
Sześć najczęściej używanych struktur danych w R
Opublikowany: 2020-02-03Jako programista i programista musisz zdawać sobie sprawę z potrzeby przechowywania danych w zmiennych. Te zmienne są zarezerwowane w różnych lokalizacjach pamięci do przechowywania wartości. Zatem utworzenie zmiennej oznacza zarezerwowanie miejsca w pamięci. To właśnie te dane są uporządkowane według struktur danych, aby można je było efektywnie wykorzystywać w komputerze.
W przeciwieństwie do popularnych języków programowania, takich jak C i Java, R nie ma zmiennych, które należy zadeklarować jako dane. R ma obiekty R (struktury danych), które stają się typem danych wymaganej zmiennej. W R istnieją różne typy struktur danych. Ale najpierw zrozummy, czym są struktury danych!
Spis treści
Czym są struktury danych?
W języku R struktury danych są narzędziem, które przechowuje wiele wartości. Zauważ, że w programowaniu w języku R dane z pojedynczymi wartościami są rzadko używane. Bardziej opłacalne jest używanie R do łączenia wielu liczb, słów lub wartości różnych typów. W tym miejscu pojawiają się struktury danych. Grupują te wiele wartości, aby ułatwić jednoczesną pracę z dużymi ilościami danych.
Struktury danych składają się z typów danych, które definiują rodzaj danych przechowywanych w zvalue. Na przykład liczba 13 to numeryczny typ danych , podczas gdy „ trzynaście ” ma typ danych znakowych , zwany także ciągiem.
Teraz, gdy już to znasz, zobaczmy różne typy struktur danych.
Rodzaje struktur danych
Aby analiza danych i operacje były łatwe i wydajne, istnieje pięć głównych typów struktur danych w programowaniu w języku R.

Przyjrzyjmy się szczegółowo każdemu z nich.
- Wektor
Funkcją R Vectors jest grupowanie wielu wartości tego samego typu danych. Jest to najbardziej podstawowy typ struktury danych w języku R i składa się z dwóch części: wektorów atomowych i list. Oto ich wspólne właściwości:
- Rodzaj funkcji (co to jest)
- Długość funkcji (liczba elementów)
- Atrybut funkcji (dodatkowe dowolne metadane)
Teraz, podczas gdy wektory atomowe są przeznaczone do łączenia tego samego typu danych, listy mogą grupować różne typy danych. Istnieją cztery typy wektorów atomowych:
- Numeryczny typ danych
- Typ danych całkowitych
- Typ danych znakowych
- Logiczny typ danych
Możesz tworzyć wektory za pomocą funkcji c().
Na przykład:
![]()
Jeśli uruchomisz powyższy kod, zostanie utworzony wektor o nazwie 'thisVector' zawierający wszystkie liczby od 1 do 30.
Aby przechowywać wartości znaków w wektorze, będziesz musiał użyć podwójnych cudzysłowów jako takich:
![]()
Chociaż możesz przechowywać różne typy danych w wektorze, zaleca się, aby nie konwertować wszystkich wartości na typ znakowy.
- Listy
Jak wspomniano powyżej, Listy mogą zawierać dowolny typ elementów danych — ciągi, liczby, wektory, a nawet inną listę. Na przykład możesz utworzyć listę 80 liczb, 30 słów i 42 wektory. Funkcja, która ma być użyta, to list().
Przykład:
![]()
Wyjście:

Ponieważ Listy mogą mieć również inne listy, są one czasami nazywane wektorami rekurencyjnymi . Dlatego bardzo różnią się od wektorów atomowych.
- Czynniki
Mówiąc najprościej, czynnik to rodzaj wektora, w którym można przechowywać tylko wstępnie zdefiniowane wartości. Służy przede wszystkim do przechowywania danych kategorycznych. Kategoryzują wartości kolumn, takie jak „Mężczyzna”, „Kobieta”, „PRAWDA”, „FAŁSZ” itp.
Czynniki są heterogeniczne w tym sensie, że można w nich przechowywać zarówno łańcuchy, jak i liczby całkowite. Aby utworzyć czynniki, użyj funkcji factor(). Są bardzo przydatne, gdy istnieje wiele możliwych wartości danej zmiennej i znasz je wszystkie.
W programowaniu R wektory znaków są automatycznie konwertowane na wektory. Możesz użyć stringsAsFactors = FALSE , aby to pominąć, a następnie ręcznie przekonwertować każdy wektor znaków na czynniki.

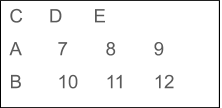
- Ramki danych
Ta struktura danych w języku R służy do przedstawiania danych w formie tabelarycznej, aby ułatwić analizę danych. Zawiera wektory o równej długości, tworząc w ten sposób dwuwymiarową strukturę. Istnieją kolumny zawierające wartości zmiennej oraz wiersze zawierające zestaw wartości każdej kolumny.
Oczywiście ramki danych mogą przechowywać wartości różnych typów danych. Jednak każda kolumna musi mieć taką samą liczbę elementów. Na przykład, jeśli kolumna 1 ma 5 elementów, kolumna 2 również powinna mieć 5 wartości.
Ramki danych mają pewne szczególne cechy:
- Żadne nazwy kolumn nie powinny być puste.
- Nazwa każdego wiersza musi być unikalna.
- W ramce danych można przechowywać dane liczbowe, współczynnikowe lub znakowe.
- Wszystkie kolumny muszą zawierać taką samą liczbę elementów danych.
Wszystkie zestawy danych importowane w R są automatycznie zapisywane jako ramki danych.
- Matryce
Macierzowa struktura danych w języku R stoi gdzieś pomiędzy wektorami a ramkami danych. Macierze to dwuwymiarowe zestawy danych, które mogą zawierać elementy tylko tego samego typu danych. Macierz można utworzyć za pomocą macierzy funkcji ().
Składnia : matrix(data, nrow, ncol, byrow, dimnames)
Tutaj,
dane = elementy wejściowe jako wektor
nrow = liczba rzędów
ncol = liczba kolumn
byrow = układ rzędowy
dimnames = nazwy kolumn/wierszy
Przykład:
![]()
Wyjście:
Chociaż czynniki wyglądają i zachowują się jak wektory znaków, w rzeczywistości są liczbami całkowitymi. Aby przekonwertować czynniki na żądła, użyj funkcji takich jak gsub() i grepl(). Użycie nchar() wygeneruje błąd.
- Tablice
Tablice to wielowymiarowe macierze. Macierz jest szczególnym przypadkiem tablic, ponieważ ma dwa wymiary. Chociaż macierze są powszechnie używane, tablice są bardzo rzadkie.
Funkcją tworzącą tablicę jest array().
Testowanie, czy obiekt jest macierzą czy tablicą, jest dość proste. Wystarczy użyć funkcji is.matrix() lub is.array().
Ćwiczenia
Oto kilka pytań, na które możesz spróbować odpowiedzieć teraz, gdy masz wystarczającą wiedzę na temat struktur danych w R.
- Jakie są atrybuty ramek danych?
- Czy ramki danych mogą zawierać 0 wierszy lub kolumn?
- Jakie są rodzaje wektorów atomowych w R?
- Jaka jest różnica między wektorami atomowymi a listami?
- Utwórz macierz 4X3 w R.
Prześlij nam swoje odpowiedzi e-mailem lub napisz je w komentarzach poniżej!

Wniosek
Aby właściwie wykorzystać język R, ważne jest przyzwoite zrozumienie typów danych, struktur danych i sposobu ich działania. Te elementy są podstawą wszystkich działań w R. Na przykład typowym problemem, z którym spotyka się większość programistów, są przekształcenia obiektów, które można usunąć przy dobrej znajomości obiektów R. Należy zauważyć, że w R wszystko jest obiektem, a operacje przebiegają jak wywołania funkcji.
Struktury danych w języku R można uporządkować na dwa różne sposoby. Główną metodą sortowania struktur danych jest ich wymiarowość, która może mieć wymiar 1, 2 lub n, a dalszą drogą jest ich natura elementów, które mogą być jednorodne lub niejednorodne. Każdy z elementów w strukturze jednorodnej musi być podobnego rodzaju, natomiast w strukturze niejednorodnej dozwolone są elementy różnego rodzaju.
Po zapoznaniu się z podstawami struktur danych w R, programowanie w R będzie znacznie łatwiejsze. Struktury danych to podstawa R. Sześć najczęściej używanych struktur danych jest wymienionych powyżej. Ważne jest, aby pamiętać o różnych cechach każdego typu i wdrożyć je do analizy danych i wykonywania swoich operacji.
Jeśli chcesz dowiedzieć się więcej o Big Data, sprawdź nasz program PG Diploma in Software Development Specialization in Big Data, który jest przeznaczony dla pracujących profesjonalistów i zawiera ponad 7 studiów przypadków i projektów, obejmuje 14 języków programowania i narzędzi, praktyczne praktyczne warsztaty, ponad 400 godzin rygorystycznej pomocy w nauce i pośrednictwie pracy w najlepszych firmach.
Ucz się kursów rozwoju oprogramowania online z najlepszych światowych uniwersytetów. Zdobywaj programy Executive PG, Advanced Certificate Programs lub Masters Programs, aby przyspieszyć swoją karierę.