
Wizualizacja danych w programowaniu R: najlepsze wizualizacje dla początkujących do nauki
Opublikowany: 2020-01-22Każdy, kto zajmuje się analizą danych, niewątpliwie słyszał, a nawet miał do czynienia z wizualizacją danych. Jeśli jesteś nowicjuszem, dowiedz się wszystkiego o wizualizacji danych tutaj. Wizualizacja danych jest kluczową częścią analizy danych i odnosi się do wizualnej reprezentacji danych w postaci wykresu, wykresu, słupka lub dowolnego innego formatu. Zasadniczo celem wizualizacji danych jest przedstawienie lub zobrazowanie relacji między danymi a obrazami.
Rozwój Big Data sprawił, że naukowcy zajmujący się danymi i analitycy danych muszą uprościć spostrzeżenia uzyskane za pomocą wizualnych reprezentacji, aby ułatwić zrozumienie. Ponieważ naukowcy i analitycy danych pracują teraz z dużymi ilościami złożonych i obszernych zestawów danych, wizualizacja danych stała się bardziej kluczowa niż kiedykolwiek. Wizualizacja danych oferuje wizualne lub obrazkowe podsumowanie dostępnych danych, ułatwiając tym samym specjalistom ds. Data Science i Big Data zidentyfikowanie ukrytych wzorców i trendów w danych.
Dzięki wizualizacji danych specjaliści z dziedzin Data Science i Big Data nie muszą intensywnie przeglądać tysięcy wierszy i kolumn w arkuszu kalkulacyjnym — mogą odwoływać się do wizualizacji, aby zrozumieć, gdzie w zbiorze danych znajdują się wszystkie istotne informacje.
Chociaż mamy wiele samodzielnych i sprytnych narzędzi do wizualizacji danych, takich jak Tableau, QlikView i d3.js, dzisiaj porozmawiamy o wizualizacji danych w języku programowania R. R jest doskonałym narzędziem do wizualizacji danych, ponieważ zawiera wiele wbudowanych funkcji i bibliotek, które pokrywają prawie wszystkie potrzeby wizualizacji danych.
W tym poście omówimy 8 narzędzi R Data Visualization używanych przez naukowców i analityków danych na całym świecie!
Spis treści
8 najlepszych narzędzi do wizualizacji danych
1. Wykres słupkowy
Wszyscy znają wykresy słupkowe, których nauczano w szkołach i na uczelniach. W wizualizacji danych R z wykresem słupkowym koncepcja i cel pozostają takie same – chodzi o pokazanie porównania dwóch lub więcej zmiennych. Wykresy słupkowe przedstawiają porównanie skumulowanej sumy w różnych grupach. Standardowa składnia tworzenia wykresu słupkowego w R to:
wykres słupkowy(H,xlab,ylab,main, names.arg,col)
Istnieje wiele różnych typów wykresów słupkowych, które służą wyjątkowym celom. Podczas gdy poziome i pionowe wykresy słupkowe są standardowymi formatami, R może tworzyć na wykresie zarówno poziome, jak i pionowe słupki. Poza tym R oferuje również skumulowany wykres słupkowy, który pozwala wprowadzić różne zmienne do każdej kategorii. W R funkcja barplot() służy do tworzenia wykresów słupkowych.
2. Histogram
Histogramy działają najlepiej z dokładnością lub liczbami w R. Ta reprezentacja dzieli dane na przedziały (przedziały) i przedstawia rozkład częstotliwości tych przedziałów. Możesz dostosować pojemniki i zobaczyć, jaki ma to wpływ na wzór wizualizacji. Standardowa składnia tworzenia histogramu przy użyciu języka R to:
hist(v,main,xlab,xlim,ylim,breaks,col,border)
Histogramy zapewniają oszacowanie prawdopodobieństwa zmiennej, czyli okres czasu przed zakończeniem projektu. Każdy słupek na histogramie reprezentuje wysokość liczby wartości obecnych w tym zakresie. Język R używa funkcji hist() do tworzenia histogramów.
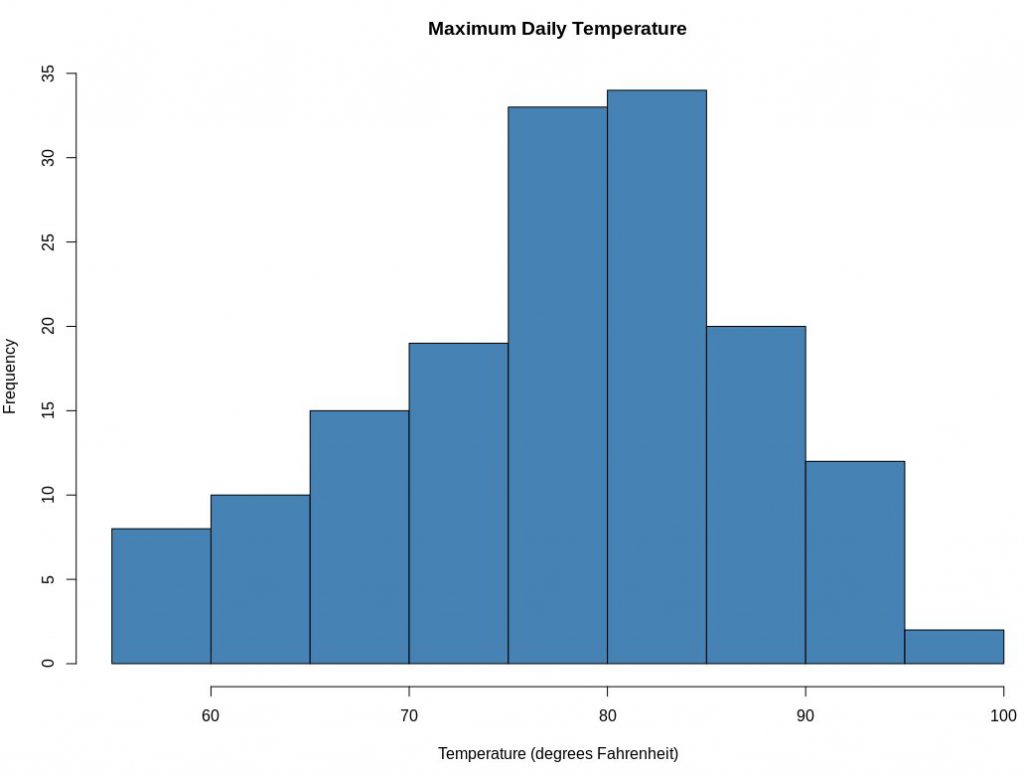
Źródło
3. Działka pudełkowa
Wykres pudełkowy przedstawia pięć statystycznie istotnych liczb, w tym minimum, 25 percentyl, medianę, 75 percentyl i maksimum. Chociaż wykres pudełkowy ma wiele podobieństw z wykresem słupkowym, wykres pudełkowy zapewnia wizualizację danych zmiennych jakościowych i ciągłych, zamiast skupiać się tylko na danych kategorialnych. Standardowa składnia tworzenia wykresu pudełkowego w R to:
boxplot(x, data, notch, varwidth, name, main)
R tworzy wykresy pudełkowe za pomocą funkcji boxplot(). Ta funkcja może przyjąć dowolną liczbę wektorów numerycznych i narysować wykres pudełkowy dla każdego wektora. Wykresy pudełkowe najlepiej nadają się do wizualizacji rozprzestrzeniania się danych i odpowiedniego wyprowadzania na ich podstawie wniosków.
Ucz się kursów nauki o danych z najlepszych światowych uniwersytetów. Zdobywaj programy Executive PG, Advanced Certificate Programs lub Masters Programs, aby przyspieszyć swoją karierę.
4. Wykres punktowy
Wykresy punktowe przedstawiają liczne punkty na płaszczyźnie kartezjańskiej, gdzie każdy punkt reprezentuje wartości dwóch zmiennych. Możesz wybrać jedną zmienną na osi poziomej i drugą na osi pionowej. Funkcja wykresu punktowego polega na śledzeniu dwóch zmiennych ciągłych w czasie. W R funkcja plot() służy do tworzenia wykresu punktowego. Standardowa składnia tworzenia wykresu rozrzutu w języku R to:
działka(x, y, main, xlab, ylab, xlim, ylim, osie)
Wykresy punktowe świetnie sprawdzają się w sytuacjach, gdy chcesz uniknąć dezinformacji w wizualizacji. Najlepiej nadają się do prostej kontroli danych.

5. Korelogram
Korelogram lub macierz korelacji analizuje relacje między każdą parą zmiennych liczbowych w zestawie danych. Zapewnia szybki przegląd pełnego zestawu danych. Korelogramy mogą również podkreślać wielkość korelacji między zestawami danych w różnych momentach.
W R pakiet GGally jest idealny do budowania korelogramów. Aby utworzyć klasyczny korelogram (z wykresem punktowym, współczynnikiem korelacji i rozkładem zmiennych), możesz użyć funkcji ggpairs(). Kolejnym świetnym pakietem do tworzenia korelogramów jest pakiet corrgram. W tym pakiecie możesz wybrać, co ma być wyświetlane (wykres punktowy, wykres kołowy, tekst, elipsa itp.) w górnej, dolnej i po przekątnej części reprezentacji. Aby utworzyć korelogram za pomocą pakietu corrgram w następujący sposób:
corrgram(x, order = , panel=, lower.panel=, upper.panel=, text.panel=, diag.panel=)
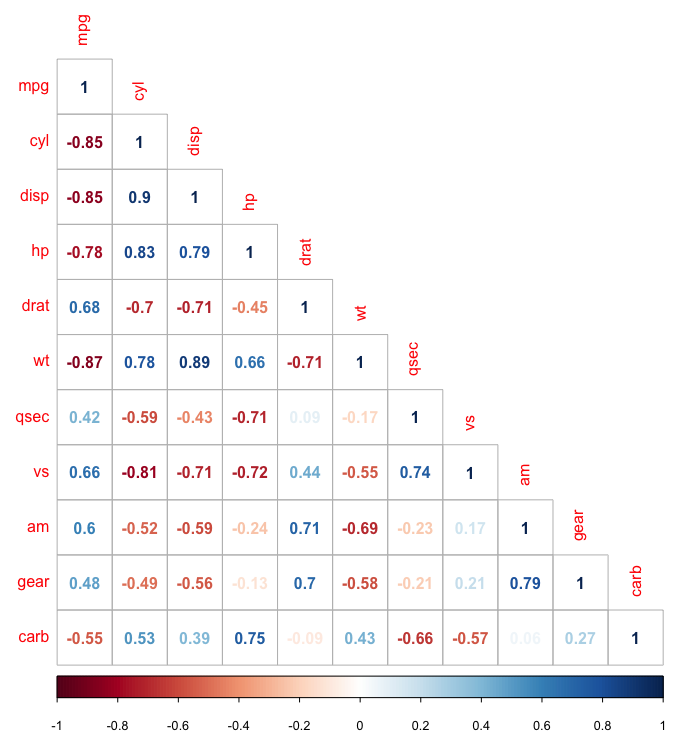
Źródło
6. Mapa cieplna
Mapy cieplne to graficzna reprezentacja danych, w której poszczególne wartości zawarte w macierzy są reprezentowane za pomocą różnych kolorów. Mapy cieplne umożliwiają wykonanie eksploracyjnej analizy danych z dwoma wymiarami jako osią, a intensywność koloru przedstawia trzeci wymiar. W R funkcja heatmap() służy do tworzenia map ciepła. Zanim utworzysz mapę cieplną, musisz przekonwertować zestaw danych na format macierzy przy użyciu następującego kodu:
> heatmap(as.matrix(mtcars))
Istnieją trzy opcje budowania interaktywnych map ciepła w R:
- plotly – Dzięki plotly możesz przekonwertować dowolną mapę cieplną stworzoną za pomocą ggplot2 w interaktywną mapę cieplną.
- d3heatmap – Ten pakiet używa tej samej składni, co funkcja bazowa R heatmap() do tworzenia interaktywnych map ciepła.
- heatmaply – jest to najbardziej konfigurowalny ze wszystkich pakietów R. Pozwala wybrać wiele różnych opcji dostosowywania.
7. Sześciokątne łączenie
Sześciokątny binning to rodzaj dwuwymiarowego histogramu, który najlepiej nadaje się do wizualizacji struktury w zestawach danych z dużą liczbą n. Podstawową koncepcją jest tutaj:
- Regularna siatka sześciokątów umieszcza na płaszczyźnie XY zbiór [zakres(x), zakres(y)].
- Liczba punktów przypadających na każdy sześciokąt jest zliczana i przechowywana w strukturze danych.
- Sześciokąty o liczbie > 0 są wykreślane za pomocą wykresu kolorów lub zmieniając promień sześciokąta proporcjonalnie do liczby.
Przeczytaj: Różne typy naukowców zajmujących się danymi
Działający tutaj algorytm jest zarówno szybki, jak i skuteczny w wyświetlaniu struktury zbiorów danych z n ≥ 106. W R pakiet hexbin zawiera zestaw funkcji do tworzenia, manipulowania i wykreślania sześciokątnych pojemników. Ten pakiet integruje podstawową koncepcję sześciokątnego binningu z wieloma innymi funkcjami do wykonywania wygładzania dwuwymiarowego, znajdowania przybliżonej mediany dwuwymiarowej i badania różnicy między dwoma zestawami przedziałów w tej samej skali.
8. Mozaikowa fabuła
W programowaniu R wykres mozaikowy przydaje się podczas wizualizacji danych z tabeli kontyngencji lub dwukierunkowej tabeli częstości. Jest to graficzna reprezentacja dwukierunkowej tabeli kontyngencji, która reprezentuje związek między dwiema lub więcej zmiennymi kategorialnymi. Wykres mozaikowy R tworzy prostokąt, w którym wysokość reprezentuje wartość proporcjonalną. Standardowa składnia tworzenia wykresu mozaikowego w R to:
mosaicplot(x, kolor = NULL, main = „Tytuł”)
Zasadniczo wykres mozaikowy jest wielowymiarowym rozszerzeniem wykresu kręgosłupa , który podsumowuje warunkowe prawdopodobieństwa współwystępowania wartości kategorycznych na liście rekordów o tej samej długości. Pomaga wizualizować dane z dwóch lub więcej zmiennych jakościowych.
Przeczytaj: Wynagrodzenie z analizy danych i analityki
Zawijanie
Ponieważ wszystkie sektory branży nadal polegają na Big Data w celu promowania biznesu i marketingu opartego na danych, znaczenie wizualizacji danych również wzrośnie jednocześnie. Ponieważ techniki wizualizacji, takie jak wykresy i wykresy, są znacznie wydajniejszymi narzędziami do wizualizacji danych niż tradycyjne arkusze kalkulacyjne i archaiczne raporty, narzędzia R Data Visualization stale zyskują popularność w kręgach Data Science i Big Data.
Jeśli chcesz dowiedzieć się więcej o data science, sprawdź nasz dyplom PG w dziedzinie Data Science, który jest stworzony dla pracujących profesjonalistów i oferuje ponad 10 studiów przypadków i projektów, praktyczne warsztaty praktyczne, mentoring z ekspertami branżowymi, 1 na 1 z mentorzy branżowi, ponad 400 godzin nauki i pomocy w pracy z najlepszymi firmami.
Którego powinienem się nauczyć - R czy Python?
Python i R są uważane za dość proste do nauczenia. Python został stworzony z myślą o rozwoju oprogramowania. Jeśli masz wcześniejsze doświadczenie z Javą lub C++, Python może być dla ciebie łatwiejszy niż R. Z drugiej strony, może być nieco łatwiejszy, jeśli masz doświadczenie w statystykach. Łatwa do zrozumienia składnia Pythona ułatwia naukę. R ma na początku wyższą krzywą uczenia się, ale staje się znacznie łatwiejsza, gdy będziesz ją ćwiczyć.
Czy Tableau jest najlepszym narzędziem do wizualizacji danych?
Tableau jest jednym z najpopularniejszych narzędzi do wizualizacji danych na rynku z dwóch powodów: jest zarówno prosty w użyciu, jak i dość potężny. Program potrafi importować dane z setek źródeł i generować dziesiątki stylów wizualizacji, w tym wykresy, mapy i wiele innych.
Jakie są różnice między R i RStudio?
R to język programowania do obliczeń statystycznych, a RStudio to statystyczne środowisko programowania, które wykorzystuje R. Możesz zbudować program w R i uruchomić go bez użycia innego oprogramowania. Jednak, aby program RStudio działał efektywnie, musi być używany w połączeniu z R.