
Wizualizacja wykresu pudełkowego z pandami [Kompleksowy przewodnik]
Opublikowany: 2020-09-03W przypadku każdego projektu analizy danych statystycznych istnieje wiele przydatnych narzędzi, które można zastosować. Podstawową ideą jest zidentyfikowanie pytania i użycie niezbędnej funkcji, aby odpowiedzieć na to pytanie. Na przykład, jeśli trzeba zobaczyć rozkład danych, idealną odpowiedzią jest wykreślenie funkcji rozkładu danych.
Jeśli konieczne jest zobaczenie wartości i porównanie ich z wartościami w innych kolumnach, najlepszym sposobem jest wykreślenie wykresu słupkowego lub histogramu. Ale co, jeśli zapytanie statystyczne musi zostać spełnione? Trend można zaobserwować w funkcji rozkładu, ale nie ma łatwego wyjścia, jeśli musimy sprawdzić konkretny percentyl danych. Zapoznaj się z naszymi szkoleniami z zakresu analizy danych prowadzonych przez uznane uniwersytety, aby zyskać przewagę nad konkurencją.
Boxplot jest rozwiązaniem powyższego problemu. Wykresy pudełkowe są używane do opisywania wartości percentyla atrybutu, zgodnie z kolumną, względem której jest wykreślany. Boxplot może być bardzo wnikliwy w inżynierii modeli opartych na regułach, a także ogólnie w eksploracyjnej analizie danych.
Boxplot zajmuje się kwartylami.
Najpierw narysujmy wykres pudełkowy pandy, a następnie zrozummy jego części.
Spis treści
Tworzenie wykresu pudełkowego Pandy
Aby zaimplementować wykres pudełkowy pandy, są tylko dwa wymagania: Pandas i matplotlib. Użycie matplotlib polega na wizualizacji wykresów i zobaczeniu wykresów w notatniku Jupyter.
Oto jak importujemy obie biblioteki. Korzystamy z funkcji inline magic, aby wykresy były widoczne bezpośrednio w notatniku.
Kod:
importuj pandy jako PD
importuj matplotlib.pyplot jako plt
%matplotlib wbudowany
Teraz importujemy nasze dane i wczytujemy je do DataFrame. Oto jak to zrobić.
Kod:
dane = pd.read_csv("Statystyka FIFA 2018.csv")
DataFrame to podstawowa struktura danych Pandy. Oto pierwsze pięć próbek naszych danych.
Po zaimportowaniu danych możemy bezpośrednio użyć funkcji pandas boxplot nad obiektem DataFrame. Oto jak z niego korzystać:
Kod:
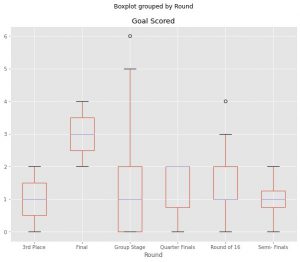
data.boxplot(by=”Runda”, kolumna=['Ocena celu'])
Funkcja wykresu pudełkowego pandy przyjmuje dwa argumenty. Parametr „by” służy do wyboru osi X. A „kolumna” to dane do wykreślenia na osi Y.
Tutaj wykreślamy cele zdobyte przez rundy.
Oto fabuła:
Kasa: Pytania do rozmowy kwalifikacyjnej w Pythonie
Czytanie wykresów pudełkowych
Teraz przeczytajmy fabuły. Po pierwsze, zrozum wartości osi. Oś Y pokazuje liczbę bramek zdobytych w meczu, a oś X pokazuje rundy, w których rozegrano mecz. Weźmy przykład z rundy finałowej.
Jeśli uważnie przyjrzymy się, pudełko jest zrobione gdzieś między dwoma a czterema, z linią środkową na poziomie trzech. Pudełko jest wykreślane przy użyciu trzech wartości – wartości 25., 50. i 75. percentyla. Dolna linia wykresu oznacza 25. percentyl bramek zdobytych w meczu, środkowa oznacza 50. percentyl, a górna linia oznacza 75. percentyl. Zatem boxplot działa z zakresem międzykwartylowym (IQR) danych.
Przeczytaj: Samouczek Python Pandas: Wszystko, co początkujący powinni wiedzieć o Python Pandas
Teraz jest jeszcze jedna rzecz narysowana nad i pod pudełkiem. Te linie są znane jako wąsy. Dlatego czasami boxplot jest również znany jako fabuła box-and-whiskers.
Nie ma unikalnego sposobu na wykreślenie wąsów. Najpopularniejszym sposobem oznaczania wąsów jest zaznaczenie ich przy minimalnej i maksymalnej wartości w kolumnie danych. Niektóre biblioteki, takie jak seaborn, używają multiplikatywnej wartości IQR do oznaczania wąsów. Wykres pudełkowy Pandy wykorzystuje maksymalne i minimalne wartości do oznaczenia wąsów.

Jeśli zauważysz, jest kilka punktów od czterech do sześciu. Są one znane jako wartości odstające. Wykresy pudełkowe są dość przydatne w systemach opartych na regułach jako obliczanie błędów lub mogą szybko zidentyfikować błędną klasyfikację. Na przykład na wykresie, jeśli potrzebujesz tylko rozróżnić rundy trzeciego miejsca od rund finałowych, możesz łatwo stworzyć system oparty na regułach, który dokładnie kategoryzuje Twoje dane. Jeśli od zera do dwóch, oznacz trzecią rundę, a jeśli od dwóch do czterech, oznacz rundę końcową.
Wykresy pudełkowe pomagają zrozumieć ogólny rozkład kolumn danych. Wykresy przedstawiają rozkłady za pomocą wartości kwartylowych. Ułatwia to szybką analizę danych, ponieważ rozkład został odpowiednio oznaczony. Wąsy oznaczają pozostałe wartości w kolumnie.
Wniosek
Dolny koniec oznacza dane niższe niż 25%, a górny oznacza dane wyższe niż 75%. Jeśli wartości odstających są mniejsze, wykresy pudełkowe pand mogą pomóc w ich szybkiej identyfikacji. Ogólnie rzecz biorąc, jeśli potrafisz je poprawnie odczytać, wykresy pudełkowe są niezwykle przydatne w analizie danych.
Jeśli jesteś zainteresowany nauką o danych, sprawdź program IIIT-B i upGrad Executive PG w dziedzinie Data Science , który jest stworzony dla pracujących profesjonalistów i oferuje ponad 10 studiów przypadków i projektów, praktyczne warsztaty praktyczne, mentoring z ekspertami z branży, 1 -on-1 z mentorami branżowymi, ponad 400 godzin nauki i pomocy w pracy z najlepszymi firmami.
Jaki typ danych przedstawia wykres pudełkowy?
Wizualizacja wykresu pudełkowego jest szeroko stosowana w statystyce opisowej. Jest to rodzaj wykresu, który jest często używany do eksploracyjnej analizy danych. Wyświetlając kwartyle (procenty) i średnie, wykresy pudełkowe mogą wizualnie przedstawiać rozkład danych liczbowych wraz z ich skośnością.
Podsumowanie zestawu danych jest wyświetlane za pomocą wykresów skrzynkowych w formacie wizualnym w pięciu różnych kategoriach. Dane dostarczone przez wykres pudełkowy to:
1. Minimalny wynik
2. Najpierw lub możemy powiedzieć dolny kwartyl
3. Mediana wykresu pudełkowego Trzecia lub górny kwartyl
4.Maksymalny wynik
Dane tutaj są podzielone na różne sekcje, aby ułatwić ich reprezentację i dość łatwe wizualne zrozumienie danych.
Dlaczego wykresy pudełkowe okazały się przydatne?
Praca wykresów skrzynkowych polega na podzieleniu zbioru danych na różne sekcje, przy czym każda sekcja zawiera w przybliżeniu 25% danych. Stwierdzono, że wykresy pudełkowe są naprawdę przydatne, ponieważ zapewniają wizualne podsumowanie obecnych danych. Pozwala to naukowcom na łatwą identyfikację średnich wartości, znalezienie znaków skośności i poznanie rozrzutu zbiorów danych.
Wykres pudełkowy może zapewnić wizualny obraz, aby zobaczyć, czy zestaw danych statystycznych jest przekrzywiony, czy normalnie rozłożony. Jeśli ma rozkład normalny, mediana będzie znajdować się pośrodku pudełka, a pudełko będzie symetryczne. Z drugiej strony skrzynka będzie asymetryczna, a mediana będzie skierowana w dół lub w górę, gdy rozkład jest skośny.
Czy możemy wykorzystać Pandy do wizualizacji danych?
Wiadomo, że Pandas jest najbardziej użyteczną biblioteką w języku Python, jeśli chodzi o Data Science. Stwierdzono, że Pandy są naprawdę pomocne w manipulowaniu, importowaniu, a także czyszczeniu zestawów danych. Poza tym Pandas jest również szeroko wykorzystywana do wizualizacji danych.
W wizualizacji danych Pandy służy do wykreślania różnych podstawowych wykresów. Funkcjonalności tej biblioteki znajdują się również w wizualizacji danych szeregów czasowych. W prostych słowach można powiedzieć, że jeśli chcesz wykreślić prosty słupek, zliczyć wykresy lub linie, powinieneś wykorzystać Pandy do wizualizacji danych.