
Шесть наиболее часто используемых структур данных в R
Опубликовано: 2020-02-03Как программист и кодер, вы должны осознавать необходимость переменных для хранения данных. Эти переменные зарезервированы в разных местах памяти для хранения значений. Таким образом, создание переменной означает резервирование места в памяти. Именно эти данные упорядочены по структурам данных для эффективного использования в компьютере.
В отличие от популярных языков программирования, таких как C и Java, в R нет переменных, которые можно объявлять как данные. R имеет R-объекты (структуры данных), которые становятся типом данных требуемой переменной. В R существуют различные типы структур данных. Но сначала давайте разберемся, что такое структуры данных!
Оглавление
Что такое структуры данных?
В R структуры данных — это инструмент, который содержит несколько значений. Обратите внимание, что в программировании на R данные с одиночными значениями практически не используются. Более целесообразно использовать R для объединения нескольких чисел, слов или значений разных типов вместе. Здесь на помощь приходят структуры данных. Они группируют эти несколько значений вместе, чтобы упростить работу с большими объемами данных одновременно.
Структуры данных состоят из типов данных, которые определяют тип данных, хранящихся в zvalue. Например, число 13 — это числовой тип данных , а « тринадцать » — символьный тип данных , также называемый строкой.
Теперь, когда вы разобрались с этим, давайте посмотрим на различные типы структур данных.
Типы структур данных
Чтобы сделать анализ данных и операции простыми и эффективными, в R-программировании существует пять основных типов структур данных.

Давайте подробно рассмотрим каждый из них.
- Вектор
Функция векторов R состоит в том, чтобы сгруппировать несколько значений одного и того же типа данных. Это самый простой тип структуры данных в R, состоящий из двух частей: атомарных векторов и списков. Ниже приведены их общие свойства:
- Тип функции (что это такое)
- Длина функции (количество элементов)
- Атрибут функции (дополнительные произвольные метаданные)
Теперь, когда атомарные векторы предназначены для объединения данных одного и того же типа, списки могут группировать разные типы данных. Существует четыре типа атомарных векторов:
- Числовой тип данных
- Целочисленный тип данных
- Символьный тип данных
- Логический тип данных
Вы можете создавать векторы, используя функцию c().
Например:
![]()
Если вы запустите приведенный выше код, будет создан вектор с именем thisVector, содержащий все числа от 1 до 30.
Чтобы сохранить значения символов в векторе, вам придется использовать двойные кавычки как таковые:
![]()
Хотя вы можете хранить различные типы данных в векторе, рекомендуется этого не делать, так как все значения преобразуются в символьный тип.
- Списки
Как упоминалось выше, списки могут содержать элементы данных любого типа — строки, числа, векторы и даже другой список. Например, вы можете создать список из 80 чисел, 30 слов и 42 векторов. Используемая функция — это list().
Пример:
![]()
Выход:

Поскольку списки могут иметь и другие списки, их иногда называют рекурсивными векторами . Вот почему они сильно отличаются от атомарных векторов.
- Факторы
Проще говоря, фактор — это тип вектора, в котором могут храниться только предопределенные значения. Он в основном используется для хранения категорийных данных. Они классифицируют значения столбцов, такие как «Мужской», «Женский», «ИСТИНА», «ЛОЖЬ» и т. д.
Факторы неоднородны в том смысле, что в них могут храниться как строки, так и целые числа. Для создания факторов используйте функцию factor(). Они очень полезны, когда есть много возможных значений для определенной переменной, и вы знаете их все.
В программировании R векторы символов автоматически преобразуются в вектор. Вы можете использовать stringsAsFactors = FALSE , чтобы подавить это, а затем вручную преобразовать каждый вектор символов в факторы.

- Фреймы данных
Эта структура данных в R используется для представления данных в табличной форме, чтобы упростить анализ данных. Он содержит векторы одинаковой длины, образуя таким образом двумерную структуру. Есть столбцы, содержащие значения переменной, и строки, содержащие набор значений каждого столбца.
Естественно, фреймы данных могут хранить значения различных типов данных. Однако в каждом столбце должно быть одинаковое количество элементов. Например, если столбец 1 содержит 5 элементов, столбец 2 также должен содержать 5 значений.
Фреймы данных имеют некоторые особенности:
- Ни одно имя столбца не должно быть пустым.
- Имя каждой строки должно быть уникальным.
- Во фрейме данных можно хранить данные числового, факторного или символьного типа.
- Все столбцы должны содержать одинаковое количество элементов данных.
Все наборы данных, импортированные в R, автоматически сохраняются в виде фреймов данных.
- Матрицы
Матричная структура данных в R находится где-то между векторами и фреймами данных. Матрицы — это двумерные наборы данных, которые могут содержать элементы только одного типа данных. Вы можете создать матрицу с помощью функции matrix().
Синтаксис : матрица (данные, nrow, ncol, byrow, dimnames)
Здесь,
data = входные элементы в виде вектора
nrow = количество строк
ncol = количество столбцов
byrow = построчное расположение
dimnames = имена столбцов/строк
Пример:
![]()
Выход:
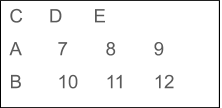
Несмотря на то, что факторы выглядят и ведут себя как векторы символов, на самом деле они являются целыми числами. Чтобы преобразовать факторы в укусы, используйте такие функции, как gsub() и grepl(). Использование nchar() приведет к ошибке.
- Массивы
Массивы — это многомерные матрицы. Матрица является частным случаем массивов в том смысле, что она имеет два измерения. В то время как матрицы обычно используются, массивы очень редки.
Функция для создания массива — это array().
Проверить, является ли объект матрицей или массивом, довольно просто. Просто используйте функцию is.matrix() или is.array().
Упражнения
Вот несколько вопросов, на которые вы можете попытаться ответить теперь, когда вы приобрели достаточно знаний о структурах данных в R.
- Каковы атрибуты фреймов данных?
- Могут ли фреймы данных содержать 0 строк или столбцов?
- Какие существуют типы атомарных векторов в R?
- В чем разница между атомарными векторами и списками?
- Создайте матрицу 4X3 в R.
Присылайте свои ответы нам по электронной почте или пишите их в комментариях ниже!

Заключение
Чтобы адекватно использовать язык R, важно хорошее понимание типов данных, структур данных и того, как они работают. Эти элементы являются предпосылкой всех действий в R. Например, типичная проблема, с которой сталкивается большинство программистов, — это преобразования объектов, от которых можно избавиться при хорошем знании объектов R. Необходимо отметить, что в R все является объектом, а операции выполняются как вызовы функций.
Структуры данных в R можно отсортировать двумя разными способами. Основной метод сортировки структур данных — по их размерности, которая может быть 1, 2 или n размерности, а последующий маршрут — по природе элементов, которые могут быть однородными или разнородными. Каждый из элементов в однородной структуре должен быть одного вида, в то время как в неоднородной структуре допускаются элементы разных видов.
Изучив основы структур данных в R, программирование в R станет намного проще. Структуры данных являются основой R. Шесть наиболее часто используемых структур данных упомянуты выше. Важно помнить о различных характеристиках каждого типа и применять их для анализа данных и выполнения операций.
Если вам интересно узнать больше о больших данных, ознакомьтесь с нашей программой PG Diploma в области разработки программного обеспечения со специализацией в области больших данных, которая предназначена для работающих профессионалов и включает более 7 тематических исследований и проектов, охватывает 14 языков и инструментов программирования, практические занятия. семинары, более 400 часов интенсивного обучения и помощь в трудоустройстве в ведущих фирмах.
Изучайте онлайн-курсы по разработке программного обеспечения в лучших университетах мира. Участвуйте в программах Executive PG, Advanced Certificate Programs или Master Programs, чтобы ускорить свою карьеру.