
Visualización de datos en la programación R: Visualizaciones principales para que los principiantes aprendan
Publicado: 2020-01-22Cualquier persona involucrada en el análisis de datos sin duda ha oído hablar e incluso se ha ocupado de la visualización de datos. Si es un novato, aprenda todo sobre la visualización de datos aquí. La visualización de datos es una parte crucial del análisis de datos y se refiere a la representación visual de los datos en forma de gráfico, tabla, barra o cualquier otro formato. Esencialmente, el propósito de la visualización de datos es representar o representar la relación entre los datos y las imágenes.
El auge de Big Data ha obligado a los científicos y analistas de datos a simplificar los conocimientos obtenidos a través de representaciones visuales para facilitar la comprensión. Dado que los analistas y científicos de datos ahora trabajan con grandes cantidades de conjuntos de datos complejos y voluminosos, la visualización de datos se ha vuelto más fundamental que nunca. La visualización de datos ofrece un resumen visual o pictórico de los datos disponibles, lo que facilita que los profesionales de Data Science y Big Data identifiquen los patrones y tendencias ocultos dentro de los datos.
Gracias a la visualización de datos, los profesionales en los campos de ciencia de datos y big data no necesitan navegar extensamente a través de miles de filas y columnas en una hoja de cálculo: pueden consultar la visualización para comprender dónde se encuentra toda la información relevante dentro de un conjunto de datos.
Aunque tenemos numerosas herramientas independientes e ingeniosas de visualización de datos como Tableau, QlikView y d3.js, hoy vamos a hablar sobre la visualización de datos en el lenguaje de programación R. R es una excelente herramienta para la visualización de datos, ya que viene con muchas funciones y bibliotecas integradas que cubren casi todas las necesidades de visualización de datos.
En esta publicación, discutiremos las 8 herramientas de visualización de datos R utilizadas por los científicos y analistas de datos de todo el mundo.
Tabla de contenido
Las 8 mejores herramientas de visualización de datos
1. Gráfico de barras
Todo el mundo está familiarizado con los gráficos de barras que se enseñaban en las escuelas y universidades. En R Data Visualization con un gráfico de barras, el concepto y el objetivo siguen siendo los mismos: mostrar una comparación entre dos o más variables. Los gráficos de barras representan la comparación entre el total acumulado en varios grupos. La sintaxis estándar para crear un gráfico de barras en R es:
barplot(H,xlab,ylab,main, nombres.arg,col)
Hay muchos tipos diferentes de gráficos de barras que tienen propósitos únicos. Si bien los gráficos de barras horizontales y verticales son los formatos estándar, R puede crear barras horizontales y verticales en un gráfico. Además, R también ofrece un gráfico de barras apiladas que le permite introducir diferentes variables en cada categoría. En R, barplot() se usa para crear gráficos de barras.
2. Histograma
Los histogramas funcionan mejor con números precisos o en R. Esta representación divide los datos en contenedores (roturas) y muestra la distribución de frecuencia de estos contenedores. Puede modificar los contenedores y ver qué efecto tiene en el patrón de visualización. La sintaxis estándar para crear un histograma usando R es:
hist(v,principal,xlab,xlim,ylim,saltos,col,borde)
Los histogramas proporcionan una estimación de probabilidad de una variable, es decir, el período de tiempo antes de la finalización de un proyecto. Cada barra en un histograma representa la altura del número de valores presentes en ese rango. El lenguaje R usa la función hist() para crear histogramas.
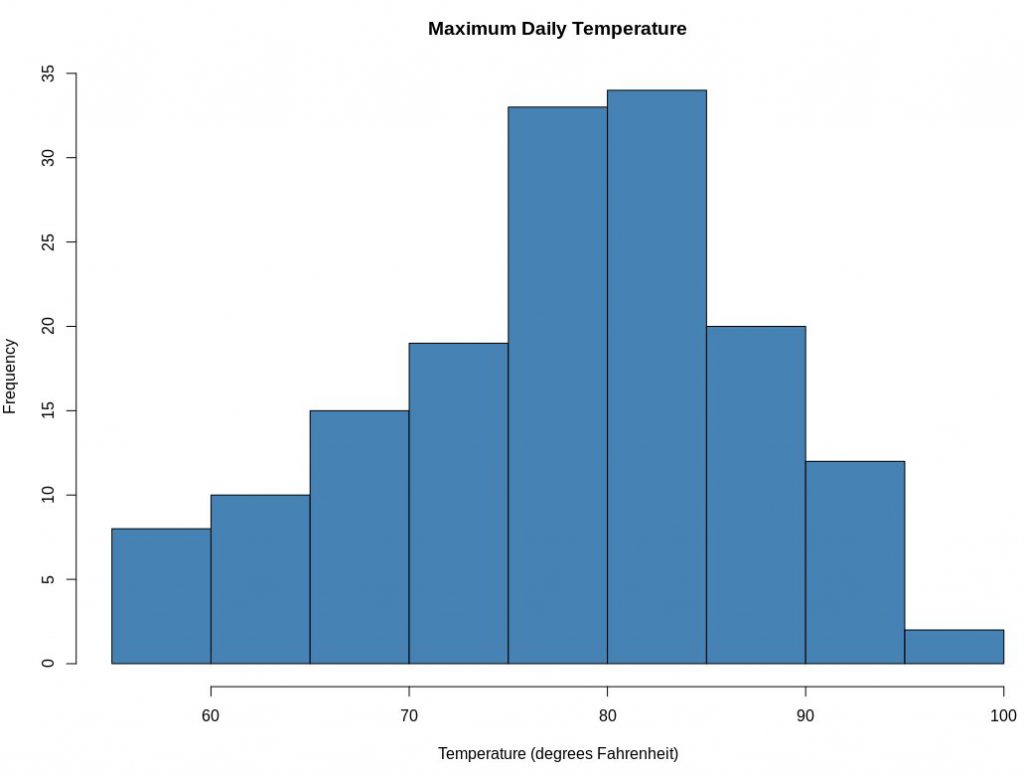
Fuente
3. Diagrama de caja
Un diagrama de caja representa cinco números estadísticamente significativos que incluyen el mínimo, el percentil 25, la mediana, el percentil 75 y el máximo. Aunque un diagrama de caja comparte muchas similitudes con un gráfico de barras, un diagrama de caja proporciona visualización para datos de variables continuas y categóricas, en lugar de centrarse solo en datos categóricos. La sintaxis estándar para crear un diagrama de caja en R es:
boxplot(x, datos, muesca, varwidth, nombres, principal)
R crea diagramas de caja utilizando la función boxplot(). Esta función puede tomar cualquier número de vectores numéricos y dibujar un diagrama de caja para cada vector. Los diagramas de caja son los más adecuados para visualizar la distribución de los datos y, en consecuencia, derivar inferencias basadas en ellos.
Aprenda cursos de ciencia de datos de las mejores universidades del mundo. Obtenga programas Executive PG, programas de certificados avanzados o programas de maestría para acelerar su carrera.
4. Diagrama de dispersión
Los diagramas de dispersión representan numerosos puntos en el plano cartesiano, donde cada punto representa los valores de dos variables. Puede elegir una variable en el eje horizontal y la segunda en el eje vertical. La función de un diagrama de dispersión es rastrear dos variables continuas a lo largo del tiempo. En R, la función plot() se usa para crear un diagrama de dispersión. La sintaxis estándar para crear diagramas de dispersión en R es:
trama (x, y, principal, xlab, ylab, xlim, ylim, ejes)
Los diagramas de dispersión son excelentes para los casos en los que desea evitar la información errónea en la visualización. Estos son los más adecuados para la inspección de datos simple.

5. Correlograma
Un correlograma, o matriz de correlación, analiza la relación entre cada par de variables numéricas en un conjunto de datos. Proporciona una descripción general rápida del conjunto de datos completo. Los correlogramas también pueden resaltar la cantidad de correlación entre conjuntos de datos en varios puntos en el tiempo.
En R, el paquete GGally es ideal para construir correlogramas. Para crear un correlograma clásico (con un gráfico de dispersión, un coeficiente de correlación y una distribución variable), puede usar la función ggpairs(). Otro gran paquete para crear correlogramas es el paquete corrgram. En este paquete, puede elegir qué mostrar (diagrama de dispersión, gráfico circular, texto, elipse, etc.) en la parte superior, inferior y diagonal de la representación. Para crear un correlograma usando el paquete corrgram así:
corrgram(x, order = , panel=, lower.panel=, upper.panel=, text.panel=, diag.panel=)
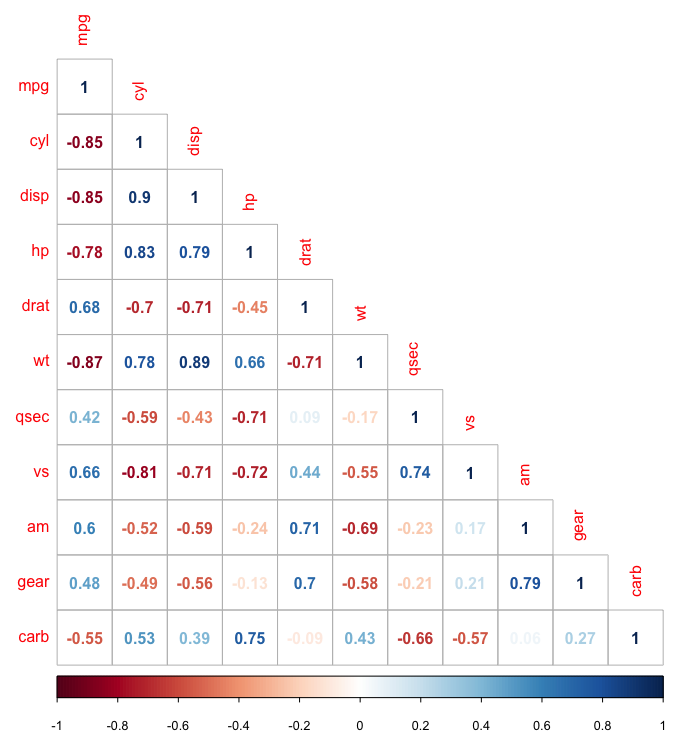
Fuente
6. Mapa de calor
Los mapas de calor son representaciones gráficas de datos en los que los valores individuales contenidos en una matriz se representan a través de diferentes colores. Los mapas de calor le permiten realizar análisis de datos exploratorios con dos dimensiones como eje, y la intensidad del color representa la tercera dimensión. En R, la función heatmap() se usa para crear mapas de calor. Antes de crear un mapa de calor, debe convertir el conjunto de datos a un formato de matriz utilizando el siguiente código:
> mapa de calor (as.matrix (mtcars))
Hay tres opciones para construir mapas de calor interactivos en R:
- plotly: con plotly, puede convertir cualquier mapa de calor creado con ggplot2 en un mapa de calor interactivo.
- d3heatmap: este paquete utiliza la misma sintaxis que la función base R heatmap() para crear mapas de calor interactivos.
- heatmaply: este es el paquete R más personalizable. Le permite optar por muchos tipos diferentes de opciones de personalización.
7. Clasificación hexagonal
El agrupamiento hexagonal es un tipo de histograma bivariado más adecuado para visualizar la estructura en conjuntos de datos con n grande. El concepto subyacente aquí es:
- Una cuadrícula regular de hexágonos puntea el plano XY sobre el conjunto [rango(x), rango(y)].
- El número de puntos que caen en cada hexágono se cuenta y almacena dentro de una estructura de datos.
- Los hexágonos que tienen un recuento > 0 se trazan utilizando una rampa de color o variando el radio del hexágono en proporción a los recuentos.
Leer: Diferentes tipos de científicos de datos
El algoritmo que funciona aquí es rápido y eficaz para mostrar la estructura de conjuntos de datos con n ≥ 106. En R, el paquete hexbin contiene una variedad de funciones para crear, manipular y trazar contenedores hexagonales. Este paquete integra el concepto básico de binning hexagonal con muchas otras funciones para ejecutar el suavizado bivariado, encontrar una mediana bivariada aproximada y estudiar la diferencia entre dos conjuntos de bins en la misma escala.
8. Parcela de mosaico
En la programación R, el gráfico de mosaico es útil al visualizar datos de la tabla de contingencia o la tabla de frecuencia de dos vías. Es una representación gráfica de una tabla de contingencia de doble entrada que representa la relación entre dos o más variables categóricas. El gráfico de mosaico R crea un rectángulo donde la altura representa el valor proporcional. La sintaxis estándar para crear un gráfico de mosaico en R es:
mosaicplot(x, color = NULL, principal = “Título”)
Esencialmente, un diagrama de mosaico es una extensión multidimensional de un diagrama de columna vertebral que resume las probabilidades condicionales de co-ocurrencia de los valores categóricos en una lista de registros que tienen la misma longitud. Ayuda a visualizar datos de dos o más variables cualitativas.
Leer: Salario de análisis y ciencia de datos
Terminando
A medida que todos los sectores de la industria continúan confiando en Big Data para promover negocios y marketing basados en datos, la importancia de la visualización de datos también se disparará simultáneamente. Dado que las técnicas de visualización como tablas y gráficos son herramientas mucho más eficientes para la visualización de datos que las hojas de cálculo tradicionales y los informes arcaicos, las herramientas de visualización de datos R están ganando popularidad en los círculos de ciencia de datos y big data.
Si tiene curiosidad por aprender sobre ciencia de datos, consulte nuestro Diploma PG en ciencia de datos, creado para profesionales que trabajan y ofrece más de 10 estudios de casos y proyectos, talleres prácticos, tutoría con expertos de la industria, 1 a 1 con mentores de la industria, más de 400 horas de aprendizaje y asistencia laboral con las mejores empresas.
¿Cuál debo aprender, R o Python?
Se considera que Python y R son bastante simples de aprender. Python fue creado con el desarrollo de software en mente. Si tiene experiencia previa con Java o C ++, Python puede ser más fácil para usted que R. R, por otro lado, puede ser un poco más fácil si tiene experiencia en estadísticas. La sintaxis fácil de entender de Python hace que sea más fácil de aprender. R tiene una curva de aprendizaje más alta al principio, pero se vuelve considerablemente más fácil a medida que lo sigues practicando.
¿Es Tableau la mejor herramienta para la visualización de datos?
Tableau es una de las herramientas de visualización de datos más populares del mercado por dos razones: es fácil de usar y bastante potente. El programa puede importar datos de cientos de fuentes y generar docenas de estilos de visualización, incluidos gráficos, mapas y mucho más.
¿Cuáles son las diferencias entre R y RStudio?
R es un lenguaje de programación para el cálculo estadístico y RStudio es un entorno de programación estadística que aprovecha R. Puede crear un programa en R y ejecutarlo sin usar ningún otro software. Sin embargo, para que RStudio funcione de manera efectiva, debe usarse junto con R.