
Twitterの感情分析Pythonプログラムを構築する方法は? [ステップバイステップのチュートリアル]
公開: 2020-08-07
ソース
企業がますますデータ主導型になるにつれて、「感情分析」と呼ばれる機械学習技術が日々絶大な人気を博しています。 自然言語処理(NLP)を介してデジタルデータ/テキストを分析し、テキストに表現されている極性(ポジティブ、ネガティブ、ニュートラル)、感情、感情(怒り、幸せ、悲しいなど)を見つけます。
Twitterは、世界中で最も包括的なライブの公開会話のソースの1つであるため、企業や政治団体などは、ツイートの「感情分析」を実行して、ターゲット市場の感情や意見を理解したり、競合他社の市場を調査したりすることに関心を持っています。 。 彼らは目的のためにプログラムを使用する準備ができていますが、特定の基準とドメインに固有の高レベルの精度で予測を達成するために、カスタマイズされたTwitter感情分析Pythonモデルまたはプログラムを作成するのが最善の方法です。
目次
ステップバイステップのチュートリアル:Pythonを使用してTwitterの感情分析プログラムを作成する
このチュートリアルは、Pythonを使用してTwitterの感情分析プログラムを作成することを目的としています。 結果として得られるプログラムは、Twitterから取得したツイートを解析し、極性や主観性などのテキストの感情を理解できる必要があります。
必要条件
1.何よりも、Pythonの基本的なコーディング/プログラミングの知識です。
2.コンピューターにインストールするツール:

- Python
- ライブラリ:Tweepy、テキストブロブ、ワードクラウド、パンダ、NumPy、matplotlib
(Tweepyは、PythonがTwitterプラットフォームと通信できるようにするTwitter APIの公式Pythonライブラリです)
3.Twitterアカウント
4. Twitterアプリは、Twitterによって作成および認証される必要があります。これは、プログラミングで必要となる「コンシューマーキーとアクセストークン」を取得するために必要です。
その目的のためにTwitterアプリをまだ作成していない場合は、次の方法で作成できます。
続きを読む: Python NumPyチュートリアル:例を使用してPythonNumpyを学ぶ
Twitterアプリを作成する方法は?
- Twitter開発者サイトdev.twitter.comにアクセスします。
- Twitterアカウントでサインインします
- 「マイアプリケーション」に移動します
- [新しいアプリケーションの作成]をクリックします。
- 次に、以下に示すように、フォームに入力する必要があります。
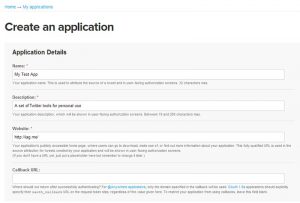
ソース
- 次に、[アクセストークンの作成]をクリックします。
- 次のページで、[アプリケーションの種類]列の下にある[読み取りと書き込み]オプションを選択します。
TwitterアプリのOAuth設定が提供されます。これには、コンシューマーキー、コンシューマーシークレット、アクセストークン、アクセストークンシークレットなどに関連するすべての必要な詳細が含まれます。これらのAPIクレデンシャルによりツイートを取得できるため、これらの詳細に注意する必要があります。ツイッターから。 コンピューターのCSVファイルに保存することをお勧めします。後者の場合、CSVファイルをプログラムに直接アップロードしてAPIクレデンシャルを読み取ることができます。
Twitter感情分析Pythonプログラムの作成を開始する
1.ライブラリをインポートします:Tweepy、text blob、word cloud、pandas、NumPy、matplotlib
2. Twitterアプリを認証する:次に、TwitterアプリのOAuth設定クレデンシャル(Twitter APIクレデンシャルとも呼ばれる)を使用してTwitterアプリを認証する必要があります。 このためには、次の画像に示すコードを使用して、認証オブジェクトを作成する必要があります。
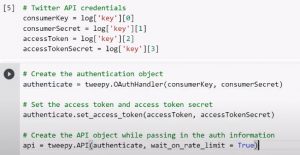
ソース
Twitter APIのクレデンシャルを入力するには、CSVファイルをアップロードするか、クレデンシャルの詳細を手動でコピーして貼り付けます。
3. Twitterユーザーからツイートを取得する:ここで、ツイートを取得するには、まず、ツイートを解析するTwitterユーザーを選択して、そこに表現されている感情を理解する必要があります。 まあ言ってみれば; UserXYZによる100のツイートの感情分析を実行して、「UserXYZ」のツイートがポジティブかネガティブかニュートラルかを確認します。
ツイートを取得するためのコード
投稿=api.user_timeline(screen_name =” UserXYZ”、count = 100、Lang =” en”、tweet_mode =“ extended”)
上記のコマンドを実行すると、ツイートが表示されます。
4.データフレームの作成:次に、フェッチしたツイートのデータフレームを作成する必要があります。 dfの最初の列に「Tweets」という名前を付けたとします。100個のツイートを分析しているため、100行にまたがるすべてのツイートが含まれます。
Df = pd.dataframe([投稿のツイートのtweet.full_text]、columns = ['Tweet'])
5.テキストのクリーンアップ:ツイートのテキストのクリーンアップは、Twitter感情分析Pythonプログラムを成功させるために重要です。これは、@、#、リツイート、URL内のハイパーリンクなどの不要な記号が多数存在するためです。 python''ライブラリが使用されます。
主観性と極性を取得する:テキストをクリーンアップしたら、TextBlob pythonライブラリを使用して2つの関数を作成し、ツイートの主観性と極性を取得する必要があります。 主観性はテキストがどれほど意見が分かれているかを示し、極性はテキストの肯定性または否定性を表します。 主観性と極性をホストするために、データフレームにさらに2つの列を作成するPythonスクリプトを作成するのが最善です。 したがって、データフレームには3つの列があります(最初はツイート用、2番目は主観用、3番目は極性用)

主観性と極性関数を作成するためのコードは次のとおりです。
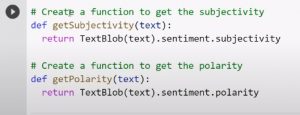
ソース
コードを実行すると、それぞれの列に表示される各ツイートの主観性と極性のスコアが表示されます。 TextBlobは、極性を1から-1のスケールで記述します。 したがって、ツイートの極性が-0.4の場合、それはわずかにネガティブであることを意味し、0.6の主観性がある場合、それはかなり主観的です。
6.次に、感情分析に使用されるデータ視覚化手法として単語クラウドも人気があり、単語のサイズがその重要性を示しているため、 Twitter感情分析Pythonプログラムに単語クラウドを含めることを選択できます。
WordCloudの例:

ソース
matplotlib、Pandas、およびWordCloudライブラリは、すでにインポートしたアクションで動作します。 単語をクラウドファーストでプロットするには、変数を作成する必要があります。 データフレームの「Tweets」列のすべてのツイートを表すために、「allwords」という名前を付けましょう。
WordCloudを作成するためのコード
allwords ='' .join([dfのtwtsのtwts ['Tweets']])
WordCloud = WordCloud(width = xxx、height = xxx、randon_state = xxx、max_font_size =xxx。generate(allwords)
plt.imshow(wordcloud)
plt.axis( "off")
plt.show()
7.各ツイートの極性スコアがあるので、ツイートのポジティブ、ネガティブ、ニュートラル分析の計算を開始できます。 このためには、関数を作成する必要があります。これを「分析」と呼びます。この関数では、スコア0をニュートラルに、<0を負に、>0を正に割り当てることができます。
Def Analysis(スコア):
スコア<0の場合
「ネガティブ」を返します。
elifスコア==0
'ニュートラルを返す
そうしないと、
「ポジティブ」を返します。
次に、ツイートの感情分析の結果をホストするために、データフレームに新しい列を作成し、「TwtAnalysis」という名前を付けてから、次のコードを記述します。
df ['TwtAnalysis'] =df['極性']。 適用(分析)
8.新しいデータフレームには「TwtAnalysis」という名前の列が追加され、極性スコアに基づいて各ツイートがポジティブ、ネガティブ、またはニュートラルとして参照されます。 以下の画像に例を示します。

ソース
9.ツイートをポジティブ、ネガティブ、ニュートラルに分類したら、 Twitter感情分析Pythonプログラムの構築を続けることができます。 次のようなさまざまな形式でデータを表すため。
- ポジティブ、ネガティブ、またはニュートラルなツイートの割合を取得します。
- すべての肯定的なコメントまたは否定的または中立的なツイートを個別に印刷する
- ポジティブ、ネガティブ、ニュートラルなツイートなどの視覚的な感情分析チャートを作成します。
また読む:機械学習のためのトップ9のPythonライブラリ
結論
Twitter感情分析Pythonプログラム、で説明されています この記事は1つだけです そのようなプログラムを作成する方法。 開発者は、データ読み取りで最高の精度を達成するための仕様に一致するようにプログラムをさまざまな方法でカスタマイズできます。つまり、開発者の活発なコミュニティと非常に多くのライブラリによってサポートされている優れた言語であるpythonを介してプログラムをプログラミングすることの美しさです。
Pythonは、機械学習とデータサイエンスの分野で非常に広い範囲を占めています。 しばらくプログラミングに興味がある人は、機械学習がプログラミングの将来のブレークスルーの1つであり続けることをよく知っています。
包括的で構造化された学習体験を取得したい場合、また機械学習について詳しく知りたい場合は、機械学習とAIのIIIT-BとupGradのPGディプロマをチェックしてください。これは、働く専門家向けに設計されており、450時間以上を提供します。厳格なトレーニング、30以上のケーススタディと課題、IIIT-B卒業生のステータス、5つ以上の実践的なキャップストーンプロジェクト、トップ企業との仕事の支援。
ソーシャルメディアでの感情分析の機能的重要性は何ですか?
ソーシャルメディアのこの時代では、消費者の意見はブランドを作り上げたり壊したりする無限の力を持っています。 感情分析は、消費者の意見や感情の背後にある推進要因を正確に理解するための最良の方法です。 感情分析から入手できるデータを使用して、企業はターゲットオーディエンスを見つけ、ブランドのソーシャルメディアインフルエンサーを特定し、新興市場のトレンドを見つけることができます。 さらに、ソーシャルメディアプラットフォームでの感情分析は、ブランドの健全性に関する包括的なアイデアも提供します。 企業は、新しく発売された製品やサービスについての正直な消費者フィードバックを受け取り、それを改善することができます。 また、改善の範囲と問題解決をより適切に特定することにより、オンラインレピュテーションの処理にも効果的です。
自分でPythonを学ぶことはできますか?
プログラミングの経験がある程度あれば、Pythonを自分で学び始めることができます。 Pythonは比較的単純な構文構造を備えており、直感的であるため、初心者でも簡単に理解できます。 さらに、パッケージをインストールして、どこからでもマシン上で実行するのは簡単です。 Pythonコースに登録し、コーディングブートキャンプに参加することで、学習を促進できます。 常にサポート、豊富な学習リソース、およびドキュメントを拡張することをいとわないアクティブな開発者コミュニティにより、初心者は約7〜8週間でPythonの基礎を学ぶことができます。
PythonとC++の間で学ぶのが難しいのはどちらですか?
PythonとC++はまったく異なるプログラミング言語であり、動作と機能がまったく異なります。 ただし、どちらもオブジェクト指向プログラミングを強力にサポートしています。 しかし、Pythonフレームワーク全体を考慮すると、C ++よりも簡単で、はるかに簡単で、すばやく習得できます。 実際、多くの人がPythonを学び、単純なコーディングがどのように感じられるかを体験しています。 Pythonはオープンソースで無料であり、複雑な機械学習アプリケーションの開発に関して、非常に高い信頼性と使いやすさを提供します。 C ++はパフォーマンスの点でより効率的ですが、機械学習プロジェクトにはPythonよりも適しているとは見なされていません。