
Wie erstellt man ein Python-Programm zur Sentiment-Analyse auf Twitter? [Schritt-für-Schritt-Tutorial]
Veröffentlicht: 2020-08-07
Quelle
Da Unternehmen zunehmend datengesteuert werden, gewinnt eine Technik des maschinellen Lernens namens „Stimmungsanalyse“ von Tag zu Tag immens an Popularität. Es analysiert die digitalen Daten/Texte durch Natural Language Processing (NLP), um die Polarität (positiv, negativ, neutral), Gefühle und Emotionen (wütend, glücklich, traurig usw.) zu finden, die im Text zum Ausdruck kommen.
Da Twitter eine der umfassendsten Quellen für öffentliche Live-Gespräche weltweit ist, sind Wirtschaftsunternehmen, politische Gruppen usw. daran interessiert, eine „Stimmungsanalyse“ von Tweets durchzuführen, um die Emotionen/Meinungen des Zielmarktes zu verstehen oder den Markt der Wettbewerber zu untersuchen . Obwohl sie bereit sind, Programme für diesen Zweck zu verwenden, aber um Vorhersagen mit einem hohen Maß an Genauigkeit zu erzielen, die für bestimmte Kriterien und Domänen spezifisch sind, ist der beste Weg, ein angepasstes Twitter-Stimmungsanalyse-Python -Modell oder -Programm zu erstellen.
Inhaltsverzeichnis
Schritt-für-Schritt-Tutorial: Erstellen Sie ein Twitter-Stimmungsanalyseprogramm mit Python
Dieses Tutorial zielt darauf ab, ein Twitter-Stimmungsanalyseprogramm mit Python zu erstellen. Das resultierende Programm sollte in der Lage sein, die von Twitter abgerufenen Tweets zu analysieren und die Stimmungen des Textes, wie seine Polarität und Subjektivität, zu verstehen.
Die Vorzüge
1. An erster Stelle stehen die grundlegenden Codierungs-/Programmierkenntnisse von Python.
2. Auf Ihrem Computer zu installierende Tools:

- Python
- Bibliotheken: Tweepy, Text-Blob, Wortwolke, Pandas, NumPy, Matplotlib
(Tweepy ist die offizielle Python-Bibliothek für die Twitter-API, die es Python ermöglicht, mit der Twitter-Plattform zu kommunizieren)
3. Ein Twitter-Konto
4. Eine Twitter-App muss von Twitter erstellt und authentifiziert werden: Dies ist erforderlich, um den „Verbraucherschlüssel und die Zugriffstoken“ zu erhalten, die Sie für Ihre Programmierung benötigen.
Wenn Sie noch keine Twitter-App für diesen Zweck erstellt haben, können Sie sie wie folgt erstellen.
Weiterlesen : Python NumPy Tutorial: Lernen Sie Python Numpy mit Beispielen
Wie erstelle ich eine Twitter-App?
- Rufen Sie die Twitter-Entwicklerseite auf: dev.twitter.com.
- Melden Sie sich mit Ihrem Twitter-Konto an
- Gehen Sie zu 'Meine Bewerbungen'
- Klicken Sie auf „Neue Anwendung erstellen“.
- Als nächstes müssen Sie ein Formular ausfüllen, wie unten gezeigt.
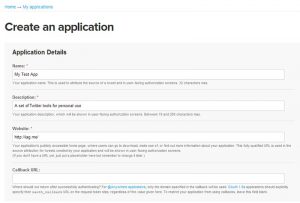
Quelle
- Klicken Sie anschließend auf „Create my Access Token“.
- Wählen Sie auf der nächsten Seite in der Spalte „Anwendungstyp“ die Option „Lesen und Schreiben“.
Sie erhalten Ihre OAuth-Einstellungen für die Twitter-App, die alle erforderlichen Details zu Ihrem Verbraucherschlüssel, Verbrauchergeheimnis, Zugriffstoken, Zugriffstokengeheimnis usw. enthalten. Sie müssen diese Details notieren, da diese API-Anmeldeinformationen es Ihnen ermöglichen, Tweets abzurufen von Twitter. Speichern Sie es besser in einer CSV-Datei auf Ihrem Computer, letzteres können Sie die CSV-Datei direkt in Ihr Programm hochladen, um API-Anmeldeinformationen zu lesen
Beginnen Sie mit der Erstellung eines Python-Programms zur Analyse der Twitter-Stimmung
1. Importieren Sie die Bibliotheken : Tweepy, Text Blob, Word Cloud, Pandas, NumPy, Matplotlib
2. Authentifizieren Sie die Twitter-App: Als Nächstes müssen Sie Ihre Twitter-App mit den Anmeldeinformationen für die OAuth-Einstellungen der Twitter-App authentifizieren, die auch als Twitter-API-Anmeldeinformationen bezeichnet werden. Dazu müssen Sie ein Authentifizierungsobjekt erstellen, indem Sie die Codes verwenden, wie in der Abbildung unten gezeigt.
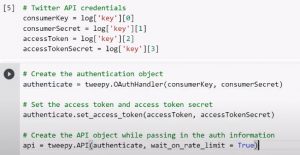
Quelle
Um die Anmeldeinformationen für die Twitter-API auszufüllen, können Sie entweder die CSV-Datei hochladen oder die Anmeldeinformationen manuell kopieren und einfügen.
3. Rufen Sie die Tweets vom Twitter-Benutzer ab: Um die Tweets abzurufen, müssen Sie zunächst einen Twitter-Benutzer auswählen, dessen Tweets Sie analysieren möchten, um die darin ausgedrückte Stimmung zu verstehen. Sagen wir; Sie möchten sehen, ob die Tweets von „UserXYZ“ positiv oder negativ oder neutral sind, indem Sie eine Stimmungsanalyse der 100 Tweets von UserXYZ durchführen.
Code zum Abrufen der Tweets
posts = api.user_timeline(screen_name = „UserXYZ“, count= 100, Lang =“en“, tweet_mode=“extended“)
Wenn Sie den obigen Befehl ausführen, werden die Tweets angezeigt.
4. Datenrahmen erstellen: Jetzt müssen Sie einen Datenrahmen für die abgerufenen Tweets erstellen. Nehmen wir an, Sie nennen die erste Spalte Ihrer DF „Tweets“, und sie enthält alle Tweets, die über 100 Zeilen verteilt sind, da Sie 100 Tweets analysieren.
Df = pd.dataframe( [tweet.full_text für Tweets in Beiträgen] , Spalten=[ 'Tweet'])
5. Bereinigen Sie den Text: Das Bereinigen des Textes der Tweets ist wichtig für den Erfolg Ihres Python-Programms zur Analyse der Twitter-Stimmung, da es viele unerwünschte Symbole wie @, #, Retweets, Hyperlinks in den URLs usw. geben wird python''-Bibliothek wird verwendet.
Holen Sie sich die Subjektivität und Polarität: Nachdem Sie den Text bereinigt haben, müssen Sie zwei Funktionen mit der TextBlob-Python-Bibliothek erstellen, um die Subjektivität und Polarität der Tweets zu erhalten. Die Subjektivität zeigt, wie eigensinnig der Text ist, und die Polarität beschreibt die Positivität oder Negativität des Textes. Es wäre am besten, das Python-Skript zu schreiben, um zwei weitere Spalten in Ihrem Datenrahmen zu erstellen, um Subjektivität und Polarität zu hosten. Jetzt hat Ihr Datenrahmen also drei Spalten (erste für die Tweets, zweite für die Subjektivität, dritte für die Polarität).

Die Codes zum Erstellen von Subjektivitäts- und Polaritätsfunktionen lauten wie folgt:
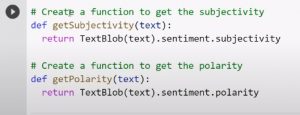
Quelle
Nachdem Sie den Code ausgeführt haben, sehen Sie die Bewertungen der Subjektivität und Polarität jedes Tweets in den entsprechenden Spalten. TextBlob beschreibt die Polarität innerhalb einer Skala von 1 bis -1. Wenn also ein Tweet eine Polarität von -0,4 hat, bedeutet das, dass er leicht negativ ist, und wenn er eine Subjektivität von 0,6 hat, dann ist er ziemlich subjektiv.
6. Als Nächstes können Sie eine Wortwolke in Ihr Python- Programm für die Twitter-Stimmungsanalyse aufnehmen, da Wortwolken auch als Datenvisualisierungstechnik für die Stimmungsanalyse beliebt sind, wobei die Größe der Wörter ihre Bedeutung angibt.
Beispiel einer WordCloud:

Quelle
Die Matplotlib-, Pandas- und WordCloud-Bibliotheken werden aktiviert, die Sie bereits importiert haben. Um eine Wortwolke zuerst zu zeichnen, müssen Sie eine Variable erstellen; Nennen wir es „allwords“, um alle Tweets in der Spalte „Tweets“ des Datenrahmens darzustellen.
Code zum Erstellen von WordCloud
allwords = ' '.join( [twts für twts in df [ 'Tweets' ]] )
WordCloud = WordCloud (Breite =xxx, Höhe =xxx, randon_state =xxx, max_font_size =xxx. generieren (alleWörter)
plt.imshow(wordcloud)
plt.axis(“off”)
plt.show()
7. Da Sie die Polaritätsbewertungen für jeden Tweet haben, können Sie damit beginnen, positive, negative und neutrale Analysen der Tweets zu berechnen. Dazu müssen Sie eine Funktion erstellen, nennen wir sie "Analyse", in der Sie die Bewertung 0 für neutral, <0 für negativ und >0 für positiv zuweisen können.
Def-Analyse (Punktzahl):
Wenn Punktzahl < 0
geben Sie 'Negativ' zurück.
Elif-Score == 0
return 'neutral
anders,
gib 'positiv' zurück.
Um die Ergebnisse der Stimmungsanalyse der Tweets zu hosten, erstellen Sie als Nächstes eine neue Spalte in Ihrem Datenrahmen, nennen wir sie „TwtAnalysis“ und schreiben Sie dann den folgenden Code:
df [ 'TwtAnalysis' ] = df [ 'Polarität' ]. anwenden (Analyse)
8. Der neue Datenrahmen hat die hinzugefügte Spalte mit dem Namen „TwtAnalysis“ und bezieht sich auf jeden Tweet basierend auf seiner Polaritätsbewertung entweder als positiv, negativ oder neutral. Ein Beispiel ist unten im Bild dargestellt:

Quelle
9. Sobald Sie die Tweets als positiv, negativ und neutral klassifiziert haben, können Sie mit dem Aufbau Ihres Twitter-Stimmungsanalyse-Python- Programms fortfahren um die Daten in verschiedenen Formaten darzustellen, wie zum Beispiel:
- Rufen Sie den Prozentsatz positiver, negativer oder neutraler Tweets ab.
- Drucken Sie alle positiven Kommentare oder negativen oder neutralen Tweets separat aus
- Erstellen Sie ein Diagramm zur visuellen Stimmungsanalyse der positiven, negativen und neutralen Tweets und vieles mehr.
Lesen Sie auch: Top 9 Python-Bibliotheken für maschinelles Lernen
Fazit
Das Twitter Sentiment Analysis Python- Programm , erklärt in Dieser Artikel ist nur einer Weg, ein solches Programm zu erstellen. Der Entwickler kann das Programm auf vielfältige Weise an die Spezifikationen anpassen, um höchste Genauigkeit beim Lesen der Daten zu erreichen. Das ist das Schöne daran, es mit Python zu programmieren, einer großartigen Sprache, die von einer aktiven Entwicklergemeinschaft und zu vielen Bibliotheken unterstützt wird.
Python hat einen immensen Umfang im Bereich des maschinellen Lernens und der Datenwissenschaft. Diejenigen, die sich schon eine Weile mit dem Programmieren beschäftigen, wissen genau, dass Machine Learning auch in Zukunft einer der Durchbrüche in der Programmierung sein wird.
Wenn Sie eine umfassende und strukturierte Lernerfahrung wünschen und mehr über maschinelles Lernen erfahren möchten, sehen Sie sich das PG-Diplom in maschinellem Lernen und KI von IIIT-B & upGrad an, das für Berufstätige konzipiert ist und mehr als 450 Stunden bietet von rigoroser Ausbildung, mehr als 30 Fallstudien und Aufgaben, IIIT-B-Alumni-Status, mehr als 5 praktischen, praktischen Schlusssteinprojekten und Arbeitsunterstützung bei Top-Unternehmen.
Welche funktionale Bedeutung hat die Stimmungsanalyse in den sozialen Medien?
Im Zeitalter der sozialen Medien haben Verbrauchermeinungen eine unendliche Macht, eine Marke zu machen oder zu brechen. Die Stimmungsanalyse ist der beste Weg, um die treibenden Faktoren hinter den Meinungen und Emotionen der Verbraucher genau zu verstehen. Mit den aus der Stimmungsanalyse verfügbaren Daten können Unternehmen ihre Zielgruppe finden, Social-Media-Influencer für ihre Marke identifizieren und neue Markttrends erkennen. Darüber hinaus bietet die Stimmungsanalyse auf Social-Media-Plattformen auch einen umfassenden Überblick über die Gesundheit ihrer Marke; Unternehmen können ehrliches Verbraucherfeedback zu ihren neu eingeführten Produkten und Dienstleistungen erhalten, um diese zu verbessern. Es ist auch effektiv im Umgang mit der Online-Reputation, indem Verbesserungsbereiche und Problemlösungen besser identifiziert werden.
Kann man Python alleine lernen?
Wenn Sie ein gewisses Maß an Erfahrung mit der Programmierung haben, können Sie sicherlich selbst anfangen, Python zu lernen. Python hat einen vergleichsweise einfachen syntaktischen Aufbau und ist zudem intuitiv, sodass es auch für Anfänger leicht verständlich ist. Außerdem ist es einfach, das Paket zu installieren und von überall auf Ihrem Computer auszuführen. Sie können Ihr Lernen beschleunigen, indem Sie sich für Python-Kurse anmelden und an Programmier-Bootcamps teilnehmen. Mit einer aktiven Entwickler-Community, die immer bereit ist, den Support zu erweitern, einer Fülle von Lernressourcen und Dokumentationen können Anfänger die Grundlagen von Python in etwa 7-8 Wochen erlernen.
Was zwischen Python und C++ ist schwieriger zu lernen?
Python und C++ sind völlig unterschiedliche Programmiersprachen mit völlig unterschiedlichem Verhalten und unterschiedlichen Funktionen. Beide unterstützen jedoch stark die objektorientierte Programmierung. Aber in Anbetracht des gesamten Python-Frameworks ist es unkompliziert, viel einfacher und schneller zu erlernen als C++. Tatsächlich lernen viele Leute Python, um zu erfahren, wie sich einfaches Programmieren anfühlt. Python ist Open Source, kostenlos und bietet eine enorme Zuverlässigkeit und Benutzerfreundlichkeit bei der Entwicklung komplexer Anwendungen für maschinelles Lernen. Obwohl C++ in Bezug auf die Leistung effizienter ist, wird es gegenüber Python als nicht geeignet für Machine-Learning-Projekte angesehen.