
Las seis estructuras de datos más utilizadas en R
Publicado: 2020-02-03Como programador y codificador de software, debe ser consciente de la necesidad de variables para almacenar datos. Estas variables se reservan en diferentes ubicaciones de memoria para almacenar valores. Por lo tanto, crear una variable significa reservar algo de espacio en la memoria. Son estos datos los que están organizados por estructuras de datos para ser utilizados de manera eficiente en una computadora.
A diferencia de los lenguajes de programación populares como C y Java, R no tiene variables para declarar como datos. R tiene objetos R (estructuras de datos) que se convierten en el tipo de datos de la variable requerida. Hay varios tipos de estructuras de datos en R. Pero primero, ¡entendamos qué son las estructuras de datos!
Tabla de contenido
¿Qué son las estructuras de datos?
En R, las estructuras de datos son una herramienta que contiene múltiples valores. Tenga en cuenta que en la programación R, los datos con valores únicos casi nunca se utilizan. Es más viable usar R para juntar varios números, palabras o valores de diferentes tipos. Aquí es donde las estructuras de datos entran en escena. Agrupan estos valores múltiples para que sea más fácil trabajar con grandes cantidades de datos a la vez.
Las estructuras de datos se componen de tipos de datos que definen el tipo de datos que se almacenan en zvalue. Por ejemplo, el número 13 es un tipo de dato numérico , mientras que “ trece ” tiene un tipo de dato de carácter , también llamado cadena.
Ahora que entiendes esto, veamos los diferentes tipos de estructuras de datos.
Tipos de estructuras de datos
Para hacer que el análisis de datos y las operaciones sean fáciles y eficientes, existen cinco tipos principales de estructuras de datos en la programación R.

Echemos un vistazo a cada uno de ellos en detalle.
- Vector
La función de los vectores R es agrupar múltiples valores del mismo tipo de datos. Es el tipo más básico de estructura de datos en R y tiene dos partes: vectores atómicos y listas. Las siguientes son sus propiedades comunes:
- Tipo de función (qué es)
- Longitud de la función (número de elementos)
- Atributo de función (metadatos arbitrarios adicionales)
Ahora, mientras que los vectores atómicos están destinados a agrupar el mismo tipo de datos, las listas pueden agrupar diferentes tipos de datos. Hay cuatro tipos de vectores atómicos:
- Tipo de datos numéricos
- Tipo de datos enteros
- Tipo de datos de carácter
- Tipo de datos lógicos
Puede crear vectores usando la función c().
Por ejemplo:
![]()
Si ejecuta el código anterior, se creará un vector con el nombre 'thisVector', que contiene todos los números del 1 al 30.
Para almacenar valores de caracteres en un Vector, deberá usar comillas dobles como tal:
![]()
Si bien puede almacenar diferentes tipos de datos en un vector, se recomienda que no lo haga, ya que todos los valores se convierten en un tipo de carácter.
- Liza
Como se mencionó anteriormente, las listas pueden contener cualquier tipo de elementos de datos: cadenas, números, vectores e incluso otra lista. Por ejemplo, puede crear una lista de 80 números, 30 palabras y 42 vectores. La función a utilizar es una lista().
Ejemplo:
![]()
Producción:

Dado que las listas también pueden tener otras listas, a veces se denominan vectores recursivos . Por eso son muy diferentes de los vectores atómicos.
- factores
En pocas palabras, un factor es un tipo de vector donde solo se pueden almacenar valores predefinidos. Se utiliza principalmente para almacenar datos categóricos. Clasifican los valores de las columnas, como "Masculino", "Femenino", "VERDADERO", "FALSO", etc.
Los factores son heterogéneos en el sentido de que tanto cadenas como enteros pueden almacenarse en ellos. Para crear factores, utilice la función factor(). Son muy útiles cuando hay muchos valores posibles para una determinada variable y los conoces todos.
En la programación R, los vectores de caracteres se convierten automáticamente en vectores. Puede usar stringsAsFactors = FALSE para suprimir esto y luego convertir manualmente cada vector de caracteres en factores.

- Marcos de datos
Esta estructura de datos en R se usa para representar datos en forma tabular para facilitar el análisis de datos. Contiene vectores de igual longitud, formando así una estructura bidimensional. Hay columnas que contienen valores de una variable y filas que contienen un conjunto de valores de cada columna.
Naturalmente, los marcos de datos pueden almacenar valores de diferentes tipos de datos. Sin embargo, cada columna debe tener el mismo número de elementos. Por ejemplo, si la columna 1 tiene 5 elementos, la columna 2 también debe tener 5 valores.
Los marcos de datos tienen algunas características especiales:
- Ningún nombre de columna debe dejarse vacío.
- El nombre de cada fila debe ser único.
- Puede almacenar datos numéricos, de factor o de tipo de carácter en un marco de datos.
- Todas las columnas deben contener el mismo número de elementos de datos.
Todos los conjuntos de datos que se importan en R se almacenan automáticamente como marcos de datos.
- Matrices
La estructura de datos de matriz en R se encuentra en algún lugar entre vectores y marcos de datos. Las matrices son conjuntos de datos bidimensionales que pueden contener elementos del mismo tipo de datos. Puede crear una matriz usando la función matriz ().
Sintaxis : matriz (datos, nrow, ncol, byrow, dimnames)
Aquí,
datos = elementos de entrada como un vector
nrow = número de filas
ncol = número de columnas
byrow = disposición por filas
dimnames = nombres de columnas/filas
Ejemplo:
![]()
Producción:
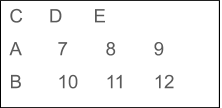
Aunque los factores se ven y se comportan como vectores de caracteres, son, de hecho, números enteros. Para convertir factores en picaduras, use funciones como gsub() y grepl(). Usar nchar() disparará un error.
- arreglos
Los arreglos son matrices multidimensionales. Una matriz es un caso especial de arreglos en el sentido de que tiene dos dimensiones. Si bien las matrices se usan comúnmente, las matrices son muy raras.
La función para crear una matriz es una matriz().
Probar si un objeto es una matriz o una matriz es bastante simple. Simplemente use la función is.matrix() o is.array().
Ejercicios
Aquí hay algunas preguntas que puede intentar responder ahora que ha adquirido suficiente conocimiento sobre las estructuras de datos en R.
- ¿Cuáles son los atributos de los marcos de datos?
- ¿Pueden los marcos de datos contener 0 filas o columnas?
- ¿Cuáles son los diferentes tipos de vectores atómicos en R?
- ¿Cuál es la diferencia entre vectores atómicos y listas?
- Cree una matriz 4X3 en R.
¡Envíenos sus respuestas por correo electrónico o escríbalas en los comentarios a continuación!

Conclusión
Para utilizar el lenguaje R adecuadamente, es importante una comprensión decente de los tipos de datos, las estructuras de datos y cómo funcionan. Estos elementos son la premisa de todas las actividades en R. Por ejemplo, un problema típico que encuentran la mayoría de los programadores son las transformaciones de objetos, que se pueden eliminar con un buen conocimiento de los objetos R. Es imperativo notar que en R todo es un objeto y las operaciones han procedido como llamadas a funciones.
Las estructuras de datos en R se pueden ordenar de dos maneras diferentes. El método principal para clasificar las estructuras de datos es por su dimensionalidad, que puede ser de 1, 2 o n dimensionalidad, y la ruta posterior es por su naturaleza de elementos, que pueden ser homogéneos o heterogéneos. Cada uno de los elementos en una estructura homogénea debe ser de un tipo similar mientras que en una estructura heterogénea se permiten elementos de varios tipos.
Después de haber aprendido los conceptos básicos de las estructuras de datos en R, encontrará que programar en R es mucho más fácil. Las estructuras de datos son los fundamentos de R. Las seis estructuras de datos más utilizadas se mencionan anteriormente. Es importante recordar las diferentes características de cada tipo e implementarlo para analizar datos y realizar sus operaciones.
Si está interesado en saber más sobre Big Data, consulte nuestro programa PG Diploma in Software Development Specialization in Big Data, que está diseñado para profesionales que trabajan y proporciona más de 7 estudios de casos y proyectos, cubre 14 lenguajes y herramientas de programación, prácticas talleres, más de 400 horas de aprendizaje riguroso y asistencia para la colocación laboral con las mejores empresas.
Aprenda cursos de desarrollo de software en línea de las mejores universidades del mundo. Obtenga Programas PG Ejecutivos, Programas de Certificado Avanzado o Programas de Maestría para acelerar su carrera.