
Rで最も一般的に使用される6つのデータ構造
公開: 2020-02-03ソフトウェアプログラマーおよびコーダーとして、データを格納するための変数の必要性を認識している必要があります。 これらの変数は、値を格納するために異なるメモリ位置に予約されています。 したがって、変数を作成するということは、メモリ内にいくらかのスペースを予約することを意味します。 コンピュータで効率的に使用されるようにデータ構造によって配置されるのはこのデータです。
CやJavaなどの一般的なプログラミング言語とは異なり、Rにはデータとして宣言される変数がありません。 Rには、必要な変数のデータ型となるRオブジェクト(データ構造)があります。 Rにはさまざまな種類のデータ構造がありますが、まず、データ構造とは何かを理解しましょう。
目次
データ構造とは何ですか?
Rでは、データ構造は複数の値を保持するツールです。 Rプログラミングでは、単一の値を持つデータはほとんど使用されないことに注意してください。 Rを使用して、異なるタイプの複数の数字、単語、または値を一緒にクラブする方が実行可能です。 ここで、データ構造が重要になります。 これらの複数の値をグループ化して、一度に大量のデータを処理しやすくします。
データ構造は、zvalueに格納されるデータの種類を定義するデータ型で構成されます。 たとえば、数値13は数値データ型ですが、「 13 」は文字列とも呼ばれる文字データ型です。
これを把握したので、さまざまなデータ構造タイプを見てみましょう。
データ構造の種類
データの分析と操作を簡単かつ効率的にするために、Rプログラミングには5つの主要なタイプのデータ構造があります。

それぞれを詳しく見ていきましょう。
- ベクター
R Vectorsの機能は、同じデータ型の複数の値をグループ化することです。 これはRの最も基本的なタイプのデータ構造であり、原子ベクトルとリストの2つの部分で構成されています。 それらの一般的なプロパティは次のとおりです。
- 機能の種類(内容)
- 関数の長さ(要素の数)
- 関数の属性(追加の任意のメタデータ)
現在、Atomic Vectorsは同じデータ型をクラブ化することを目的としていますが、リストは異なるデータ型をグループ化できます。 原子ベクトルには次の4つのタイプがあります。
- 数値データ型
- 整数データ型
- 文字データ型
- 論理データ型
関数c()を使用してベクトルを作成できます。
例えば:
![]()
上記のコードを実行すると、「thisVector」という名前のベクトルが作成され、1から30までのすべての数値が含まれます。
ベクトルに文字値を格納するには、次のように二重引用符を使用する必要があります。
![]()
さまざまなタイプのデータをベクトルに格納できますが、すべての値が文字タイプに変換されるため、格納しないことをお勧めします。
- リスト
上記のように、リストには、文字列、数値、ベクトル、さらには別のリストなど、あらゆるタイプのデータ要素を含めることができます。 たとえば、80個の数字、30個の単語、42個のベクトルのリストを作成できます。 使用する関数はlist()です。
例:
![]()
出力:

リストには他のリストも含めることができるため、再帰ベクトルと呼ばれることもあります。 これが、AtomicVectorsとは大きく異なる理由です。
- 要因
簡単に言えば、係数は、事前定義された値のみを格納できる一種のベクトルです。 これは主に、カテゴリデータを格納するために使用されます。 これらは、「男性」、「女性」、「TRUE」、「FALSE」などの列の値を分類します。
因子は、文字列と整数の両方を格納できるという意味で異種です。 因子を作成するには、factor()関数を使用します。 特定の変数に可能な値がたくさんあり、それらすべてを知っている場合に非常に役立ちます。

Rプログラミングでは、文字ベクトルは自動的にベクトルに変換されます。 これを抑制し、各文字ベクトルを手動で因子に変換するために、 stringsAsFactors=FALSEを使用できます。
- データフレーム
Rのこのデータ構造は、データ分析を容易にするために表形式でデータを表すために使用されます。 これには同じ長さのベクトルが含まれているため、2次元構造を形成します。 変数の値を含む列と、各列の値のセットを含む行があります。
当然、データフレームにはさまざまなデータ型の値を格納できます。 ただし、各列には同じ数の要素が必要です。 たとえば、列1に5つの要素がある場合、列2にも5つの値が必要です。
データフレームにはいくつかの特別な特徴があります。
- 列名を空のままにしないでください。
- 各行の名前は一意である必要があります。
- 数値、因数分解、または文字タイプのデータをデータフレームに格納できます。
- すべての列には、同じ数のデータ要素が含まれている必要があります。
Rにインポートされたすべてのデータセットは、データフレームとして自動的に保存されます。
- マトリックス
Rの行列データ構造は、ベクトルとデータフレームの間のどこかにあります。 行列は、同じデータ型の要素のみを含むことができる2次元データセットです。 関数matrix()を使用して行列を作成できます。
構文:matrix(data、nrow、ncol、byrow、dimnames)
ここ、
data=ベクトルとしての入力要素
nrow=行数
ncol=列の数
byrow=行ごとの配置
dimnames=列/行の名前
例:
![]()
出力:
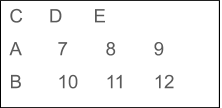
因子は文字ベクトルのように見え、動作しますが、実際には整数です。 因子を刺傷に変換するには、gsub()やgrepl()などの関数を使用します。 nchar()を使用すると、エラーが発生します。
- 配列
配列は多次元行列です。 行列は、2次元を持つという点で、配列の特殊なケースです。 行列が一般的に使用されますが、配列は非常にまれです。
配列を作成する関数はarray()です。
オブジェクトが行列であるか配列であるかをテストするのは非常に簡単です。 is.matrix()またはis.array()関数を使用するだけです。
演習
Rのデータ構造について十分な知識を身に付けたので、答えてみることができるいくつかの質問があります。
- データフレームの属性は何ですか?
- データフレームに0行または0列を含めることはできますか?
- Rの原子ベクトルの種類は何ですか?
- アトミックベクトルとリストの違いは何ですか?
- Rで4X3行列を作成します。
あなたの答えを電子メールで私たちに送るか、下のコメントに書いてください!

結論
R言語を適切に利用するには、データ型、データ構造、およびそれらがどのように機能するかを適切に理解することが重要です。 これらの項目は、Rのすべてのアクティビティの前提です。たとえば、ほとんどのプログラマーが遭遇する一般的な問題は、オブジェクトの変換です。これは、Rオブジェクトに関する十分な知識があれば破棄できます。 Rではすべてがオブジェクトであり、操作は関数呼び出しとして進行していることに注意する必要があります。
Rのデータ構造は、2つの異なる方法で分類できます。 データ構造を分類するための主な方法は、1、2、またはn次元の次元であり、その後のルートは、同種または異種の要素の性質によるものです。 同種構造の要素はすべて類似した種類である必要がありますが、異種構造の要素はさまざまな種類の要素が許可されます。
Rでのデータ構造の基本を学んだ後は、Rでのプログラミングがはるかに簡単になります。 データ構造はRの基本です。最も一般的に使用される6つのデータ構造は上記のとおりです。 各タイプの異なる特性を覚えて、それを実装してデータを分析し、その操作を実行することが重要です。
ビッグデータについて詳しく知りたい場合は、ビッグデータプログラムのソフトウェア開発スペシャライゼーションのPGディプロマをチェックしてください。このプログラムは、働く専門家向けに設計されており、7つ以上のケーススタディとプロジェクトを提供し、14のプログラミング言語とツール、実践的なハンズオンをカバーしています。ワークショップ、トップ企業との400時間以上の厳格な学習と就職支援。
世界のトップ大学からオンラインでソフトウェア開発コースを学びましょう。 エグゼクティブPGプログラム、高度な証明書プログラム、または修士プログラムを取得して、キャリアを早急に進めましょう。