數據科學和機器學習在 NETFLIX 中的應用
已發表: 2018-08-21行業正在以令人興奮和創造性的方式使用數據科學。 數據科學出現在意想不到的地方,提高了各個部門的效率。 它正在推動人類決策,並以前所未有的方式影響業務的頂線和底線。 各行各業通過數據科學和機器學習為他們的應用程序提供動力,從而使數百萬客戶感到高興。
這個博客系列旨在討論數據科學和機器學習在各個公司中的有趣應用。 每篇博文都會重點關註一家公司。 本博客系列將討論 Google、Apple、LinkedIn、Uber、Instagram、Twitter、Instacart、Netflix、Washington post、Quora、Pinterest、Amazon、Medium、Microsoft 等公司如何利用數據科學和機器學習為其提供動力企業。 所以,讓我們從“Netflix”開始這個系列。
目錄
Netflix
眾所周知,Netflix 使用推薦系統向其客戶推薦電影或節目。 除了電影推薦之外,Netflix 使用數據科學和機器學習的許多其他鮮為人知的領域包括:
- 為電影和節目確定個性化的藝術作品
- 向編輯推薦節目中的最佳幀以進行創意工作
- 通過決定視頻編碼、客戶端和服務器端算法的進步、緩存視頻等來提高服務質量 (QoS) 流
- 優化生產的不同階段
- 使用 A/B 測試和決定因果推理來試驗各種算法。 減少使用交織等進行實驗的時間。
個性化藝術品
Netflix 推薦的每部電影都帶有相關的藝術作品。 電影建議附帶的藝術品並不適合所有人。 與電影推荐一樣,與節目相關的藝術品也是個性化的。 所有成員都看不到一個最好的藝術品。 將為特定標題創建藝術品組合。 根據觀眾的品味和偏好,機器學習算法將選擇能夠最大限度地提高查看標題的機會的藝術品。
為標題“陌生人事物”創作的藝術品組合: 
工作中的個性化。 頂行 - 為喜歡女演員烏瑪瑟曼的觀眾推薦的藝術品。 底行 - 給喜歡演員約翰特拉沃爾塔的觀眾的藝術作品建議: 
藝術品個性化並不總是那麼簡單。 藝術品個性化面臨挑戰。 首先,只能為藝術品個性化選擇單個圖像。 相比之下,一次可以推薦許多電影。 其次,藝術品建議應該與電影推薦引擎一起工作。 它通常位於電影推薦之上。 第三,個性化的藝術品推薦應該考慮其他電影的圖像推薦。 否則,作品的建議就不會有千差萬別,單調乏味。 第四,在會話之間展示相同的藝術品還是不同的藝術品。 每次顯示不同的圖像都會使觀看者感到困惑,也會導致歸屬問題。 歸因問題是哪個藝術品引導觀眾觀看節目。
藝術品個性化導致觀眾發現內容的顯著改進。 藝術品個性化不僅是個性化推薦的第一個實例,而且是如何向成員進行推薦的第一個實例。 Netflix 仍在積極研究和完善這種新興技術。
關聯規則挖掘及其應用概述
圖像發現的藝術
一小時的《怪奇物語》由 86,000 個靜態視頻幀組成。 單季(10 集)平均包含 900 萬幀。 Netflix 定期添加內容以滿足其全球客戶的需求。 在這種情況下,不可能手動收割來為“合適的”人找到“合適的”藝術品。 人工編輯幾乎不可能搜索出能夠展現節目獨特元素的最佳幀。 為了大規模應對這一挑戰,Netflix 構建了一套工具來重新呈現真正捕捉到節目真正精神的最佳幀。
自動捕捉節目最佳幀的管道: 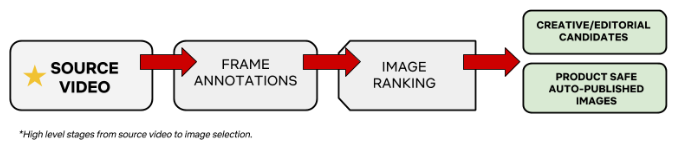
幀註釋用於捕獲用於圖像排序的目標信號。 為了實現幀註釋,視頻被分成多個小塊。 這些塊使用稱為“Archer”的框架並行處理。 這種並行處理正在幫助 Netflix 大規模捕獲幀註釋。 每一塊都由機器視覺算法處理以獲得幀特徵。 例如,捕獲的幀的一些屬性是顏色、亮度、對比度等。將告訴幀中發生了什麼並在幀註釋期間捕獲的一類特徵是面部檢測、運動估計、對象檢測等。 Netflix 還從攝影、電影攝影和視覺美學設計的核心原則(如三分法則等)中確定了一組屬性,這些屬性是在幀註釋期間捕獲的。
幀註釋後的下一步是對圖像進行排名。 排名考慮的一些因素是演員、圖像的多樣性、內容成熟度等。Netflix 正在使用深度學習技術對節目中演員的圖像進行聚類,優先考慮主要角色並降低次要角色的優先級。 暴力和裸露的畫面得分很低。 使用這種排名方法,一個節目的最佳幀就會浮出水面。 這樣,美術和編輯團隊將擁有一組高質量的圖像來處理,而不是為特定劇集處理數百萬幀。

生產中的數據科學
Netflix 今年將花費 80 億美元用於創作原創內容。 以 20 多種語言為全球數百萬觀眾創建的內容。 如果 Netflix 使用數據科學來製作原創內容,我們應該不會感到驚訝。 事實上,Netflix 在內容製作的每一步都使用了數據科學。
通常,製作內容將包括預製作、製作和後期製作階段。 計劃、預算等發生在前期製作中。 主要攝影是製作的一部分。 編輯、混音等步驟是後期製作的一部分。 添加字幕和消除技術故障是本地化和質量控制的一部分。 現在讓我們看看數據科學如何幫助優化生產的每個階段。
自動捕捉節目最佳幀的管道: 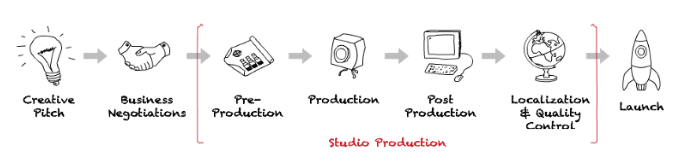
如前所述,預算是前期製作的一部分。 在生產開始之前需要做出許多決定。 例如,拍攝地點。 數據科學被廣泛用於分析特定位置的成本影響。 通過巧妙地平衡創意願景和預算來做出決定。 成本最小化是在不影響內容願景的情況下完成的。
製作涉及在數月內拍攝數千張照片。 生產將有一個目標,但它需要在特定的限制下進行。 例如,約束條件可以是一個演員只有一個星期可用,一個位置只能在特定的日子裡可用,工作人員的工作時間是每天 8 小時,時間限制,如白天拍攝或夜間拍攝,團隊可能必須在拍攝之間移動位置。 準備一個包含所有這些限制的拍攝時間表對導演來說可能是一場噩夢。 此處使用數學優化技術,具有目標和約束條件。 這種優化技術將給出一個粗略的拍攝時間表。 該時間表通過調整進一步細化。

後期製作將花費與製作一樣多的時間,如果不是更多的話。 數據可視化技術用於檢查後期製作中的瓶頸。 可視化技術也用於跟踪後期製作的趨勢並將其投射到未來。 進行此預測是為了查看各個團隊的工作量並適當地為團隊配備人員。
在本地化中,節目被從一種語言配音到另一種語言。 根據數據分析確定需要配音的節目的優先級。 過去證明很受歡迎的配音內容優先。 質量控制將檢查音頻和視頻之間的同步、字幕與聲音的同步等問題。質量控制在編碼之前和之後進行(將視頻壓縮為不同比特率以在不同設備上流式傳輸的過程)。 Netflix 從人工質量控制檢查中積累了歷史數據。 這些數據包括過去發生的錯誤、發現錯誤的視頻格式、獲得此內容的合作夥伴、內容的類型等。是的,Netflix 發現該類型的錯誤模式為好吧。 使用這些數據構建了一個機器學習模型,該模型可以預測質量檢查的“通過”或“失敗”。 如果機器學習算法預測“失敗”,那麼該資產將通過一輪手動質量檢查。
印度聘請數據科學家的頂級公司
流媒體體驗質量和 A/B 測試
數據科學被廣泛用於確保流媒體體驗的質量。 預測網絡連接質量以確保流媒體質量。 Netflix 主動預測哪個節目將在特定位置播放,並將內容緩存在附近的服務器中。 當互聯網流量較低時,會完成內容的緩存和存儲。 這可確保內容在沒有緩衝區的情況下進行流式傳輸,並最大限度地提高客戶滿意度。每當對現有算法進行更改或提出新算法時,都會廣泛使用 A/B 測試。 使用交叉和重複測量等新技術來加速 A/B 測試過程,使用的樣本數量非常少。
總而言之,這些是 Netflix 使用數據分析來吸引和敬畏客戶的一些方式。 如果您有興趣深入了解這家了不起的公司如何使用數據科學,請訪問他們的研究博客。 他們的博客上有大量文章等待探索。
在即將發布的博客系列中,讓我們看看 Instacart 如何利用數據科學和機器學習。 現在您已閱讀此博客,請提供您對本文的看法的反饋。 此外,就您希望在我未來的系列中看到的公司提供建議。
學習世界頂尖大學的數據科學課程。 獲得行政 PG 課程、高級證書課程或碩士課程,以加快您的職業生涯。