
Jak zbudować program Pythona do analizy nastrojów na Twitterze? [Samouczek krok po kroku]
Opublikowany: 2020-08-07
Źródło
Ponieważ firmy w coraz większym stopniu opierają się na danych, technika uczenia maszynowego o nazwie „Analiza nastrojów” zyskuje z dnia na dzień ogromną popularność. Analizuje dane cyfrowe / tekst za pomocą przetwarzania języka naturalnego (NLP), aby znaleźć biegunowość (pozytywna, negatywna, neutralna), uczucia i emocje (złość, radość, smutek itp.) wyrażone w tekście.
Ponieważ Twitter jest jednym z najbardziej wszechstronnych źródeł rozmów publicznych na żywo na całym świecie, firmy biznesowe, grupy polityczne itp. są zainteresowane przeprowadzaniem „Analizy nastrojów” tweetów w celu zrozumienia emocji/opinii rynku docelowego lub badania rynku konkurencji . Chociaż są gotowi do użycia programów w tym celu, ale aby uzyskać prognozy o wysokim poziomie dokładności, specyficzne dla określonych kryteriów i domen, najlepszym sposobem jest utworzenie dostosowanego modelu lub programu Twitter Sentiment Analysis w Pythonie .
Spis treści
Samouczek krok po kroku: Tworzenie programu do analizy nastrojów na Twitterze za pomocą Pythona
Ten samouczek ma na celu stworzenie programu do analizy nastrojów na Twitterze przy użyciu Pythona. Powstały program powinien być w stanie przeanalizować tweety pobrane z Twittera i zrozumieć odczucia tekstu, takie jak jego polaryzacja i subiektywność.
Perkwizycje
1. Najważniejsza jest podstawowa wiedza na temat kodowania/programowania w Pythonie.
2. Narzędzia do zainstalowania na komputerze:

- Pyton
- Biblioteki: Tweepy, tekst blob, chmura słów, pandy, NumPy, matplotlib
(Tweepy to oficjalna biblioteka Pythona dla API Twittera, która umożliwia komunikację Pythona z platformą Twitter)
3. Konto na Twitterze
4. Aplikacja Twitter musi zostać utworzona i uwierzytelniona przez Twitter: Jest to konieczne, aby uzyskać „Klucz konsumenta i tokeny dostępu”, które będą potrzebne podczas programowania.
Jeśli nie masz jeszcze aplikacji Twitter stworzonej w tym celu, oto jak ją utworzyć.
Przeczytaj więcej: Samouczek Pythona NumPy: Naucz się Pythona Numpy z przykładami
Jak stworzyć aplikację na Twittera?
- Przejdź do witryny programistów Twittera: dev.twitter.com.
- Zaloguj się na swoje konto na Twitterze
- Przejdź do „Moich aplikacji”
- Kliknij „Utwórz nową aplikację”.
- Następnie musisz wypełnić formularz, jak pokazano poniżej.
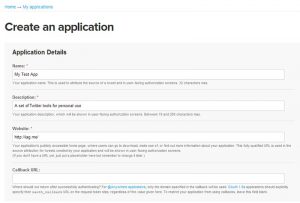
Źródło
- Następnie kliknij „Utwórz mój token dostępu”.
- Na następnej stronie wybierz opcję „Odczyt i zapis” w kolumnie „Typ aplikacji”.
Otrzymasz ustawienia OAuth aplikacji Twitter, które zawierają wszystkie niezbędne szczegóły związane z kluczem klienta, kluczem klienta, tokenem dostępu, kluczem dostępu itp. Musisz zanotować te szczegóły, ponieważ te dane logowania API umożliwią Ci pobieranie tweetów z Twittera. Lepiej zapisać go w pliku CSV na swoim komputerze, później możesz bezpośrednio przesłać plik CSV do swojego programu, aby odczytać dane uwierzytelniające API
Zacznij od tworzenia programu Python do analizy nastrojów na Twitterze
1. Zaimportuj biblioteki : Tweepy, tekst blob, chmura słów, pandy, NumPy, matplotlib
2. Uwierzytelnij aplikację Twitter: Następnie musisz uwierzytelnić swoją aplikację Twitter przy użyciu poświadczeń ustawień OAuth aplikacji Twitter, zwanych również poświadczeniami API Twitter. W tym celu musisz utworzyć obiekt uwierzytelniający, używając kodów, jak pokazano na poniższym obrazku.
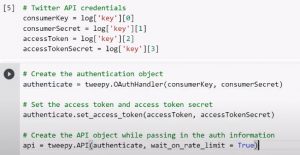
Źródło
Aby uzupełnić dane uwierzytelniające Twitter API, możesz przesłać plik CSV lub ręcznie skopiować i wkleić dane uwierzytelniające.
3. Pobierz tweety od użytkownika Twittera: Teraz, aby pobrać tweety, musisz najpierw wybrać użytkownika Twittera, którego tweety chcesz przeanalizować, aby zrozumieć wyrażone w nim nastroje. Powiedzmy; chcesz sprawdzić, czy tweety „UserXYZ” są pozytywne, negatywne czy neutralne, wykonując analizę sentymentu 100 tweetów użytkownika UserXYZ.
Kod do pobierania tweetów
posts = api.user_timeline(screen_name = ”UserXYZ”, count= 100, Lang ="en", tweet_mode="extended")
Uruchomienie powyższego polecenia spowoduje wyświetlenie tweetów.
4. Utwórz ramkę danych: Teraz musisz utworzyć ramkę danych dla pobranych tweetów. Załóżmy, że nazwałeś pierwszą kolumnę swojego pliku df jako „Tweety” i będzie ona zawierać wszystkie tweety rozmieszczone w 100 wierszach, ponieważ analizujesz 100 tweetów.
Df = pd.dataframe( [tweet.full_text for tweet w postach] , column=[ 'Tweet'])
5. Wyczyść tekst: Czyszczenie tekstu tweetów jest ważne dla sukcesu twojego programu Pythona do analizy nastrojów na Twitterze, ponieważ będzie wiele niechcianych symboli, takich jak @, #, ponowne tweety, hiperłącza w adresach URL itp. Biblioteka Pythona zostaje uruchomiona.
Uzyskaj subiektywność i polaryzację: Po wyczyszczeniu tekstu musisz utworzyć dwie funkcje za pomocą biblioteki Pythona TextBlob, aby uzyskać subiektywność i polaryzację tweetów. Subiektywność pokazuje, jak uparty jest tekst, a polaryzacja opisuje pozytywność lub negatywność tekstu. Najlepiej byłoby napisać skrypt Pythona, aby utworzyć dwie dodatkowe kolumny w ramce danych, aby hostować Subiektywność i Polarność. Więc teraz twoja ramka danych będzie miała trzy kolumny (pierwsza na tweety, druga na subiektywność, trzecia na polaryzację)

Kody do tworzenia funkcji Subiektywności i Biegunowości są następujące:
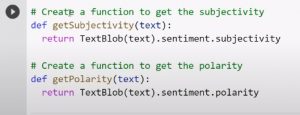
Źródło
Po uruchomieniu kodu zobaczysz wyniki subiektywności i polaryzacji każdego tweeta pokazanego w odpowiednich kolumnach. TextBlob opisuje polaryzację w skali od 1 do -1. Tak więc, jeśli tweet ma polaryzację -0,4 oznacza, że jest nieco ujemny, a jeśli ma subiektywność 0,6, to jest dość subiektywny.
6. Następnie możesz włączyć chmurę słów do swojego programu Python do analizy nastrojów na Twitterze , ponieważ chmury słów są również popularne jako technika wizualizacji danych używana do analizy nastrojów, w której rozmiar słów wskazuje na ich wagę.
Przykład WordCloud:

Źródło
Biblioteki matplotlib, Pandas i WordCloud zaczną działać, które już zaimportowałeś. Aby wykreślić słowo cloud-first, musisz utworzyć zmienną; nazwijmy go „allwords”, aby reprezentować wszystkie tweety w kolumnie „Tweety” ramki danych.
Kod do tworzenia WordCloud
allwords = ' '.join( [twts dla twts w df [ 'tweety' ]] )
WordCloud = WordCloud (szerokość =xxx, wysokość =xxx, stan_losowy =xxx, max_font_size =xxx. generuj (wszystkie słowa)
plt.imshow(wordcloud)
oś.pl(„wył”)
plt.pokaż()
7. Ponieważ masz wyniki polaryzacji dla każdego tweeta, możesz zacząć obliczać pozytywną, negatywną i neutralną analizę tweetów. W tym celu musisz utworzyć funkcję, nazwijmy ją „Analiza”, w której możesz przypisać wynik 0 do neutralnego, <0 do ujemnego i >0 do dodatniego.
Analiza definicji (wynik):
Jeśli wynik < 0
zwróć 'Negatywne'.
wynik elif == 0
powrót „neutralny”
w przeciwnym razie,
zwróć „pozytywny”.
Następnie, aby przechowywać wyniki analizy sentymentu tweetów, utwórz nową kolumnę w ramce danych, nazwijmy ją „TwtAnalysis”, a następnie napisz następujący kod:
df ['TwtAnalysis'] = df ['Polarność']. zastosuj (analiza)
8. Nowa ramka danych będzie miała dodaną kolumnę o nazwie „TwtAnalysis” i będzie odnosić się do każdego tweeta jako pozytywnego, negatywnego lub neutralnego w oparciu o wynik polaryzacji. Przykład pokazano poniżej na obrazku:

Źródło
9. Po sklasyfikowaniu tweetów jako pozytywnych, negatywnych i neutralnych możesz kontynuować tworzenie swojego programu do analizy nastrojów na Twitterze w Pythonie do reprezentowania danych w różnych formatach, takich jak:
- Uzyskaj procent pozytywnych, negatywnych lub neutralnych tweetów.
- Wydrukuj osobno wszystkie pozytywne komentarze lub negatywne lub neutralne tweety
- Utwórz wizualny wykres analizy nastrojów pozytywnych, negatywnych i neutralnych tweetów i wiele więcej.
Przeczytaj także: 9 najlepszych bibliotek Pythona do uczenia maszynowego
Wniosek
Program Twitter Sentiment Analysis Python , wyjaśniony w ten artykuł to tylko jeden sposób na stworzenie takiego programu. Deweloper może dostosować program na wiele sposobów, aby dostosować go do specyfikacji, aby uzyskać najwyższą dokładność odczytu danych, czyli piękno programowania za pomocą pythona, który jest świetnym językiem, wspieranym przez aktywną społeczność programistów i zbyt wiele bibliotek.
Python ma ogromny zakres w przestrzeni uczenia maszynowego i nauki o danych. Ci, którzy od jakiegoś czasu zajmują się programowaniem, dobrze wiedzą, że uczenie maszynowe nadal będzie jednym z przełomowych odkryć w przyszłości programowania.
Jeśli chcesz uzyskać wszechstronną i ustrukturyzowaną naukę, również jeśli chcesz dowiedzieć się więcej o uczeniu maszynowym, sprawdź dyplom PG IIIT-B i upGrad w uczeniu maszynowym i sztucznej inteligencji, który jest przeznaczony dla pracujących profesjonalistów i oferuje ponad 450 godzin rygorystycznych szkoleń, ponad 30 studiów przypadków i zadań, status absolwentów IIIT-B, ponad 5 praktycznych praktycznych projektów zwieńczenia i pomoc w pracy z najlepszymi firmami.
Jakie jest funkcjonalne znaczenie analizy sentymentu w mediach społecznościowych?
W dobie mediów społecznościowych opinie konsumentów mają nieskończoną moc tworzenia lub łamania marki. Analiza nastrojów to najlepszy sposób na dokładne zrozumienie czynników napędzających opinie i emocje konsumentów. Dzięki danym dostępnym z analizy nastrojów firmy mogą znaleźć swoich docelowych odbiorców, zidentyfikować osoby mające wpływ w mediach społecznościowych na ich markę i dostrzec pojawiające się trendy rynkowe. Co więcej, analiza sentymentu na platformach społecznościowych oferuje również kompleksowe wyobrażenie o zdrowiu ich marki; firmy mogą otrzymywać uczciwe opinie konsumentów na temat ich nowo wprowadzonych produktów i usług, aby je ulepszać. Skutecznie radzi sobie również z reputacją online, lepiej identyfikując zakresy usprawnień i rozwiązywania problemów.
Czy możesz samodzielnie nauczyć się Pythona?
Jeśli masz jakieś doświadczenie w programowaniu, z pewnością możesz samodzielnie rozpocząć naukę Pythona. Python ma stosunkowo prostą strukturę składniową, a także jest intuicyjny, dzięki czemu jest łatwy do zrozumienia nawet dla początkujących. Poza tym łatwo jest zainstalować pakiet i uruchomić go na swoim komputerze z dowolnego miejsca. Możesz przyspieszyć naukę, zapisując się na kursy Pythona, uczestnicząc w kursach kodowania. Dzięki aktywnej społeczności programistów, która zawsze jest chętna do rozszerzenia wsparcia, obfitości zasobów edukacyjnych i dokumentacji, początkujący mogą nauczyć się podstaw Pythona w około 7-8 tygodni.
Co jest trudniejsze do nauczenia między Pythonem a C++?
Python i C++ to zupełnie różne języki programowania o zupełnie innym zachowaniu i funkcjach. Jednak oba silnie wspierają programowanie obiektowe. Ale biorąc pod uwagę ogólny framework Pythona, jest on prosty, znacznie łatwiejszy i szybszy do nauczenia niż C++. W rzeczywistości wiele osób uczy się Pythona, aby doświadczyć, jak wygląda proste kodowanie. Python jest oprogramowaniem typu open source, bezpłatnym i oferuje ogromną niezawodność i łatwość tworzenia złożonych aplikacji do uczenia maszynowego. Chociaż C++ jest bardziej wydajny pod względem wydajności, nie jest uważany za odpowiedni dla Pythona w projektach uczenia maszynowego.