
Pandy łączą ramki danych [2022]
Opublikowany: 2021-01-06Wyobraź sobie, że masz dwa zestawy danych, które musisz połączyć, aby przeprowadzić analizę. Korzystając z SQL, rekordy z dwóch lub więcej tabel w bazie danych można łączyć za pomocą złączeń SQL. Podobnie w Pythonie są opcje łączenia ramek danych. Czym więc jest ramka danych? Ramka danych w Pythonie ma wiele wierszy i kolumn. Jest podobny do tabeli w SQL. Masz bibliotekę oprogramowania pandas do analizy danych w Pythonie. Pandy łączą ramki danych pomagają nam łączyć ramki danych w oparciu o określoną logikę.
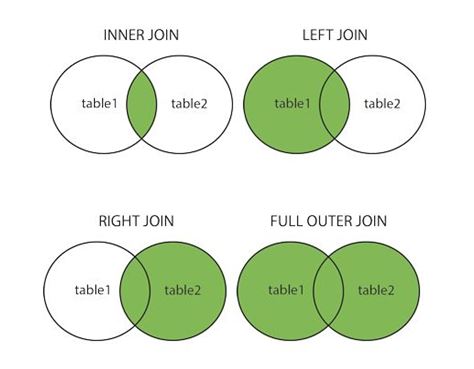
Różne sposoby łączenia ramek danych:
- Złączenie wewnętrzne: Złączenie wewnętrzne jest dość podobne do przecięcia dwóch zestawów. W przypadku sprzężenia wewnętrznego zwracana jest ramka danych zawierająca tylko te wiersze, które mają wspólne właściwości. Dlatego każdy wiersz w dwóch połączonych ramkach danych powinien mieć pasujące wartości kolumn.
- Left Join: Lewe sprzężenie zwraca wszystkie wiersze z lewej ramki danych i tylko pasujące wiersze z prawej ramki danych.
- Prawe sprzężenie: Prawe sprzężenie zwraca wszystkie wiersze z prawej ramki danych i tylko pasujące wiersze z lewej ramki danych.
- Pełne lub zewnętrzne łączenie: pełne łączenie zachowuje wszystkie wiersze zarówno z lewej ramki danych, jak i prawej ramki danych.
 Źródło
Źródło
Przyjrzyjmy się teraz funkcjom obecnym w Pandach do łączenia ramek lub serii danych.
Spis treści
Funkcje w Pandach
1. Dołącz do funkcji
Jak już przeczytaliśmy, Python ma wiele funkcji podobnych do SQL, dostępnych do łączenia danych. Ramki danych mają indeks, który działa jak adres. Zwykle indeksy wierszy są określane jako indeks, podczas gdy kolumny są adresowane przez nazwy kolumn. Operacja Join umożliwia scalenie wszystkich kolumn z dwóch ramek danych. Możesz zmienić nazwę lewej i prawej kolumny, aktualizując parametry „lsuffix” i „rsuffix”. Masz możliwość wyboru sposobu łączenia, aktualizując parametr „jak”.
2. Funkcja łączenia
Funkcja scalania jest bardzo podobna do operacji łączenia. Otrzymujesz jednak elastyczną kontrolę podczas łączenia wszystkich kolumn z dwóch ramek danych. Możesz użyć on = Nazwa kolumny, aby scalić ramki danych we wspólnej kolumnie. Możesz zaktualizować left_on = Nazwa kolumny lub right_on = Nazwa kolumny, aby wyrównać tabele, używając jako kluczy kolumn z lewej lub prawej ramki danych. Wybranie left_index = True lub right_index = True pozwala na użycie etykiet wierszy z lewej lub prawej ramki danych jako kluczy łączenia.
Składnia:
DataFrame.merge( self , right , how='left' , on=None , left_on=None ,
right_on=None , left_index=False , right_index=False , sort=False , suffixes =('_x' , '_y') , copy=True , indicator=False , validate=None )
Przeczytaj: Pytania do wywiadu z Pandami

3. Funkcja Concat
Korzystając z funkcji Concat, możesz łączyć dane w kolumnach lub wierszach według własnego wyboru. Możesz ustawić logikę łączenia (lewe/prawe/wewnętrzne/pełne łączenie) na jednej z dwóch osi. Otrzymasz również opcję sprawdzenia, czy nowa połączona oś ma zduplikowane wartości, używając opcji Verify_integrity. Jeśli nie określono wartości indeksu na osi konkatenacji, wynikowa oś zostanie oznaczona jako 0,1,… n-1. Parametr keys umożliwia tworzenie hierarchicznego indeksowania przy użyciu przekazanych kluczy.
Składnia
pandas.concat( objs , oś=0 , join='left' , join_axes=Brak ,
ignore_index=False , klucze=Brak , poziomy=Brak , nazwy=Brak ,
Verify_integrity=False , sort=Brak , copy=True )
Przeczytaj: Algorytm struktury danych w Pythonie
Zawijanie
Jak widzieliśmy w pandas.DataFrame, funkcje merge i join służą do łączenia ramek danych pracujących na kolumnach. Istnieje również możliwość zmiany nazw kolumn na podstawie podanego przyrostka. Funkcja scalania zapewnia większą elastyczność w przypadku wyrównania rzędowego. Wręcz przeciwnie, funkcja Concat pand może działać na wierszach lub kolumnach.
Podczas korzystania z funkcji Concat nie jest dokonywana zmiana nazw kolumn. Pandas łączenie ramek danych jest istotną funkcją, gdy musimy połączyć dwie ramki danych. Scalanie dwóch ramek danych przy użyciu określonych warunków pomaga w przygotowaniu danych potrzebnych do analizy i innych zadań. Tak więc dla biblioteki oprogramowania pandy łączenie ramek danych jest integralną funkcją.
Czy chcesz dowiedzieć się więcej o różnych funkcjach dostępnych w pandach i zagłębić się w analizę danych? Możesz sprawdzić PG Diploma in Data Science oferowany przez upGrad. Kursy są prowadzone przez ekspertów branżowych i pomogą Ci dowiedzieć się więcej o eksploracyjnej analizie danych, różnych technikach wizualizacji danych i algorytmach uczenia maszynowego. Rozpocznij swoją karierę w dziedzinie analityki danych i uczenia maszynowego z upGrad.
Jakie są rodzaje stawów w Pandach?
Biblioteka Pandas udostępnia cztery rodzaje różnych złączeń do łączenia ramek danych. Te sprzężenia są następujące — sprzężenie wewnętrzne jest najbardziej podstawowym sprzężeniem do łączenia ramek danych. Sprzężenie wewnętrzne zwraca ramkę danych zawierającą tylko te wiersze, które mają wspólne właściwości. Dlatego obie połączone ramki danych powinny mieć wspólne wartości. Sprzężenie pełne lub zewnętrzne zwraca wszystkie wiersze z lewej i prawej ramki danych. Innymi słowy, zapewnia połączenie obu ramek danych. Lewe sprzężenie zwraca wszystkie wiersze lewej ramki danych wraz z pasującymi wierszami prawej ramki danych. Prawe sprzężenie jest dokładnie przeciwieństwem lewego sprzężenia. Zwraca wszystkie wiersze prawej ramki danych wraz z pasującymi wierszami lewej ramki danych.
Jakie są różne sposoby łączenia wierszy lub kolumn?
Wiersze lub kolumny dwóch ramek danych można łączyć w następujący sposób: 1. Łączenie DataFrame za pomocą .concat() — jest to najprostszy sposób łączenia dwóch wierszy lub kolumn, w których używamy funkcji „.concat()”. 2. Konkatenowanie DataFrame poprzez ustawienie logiki na osiach - W tej metodzie definiujemy inną logikę na osiach. Oto sposoby ustawiania osi: weź połączenie (join = zewnętrzne), weź przecięcie (join = wewnętrzne), przy użyciu określonego indeksu. 3. Łączenie DataFrame za pomocą .append() - funkcja „.append()” jest używana tuż przed funkcją „.concat()” i łączy się wzdłuż osi = 0. 4. Łączenie DataFrame przez ignorowanie indeksów - W tej metodzie , ignorujemy bezsensowne indeksy i dołączamy ramkę danych. Używamy ignore_index jako argumentu do ignorowania nakładających się indeksów.
Co wiesz o funkcji scalania?
Funkcja scalania działa na dwóch ramkach danych, aby scalić wiersze lub kolumny. Jest to operacja łączenia o dużej ilości pamięci i przypomina relacyjne bazy danych. Możesz użyć on = Nazwa kolumny, aby scalić ramki danych we wspólnej kolumnie.
Można zaktualizować left_on = Nazwa kolumny lub right_on = Nazwa kolumny, aby wyrównać tabele, używając jako kluczy kolumn z lewej lub prawej ramki danych. Wybranie left_index = True lub right_index = True pozwala na użycie etykiet wierszy z lewej lub prawej ramki danych jako kluczy łączenia.