
Visualisation des données dans la programmation R : meilleures visualisations pour les débutants à apprendre
Publié: 2020-01-22Toute personne impliquée dans l'analyse de données a sans aucun doute entendu parler et même traité de la visualisation de données. Si vous êtes un débutant, apprenez tout sur la visualisation des données ici. La visualisation des données est une partie cruciale de l'analyse des données et fait référence à la représentation visuelle des données sous la forme d'un graphique, d'un tableau, d'une barre ou de tout autre format. Essentiellement, le but de la visualisation des données est de représenter ou de décrire la relation entre les données et les images.
L'essor du Big Data a obligé les Data Scientists et les Data Analysts à simplifier les informations obtenues via des représentations visuelles pour en faciliter la compréhension. Étant donné que les scientifiques et les analystes des données travaillent désormais avec de grandes quantités d'ensembles de données complexes et volumineux, la visualisation des données est devenue plus essentielle que jamais. La visualisation des données offre un résumé visuel ou illustré des données disponibles, ce qui permet aux professionnels de la science des données et du Big Data d'identifier plus facilement les modèles et tendances cachés dans les données.
Grâce à la visualisation des données, les professionnels des domaines de la science des données et du Big Data n'ont pas besoin de parcourir en profondeur des milliers de lignes et de colonnes dans une feuille de calcul - ils peuvent se référer à la visualisation pour comprendre où se trouvent toutes les informations pertinentes dans un ensemble de données.
Bien que nous ayons de nombreux outils de visualisation de données autonomes et astucieux comme Tableau, QlikView et d3.js, nous allons aujourd'hui parler de visualisation de données dans le langage de programmation R. R est un excellent outil pour la visualisation de données car il est livré avec de nombreuses fonctions et bibliothèques intégrées qui couvrent presque tous les besoins de visualisation de données.
Dans cet article, nous discuterons des outils de visualisation de données 8 R utilisés par les Data Scientists et les Analystes du monde entier !
Table des matières
Top 8 des outils de visualisation de données
1. Graphique à barres
Tout le monde connaît les diagrammes à barres qui ont été enseignés dans les écoles et les collèges. Dans R Data Visualization avec un graphique à barres, le concept et l'objectif restent les mêmes - il s'agit de montrer une comparaison entre deux variables ou plus. Les diagrammes à barres illustrent la comparaison entre le total cumulé de divers groupes. La syntaxe standard pour créer un graphique à barres dans R est :
barplot(H,xlab,ylab,main,names.arg,col)
Il existe de nombreux types de graphiques à barres qui ont des objectifs uniques. Alors que les graphiques à barres horizontales et verticales sont les formats standard, R peut créer des barres horizontales et verticales dans un graphique. En outre, R propose également un graphique à barres empilées qui vous permet d'introduire différentes variables dans chaque catégorie. Dans R, le barplot() est utilisé pour créer des graphiques à barres.
2. Histogramme
Les histogrammes fonctionnent mieux avec des nombres précis ou dans R. Cette représentation divise les données en bacs (pauses) et décrit la distribution de fréquence de ces bacs. Vous pouvez modifier les bacs et voir quel effet cela a sur le modèle de visualisation. La syntaxe standard pour créer un histogramme à l'aide de R est :
hist(v,main,xlab,xlim,ylim,breaks,col,border)
Les histogrammes fournissent une estimation de probabilité d'une variable, c'est-à-dire la période de temps avant l'achèvement d'un projet. Chaque barre d'un histogramme représente la hauteur du nombre de valeurs présentes dans cette plage. Le langage R utilise la fonction hist() pour créer des histogrammes.
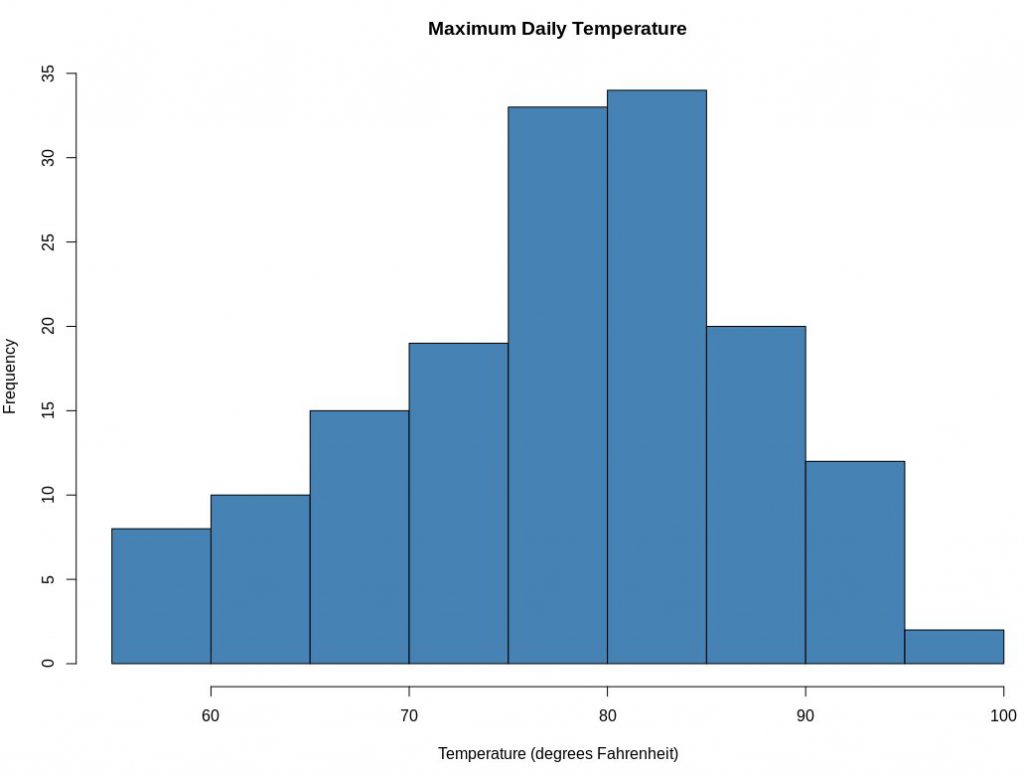
La source
3. Boîte à moustaches
Une boîte à moustaches représente cinq nombres statistiquement significatifs, notamment le minimum, le 25e centile, la médiane, le 75e centile et le maximum. Bien qu'une boîte à moustaches partage de nombreuses similitudes avec un graphique à barres, une boîte à moustaches fournit une visualisation des données variables catégorielles et continues, au lieu de se concentrer uniquement sur les données catégorielles. La syntaxe standard pour créer un boxplot dans R est :
boxplot(x, data, notch, varwidth, names, main)
R crée des boîtes à moustaches à l'aide de la fonction boxplot(). Cette fonction peut prendre n'importe quel nombre de vecteurs numériques et dessiner une boîte à moustaches pour chaque vecteur. Les boîtes à moustaches sont les mieux adaptées pour visualiser la propagation des données et dériver en conséquence des inférences basées sur celles-ci.
Apprenez des cours de science des données dans les meilleures universités du monde. Gagnez des programmes Executive PG, des programmes de certificat avancés ou des programmes de maîtrise pour accélérer votre carrière.
4. Nuage de points
Les diagrammes de dispersion représentent de nombreux points dans le plan cartésien, où chaque point représente les valeurs de deux variables. Vous pouvez choisir une variable sur l'axe horizontal et la seconde sur l'axe vertical. La fonction d'un nuage de points est de suivre deux variables continues dans le temps. Dans R, la fonction plot() est utilisée pour créer un nuage de points. La syntaxe standard pour créer un nuage de points dans R est :
plot(x, y, main, xlab, ylab, xlim, ylim, axes)
Les nuages de points sont parfaits pour les cas où vous souhaitez éviter la désinformation dans la visualisation. Ceux-ci sont les mieux adaptés à une inspection simple des données.
5. Corrélogramme
Un corrélogramme, ou matrice de corrélation, analyse la relation entre chaque paire de variables numériques dans un ensemble de données. Il fournit un aperçu rapide de l'ensemble de données complet. Les corrélogrammes peuvent également mettre en évidence la quantité de corrélation entre les ensembles de données à différents moments.

Dans R, le package GGally est idéal pour construire des corrélogrammes. Pour créer un corrélogramme classique (avec un nuage de points, un coefficient de corrélation et une distribution variable), vous pouvez utiliser la fonction ggpairs(). Un autre excellent package pour créer des corrélogrammes est le package corrgram. Dans ce package, vous pouvez choisir ce qu'il faut afficher (nuage de points, camembert, texte, ellipse, etc.) dans la partie supérieure, inférieure et diagonale de la représentation. Pour créer un corrélogramme en utilisant le package corrgram comme ceci :
corrgram(x, order = , panel=, lower.panel=, upper.panel=, text.panel=, diag.panel=)
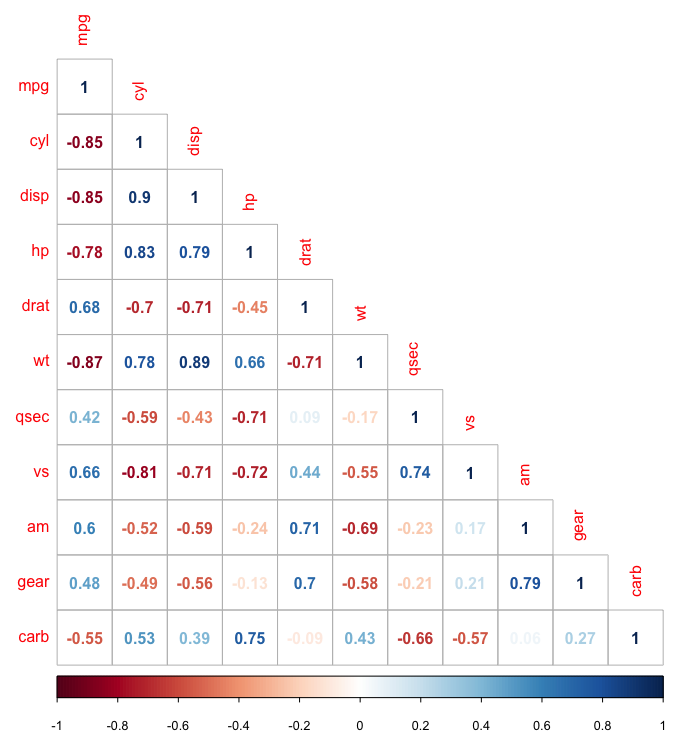
La source
6. Carte thermique
Les cartes thermiques sont des représentations graphiques de données dans lesquelles les valeurs individuelles contenues dans une matrice sont représentées par différentes couleurs. Les cartes thermiques vous permettent d'effectuer une analyse exploratoire des données avec deux dimensions comme axe, et l'intensité de la couleur représente la troisième dimension. Dans R, la fonction heatmap() est utilisée pour créer des cartes thermiques. Avant de créer une carte thermique, vous devez convertir l'ensemble de données au format matriciel à l'aide du code suivant :
> heatmap(as.matrix(mtcars))
Il existe trois options pour créer des cartes thermiques interactives dans R :
- plotly – Avec plotly, vous pouvez convertir n'importe quelle carte thermique créée avec ggplot2 en une carte thermique interactive.
- d3heatmap – Ce package utilise la même syntaxe que la fonction de base R heatmap() pour créer des cartes thermiques interactives.
- heatmaply - C'est le plus personnalisable de tous les packages R. Il vous permet d'opter pour de nombreux types d'options de personnalisation.
7. Regroupement hexagonal
Le regroupement hexagonal est un type d'histogramme bivarié le mieux adapté pour visualiser la structure dans des ensembles de données avec un grand n. Le concept sous-jacent ici est le suivant :
- Une grille régulière d'hexagones parsème le plan XY sur l'ensemble [range(x), range(y)].
- Le nombre de points tombant dans chaque hexagone est compté et stocké dans une structure de données.
- Les hexagones ayant un compte > 0 sont soit tracés en utilisant un dégradé de couleurs, soit en faisant varier le rayon de l'hexagone proportionnellement aux comptes.
Lire : Différents types de data scientists
L'algorithme à l'œuvre ici est à la fois rapide et efficace pour afficher la structure des ensembles de données avec n ≥ 106. Dans R, le package hexbin contient un assortiment de fonctions pour créer, manipuler et tracer des bacs hexagonaux. Ce package intègre le concept de base de regroupement hexagonal avec de nombreuses autres fonctions pour exécuter le lissage bivarié, trouver une médiane bivariée approximative et étudier la différence entre deux ensembles de bacs sur la même échelle.
8. Tracé en mosaïque
Dans la programmation R, le diagramme en mosaïque est pratique lors de la visualisation des données du tableau de contingence ou du tableau de fréquence bidirectionnel. Il s'agit d'une représentation graphique d'un tableau de contingence à deux entrées qui représente la relation entre deux ou plusieurs variables catégorielles. Le diagramme en mosaïque R crée un rectangle où la hauteur représente la valeur proportionnelle. La syntaxe standard pour créer un diagramme en mosaïque dans R est :
mosaïqueplot (x, couleur = NULL, main = "Titre")
Essentiellement, un diagramme en mosaïque est une extension multidimensionnelle d'un diagramme de colonne vertébrale qui résume les probabilités conditionnelles de cooccurrence des valeurs catégorielles dans une liste d'enregistrements ayant la même longueur. Il aide à visualiser les données de deux ou plusieurs variables qualitatives.
Lire : Salaire en science des données et analytique
Emballer
Alors que tous les secteurs de l'industrie continuent de s'appuyer sur le Big Data pour promouvoir les activités et le marketing axés sur les données, l'importance de la visualisation des données augmentera également simultanément. Étant donné que les techniques de visualisation telles que les tableaux et les graphiques sont des outils beaucoup plus efficaces pour la visualisation des données que les feuilles de calcul traditionnelles et les rapports archaïques, les outils de visualisation des données R gagnent en popularité dans les cercles de la science des données et du Big Data.
Si vous êtes curieux d'en savoir plus sur la science des données, consultez notre diplôme PG en science des données qui est créé pour les professionnels en activité et propose plus de 10 études de cas et projets, des ateliers pratiques, un mentorat avec des experts de l'industrie, 1-on-1 avec mentors de l'industrie, plus de 400 heures d'apprentissage et d'aide à l'emploi avec les meilleures entreprises.
Lequel dois-je apprendre - R ou Python ?
Python et R sont tous deux considérés comme assez simples à apprendre. Python a été créé avec le développement de logiciels à l'esprit. Si vous avez une expertise préalable avec Java ou C++, Python peut vous venir plus facilement que R. R, en revanche, peut être un peu plus facile si vous avez une formation en statistiques. La syntaxe facile à comprendre de Python facilite son apprentissage. R a une courbe d'apprentissage plus élevée au début, mais cela devient considérablement plus facile à mesure que vous continuez à le pratiquer.
Tableau est-il le meilleur outil de visualisation de données ?
Tableau est l'un des outils de visualisation de données les plus populaires sur le marché pour deux raisons : il est à la fois simple à utiliser et assez puissant. Le programme peut importer des données à partir de centaines de sources et générer des dizaines de styles de visualisation, notamment des graphiques, des cartes et bien plus encore.
Quelles sont les différences entre R et RStudio ?
R est un langage de programmation pour le calcul statistique, et RStudio est un environnement de programmation statistique qui exploite R. Vous pouvez créer un programme dans R et l'exécuter sans utiliser d'autre logiciel. Cependant, pour que RStudio fonctionne efficacement, il doit être utilisé conjointement avec R.