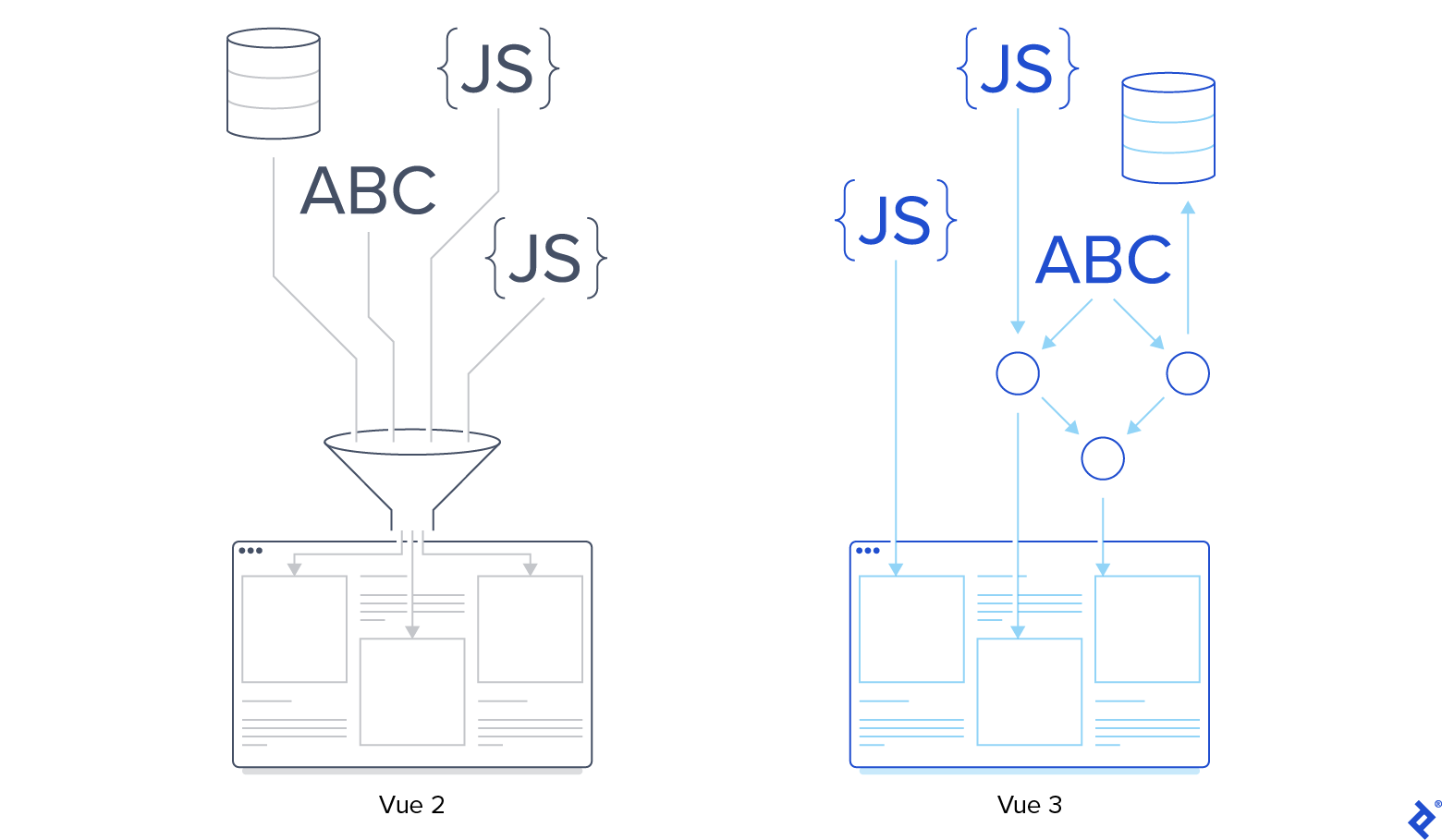
W aplikacjach typu front-end, które pracują z dużą ilością danych, obciążenie wynikające ze źle przemyślanej reaktywności może mieć negatywny wpływ na wydajność. Załóżmy, że mamy aplikację dashboardu biznesowego, która generuje interaktywne raporty z działalności biznesowej firmy. Użytkownik może wybrać zakres czasowy oraz dodać lub usunąć wskaźniki wydajności w raporcie. Niektóre wskaźniki mogą wyświetlać wartości zależne od innych wskaźników.
Jednym ze sposobów implementacji generowania raportów jest użycie struktury monolitycznej. Gdy użytkownik zmieni parametr wejściowy w interfejsie, zostanie zaktualizowana pojedyncza obliczona właściwość, np. report_data . Obliczenie tej obliczonej właściwości odbywa się zgodnie z ustalonym planem: najpierw oblicz wszystkie niezależne wskaźniki wydajności, następnie te, które zależą tylko od tych niezależnych wskaźników itp.
Lepsza implementacja spowoduje oddzielenie bitów raportu i niezależne ich obliczenie. Są z tego pewne korzyści:
- Deweloper nie musi zapisywać na stałe planu wykonania, co jest żmudne i podatne na błędy. System reaktywności Vue automatycznie wykryje zależności.
- W zależności od ilości danych, możemy uzyskać znaczny wzrost wydajności, ponieważ aktualizujemy tylko dane raportu, które logicznie zależą od zmodyfikowanych parametrów wejściowych.
Jeśli wszystkie wskaźniki wydajności, które mogą być częścią końcowego raportu, są znane przed załadowaniem komponentu Vue, możemy być w stanie wdrożyć proponowane oddzielenie nawet w Vue 2. W przeciwnym razie, jeśli backend jest jedynym źródłem prawdy (co jest zwykle ma to miejsce w przypadku aplikacji opartych na danych) lub jeśli istnieją zewnętrzni dostawcy danych, możemy generować obliczane właściwości na żądanie dla każdego fragmentu raportu.
Dzięki Vue 3 jest to teraz nie tylko możliwe, ale i łatwe do zrobienia.