数据科学和机器学习在 NETFLIX 中的应用
已发表: 2018-08-21行业正在以令人兴奋和创造性的方式使用数据科学。 数据科学出现在意想不到的地方,提高了各个部门的效率。 它正在推动人类决策,并以前所未有的方式影响业务的顶线和底线。 各行各业通过数据科学和机器学习为他们的应用程序提供动力,从而使数百万客户感到高兴。
这个博客系列旨在讨论数据科学和机器学习在各个公司中的有趣应用。 每篇博文都会重点关注一家公司。 本博客系列将讨论 Google、Apple、LinkedIn、Uber、Instagram、Twitter、Instacart、Netflix、Washington post、Quora、Pinterest、Amazon、Medium、Microsoft 等公司如何利用数据科学和机器学习为其提供动力企业。 所以,让我们从“Netflix”开始这个系列。
目录
Netflix
众所周知,Netflix 使用推荐系统向其客户推荐电影或节目。 除了电影推荐之外,Netflix 使用数据科学和机器学习的许多其他鲜为人知的领域包括:
- 为电影和节目确定个性化的艺术作品
- 向编辑推荐节目中的最佳帧以进行创意工作
- 通过决定视频编码、客户端和服务器端算法的进步、缓存视频等来提高服务质量 (QoS) 流
- 优化生产的不同阶段
- 使用 A/B 测试和决定因果推理来试验各种算法。 减少使用交织等进行实验的时间。
个性化艺术品
Netflix 推荐的每部电影都带有相关的艺术作品。 电影建议附带的艺术品并不适合所有人。 与电影推荐一样,与节目相关的艺术品也是个性化的。 所有成员都看不到一个最好的艺术品。 将为特定标题创建艺术品组合。 根据观众的品味和偏好,机器学习算法将选择能够最大限度地提高查看标题的机会的艺术品。
为标题“陌生人事物”创作的艺术品组合: 
工作中的个性化。 顶行 - 为喜欢女演员乌玛瑟曼的观众推荐的艺术品。 底行 - 给喜欢演员约翰特拉沃尔塔的观众的艺术作品建议: 
艺术品个性化并不总是那么简单。 艺术品个性化面临挑战。 首先,只能为艺术品个性化选择单个图像。 相比之下,一次可以推荐许多电影。 其次,艺术品建议应该与电影推荐引擎一起工作。 它通常位于电影推荐之上。 第三,个性化的艺术品推荐应该考虑其他电影的图像推荐。 否则,作品的建议就不会有千差万别,单调乏味。 第四,在会话之间展示相同的艺术品还是不同的艺术品。 每次显示不同的图像都会使观看者感到困惑,也会导致归属问题。 归因问题是哪个艺术品引导观众观看节目。
艺术品个性化导致观众发现内容的显着改进。 艺术品个性化不仅是个性化推荐的第一个实例,也是如何向成员推荐的第一个实例。 Netflix 仍在积极研究和完善这种新兴技术。
关联规则挖掘及其应用概述
图像发现的艺术
一小时的《怪奇物语》由 86,000 个静态视频帧组成。 单季(10 集)平均包含 900 万帧。 Netflix 定期添加内容以满足其全球客户的需求。 在这种情况下,不可能手动收割来为“合适的”人找到“合适的”艺术品。 人工编辑几乎不可能搜索出能够展现节目独特元素的最佳帧。 为了大规模应对这一挑战,Netflix 构建了一套工具来重新呈现真正捕捉到节目真正精神的最佳帧。
自动捕捉节目最佳帧的管道: 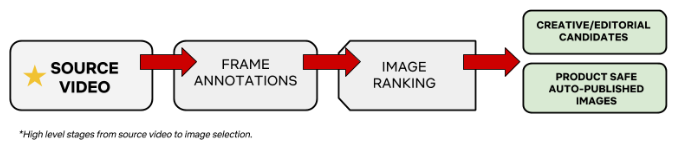
帧注释用于捕获用于图像排序的目标信号。 为了实现帧注释,视频被分成多个小块。 这些块使用称为“Archer”的框架并行处理。 这种并行处理正在帮助 Netflix 大规模捕获帧注释。 每一块都由机器视觉算法处理以获得帧特征。 例如,捕获的帧的一些属性是颜色、亮度、对比度等。将告诉帧中发生了什么并在帧注释期间捕获的一类特征是面部检测、运动估计、对象检测等。 Netflix 还从摄影、电影摄影和视觉美学设计的核心原则(如三分法则等)中确定了一组属性,这些属性是在帧注释期间捕获的。
帧注释后的下一步是对图像进行排名。 排名考虑的一些因素是演员、图像的多样性、内容成熟度等。Netflix 正在使用深度学习技术对节目中演员的图像进行聚类,优先考虑主要角色并降低次要角色的优先级。 暴力和裸露的画面得分很低。 使用这种排名方法,一个节目的最佳帧就会浮出水面。 这样,美术和编辑团队将拥有一组高质量的图像来处理,而不是处理特定剧集的数百万帧。

生产中的数据科学
Netflix 今年将花费 80 亿美元用于创作原创内容。 以 20 多种语言为全球数百万观众创建的内容。 如果 Netflix 使用数据科学来制作原创内容,我们应该不会感到惊讶。 事实上,Netflix 在内容制作的每一步都使用了数据科学。
通常,制作内容将包括预制作、制作和后期制作阶段。 计划、预算等发生在前期制作中。 主要摄影是制作的一部分。 编辑、混音等步骤是后期制作的一部分。 添加字幕和消除技术故障是本地化和质量控制的一部分。 现在让我们看看数据科学如何帮助优化生产的每个阶段。
自动捕捉节目最佳帧的管道: 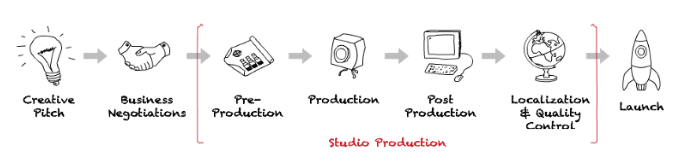
如前所述,预算是前期制作的一部分。 在生产开始之前需要做出许多决定。 例如,拍摄地点。 数据科学被广泛用于分析特定位置的成本影响。 通过巧妙地平衡创意愿景和预算来做出决定。 成本最小化是在不影响内容愿景的情况下完成的。
制作涉及在数月内拍摄数千张照片。 生产将有一个目标,但它需要在特定的限制下进行。 例如,约束条件可以是一个演员只有一个星期可用,一个位置只能在特定的日子里可用,工作人员的工作时间是每天 8 小时,时间限制,如白天拍摄或夜间拍摄,团队可能必须在拍摄之间移动位置。 准备一个包含所有这些限制的拍摄时间表对导演来说可能是一场噩梦。 此处使用数学优化技术,具有目标和约束条件。 这种优化技术将给出一个粗略的拍摄时间表。 该时间表通过调整进一步细化。

后期制作将花费与制作一样多的时间,如果不是更多的话。 数据可视化技术用于检查后期制作中的瓶颈。 可视化技术也用于跟踪后期制作的趋势并将其投射到未来。 进行此预测是为了查看各个团队的工作量并适当地为团队配备人员。
在本地化中,节目被从一种语言配音到另一种语言。 根据数据分析确定需要配音的节目的优先级。 过去证明很受欢迎的配音内容优先。 质量控制将检查音频和视频之间的同步、字幕与声音的同步等问题。质量控制在编码之前和之后进行(将视频压缩为不同比特率以在不同设备上流式传输的过程)。 Netflix 从人工质量控制检查中积累了历史数据。 这些数据包括过去发生的错误、发现错误的视频格式、获得此内容的合作伙伴、内容的类型等。是的,Netflix 发现该类型的错误模式为好吧。 使用这些数据构建了一个机器学习模型,该模型可以预测质量检查的“通过”或“失败”。 如果机器学习算法预测“失败”,那么该资产将通过一轮手动质量检查。
印度聘请数据科学家的顶级公司
流媒体体验质量和 A/B 测试
数据科学被广泛用于确保流媒体体验的质量。 预测网络连接质量以确保流媒体质量。 Netflix 主动预测哪个节目将在特定位置播放,并将内容缓存在附近的服务器中。 当互联网流量较低时,会完成内容的缓存和存储。 这可确保内容在没有缓冲区的情况下进行流式传输,并最大限度地提高客户满意度。每当对现有算法进行更改或提出新算法时,都会广泛使用 A/B 测试。 使用交叉和重复测量等新技术来加速 A/B 测试过程,使用的样本数量非常少。
总而言之,这些是 Netflix 使用数据分析来吸引和敬畏客户的一些方式。 如果您有兴趣深入了解这家了不起的公司如何使用数据科学,请访问他们的研究博客。 他们的博客上有大量文章等待探索。
在即将发布的博客系列中,让我们看看 Instacart 如何利用数据科学和机器学习。 现在您已阅读此博客,请提供您对本文的看法的反馈。 此外,就您希望在我未来的系列中看到的公司提供建议。
学习世界顶尖大学的数据科学课程。 获得行政 PG 课程、高级证书课程或硕士课程,以加快您的职业生涯。