
Jak zostać inżynierem uczenia maszynowego – 7 kroków [ze zdjęciami]
Opublikowany: 2019-06-12Świat techniki płonie możliwościami, jakie daje sztuczna inteligencja. Obietnica zautomatyzowania każdej przyziemnej części naszego życia (w tym prowadzenia samochodu) jest zbyt kusząca, aby naukowcy, wizjonerzy i futuryści mogli się oprzeć. W dzisiejszych czasach dziedzina uczenia maszynowego związana ze sztuczną inteligencją zyskuje na popularności.
International Data Corporation (IDC) przewiduje, że wydatki na sztuczną inteligencję i ML wzrosną pięciokrotnie, z 12 miliardów dolarów w 2017 r. do 57,6 miliardów dolarów do 2021 r. Największy kawałek tortu wezmą branża technologiczna i finansowa. 64% i 52% firm należących odpowiednio do tych branż przyjmie w przyszłości procesy uczenia maszynowego.
Obecnie zapotrzebowanie na ekspertów od uczenia maszynowego stale rośnie, co wyraźnie ilustruje ten wykres:
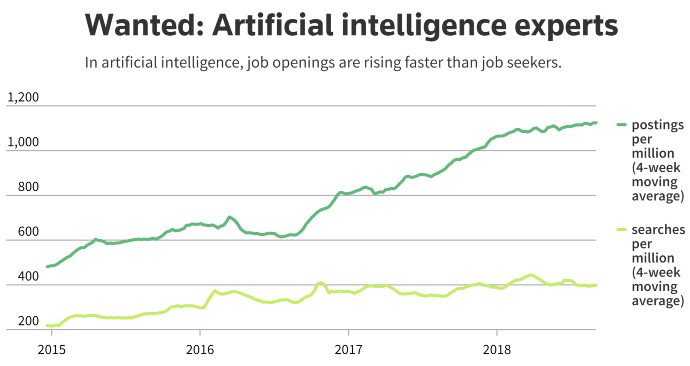
Źródło: Indeed.com | Kredyty: Ann Saphir, inżynier ds. wizualizacji danych, Reuters
W samym sercu maszyny leży jedno pytanie: jak możemy zaprogramować ten system, aby automatycznie ulepszał się i uczył z doświadczeniem? Learn here odnosi się do aktu wyciągania wniosków z danych i podejmowania inteligentnych decyzji. Uczenie maszynowe opracowuje algorytmy do tego, które czerpią wiedzę z konkretnych danych i doświadczenia, w oparciu o zasady statystyczne i obliczeniowe.
Powyższy akapit wskazywałby, jak trudne byłoby uczenie maszynowe. Jest, ale można się tego również nauczyć. Jeśli jesteś gotowy, aby zostać inżynierem uczenia maszynowego bez czekania, aż tradycyjna uczelnia zweryfikuje Twoją wiedzę, wykonaj i powtórz 7 kroków podanych poniżej, przeczytaj wymagania wymienione poniżej –

Krok 1: Podnieś swoje umiejętności w zakresie Pythona i oprogramowania
Łatwy w użyciu język wysokiego poziomu, Python jest językiem wybieranym przez specjalistów AI, naukowców zajmujących się danymi i inżynierów uczenia maszynowego.
Składnia Pythona jest łatwa do nauczenia i zawiera mnóstwo wbudowanych bibliotek. Musisz jednak uważać na spacje, ponieważ mogą one zepsuć wykonanie kodu. Obejmuje również obsługę wszystkich typów paradygmatów programowania, takich jak programowanie funkcjonalne i programowanie obiektowe.
Kolejną ważną rzeczą, z którą warto się zapoznać, jest Github. Będziesz pracować w zespole nad tworzeniem kodu dla aplikacji, w których liczy się czas. Nabierz nawyku pisania dokładnych testów jednostkowych dla swojego kodu przy użyciu frameworków, takich jak nose. Przetestuj swoje interfejsy API za pomocą narzędzi takich jak Postman.
Przeczytaj kilka książek lub artykułów, aby dowiedzieć się, jakich narzędzi będziesz potrzebować, aby uruchomić Pythona na zbiorach danych.
Krok 2: Przyjrzyj się algorytmom uczenia maszynowego
Po zapoznaniu się z językiem Python i zapoznaniu się z nim możesz zacząć przyglądać się algorytmom uczenia maszynowego. Koniecznie zapoznaj się z teorią związaną z każdym algorytmem, aby z łatwością zaimplementować modele.
Przewodnik po dziesięciu najlepszych algorytmach dla początkujących w dziedzinie uczenia maszynowego pomoże Ci być na bieżąco. Pamiętaj, że algorytm nr 1 będzie idealnym rozwiązaniem. Będziesz musiał zaimplementować wiele z nich. Dlatego dokładnie przestudiuj każdy z nich.
Kurs upGrad „ Masters in Data Science ” pomoże Ci uzyskać przewagę nad połączeniem Pythona z Data Science za pomocą narzędzi takich jak Panda, NumPy itp.
Krok 3: Praca nad mini projektami
Teraz, gdy Twoje wprowadzenie w sferę Pythona i uczenia maszynowego zostało zakończone (zarówno indywidualnie, jak i łącznie), nadszedł czas, aby zebrać całą tę wiedzę i zacząć wdrażać ją w projektach.
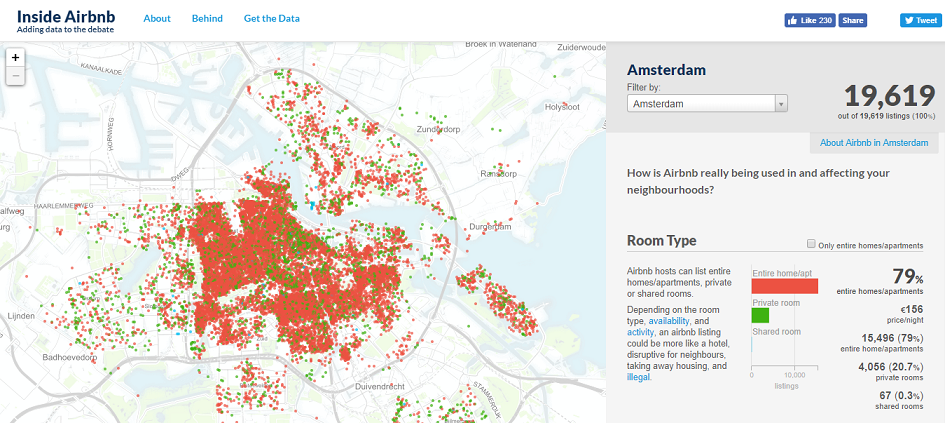
Możesz sprawdzić te zbiory danych Kaggle, aby rozpocząć swoje pierwsze projekty uczenia maszynowego. Powyższy obraz pochodzi z (bezpłatnego publicznego) zbioru danych oferowanego przez Inside Airbnb, który udostępnia oferty Airbnb w różnych miastach na całym świecie.
Krok 4: Przenieś sprawy na wyższy poziom dzięki Hadoop i Spark

Hadoop i Spark to 2 systemy, z którymi będziesz chciał się uporać po osiągnięciu pewnej biegłości w pracy z zestawami danych przy użyciu języka Python. Te struktury Big Data umożliwią pracę z danymi w skali terabajtów i petabajtów.

Notesy Spark Jupyter hostowane w Databricks oferują wprowadzenie do platformy na poziomie samouczka, a także zapewniają ćwiczenie z kodowaniem.
Krok 5: Przejdź na TensorFlow

Algorytmy uczenia maszynowego? Sprawdzać. Ramy Big Data? Sprawdzać. Zaawansowane uczenie maszynowe? Zacznij pracę z TensorFlow.
Możesz wziąć TensorFlow i Deep Learning bez doktoratu. kurs Google z edukacją studenta o aspektach teoretycznych i praktycznych. W tym momencie możesz również skorzystać z certyfikacji PG UpGrad w zakresie uczenia maszynowego i głębokiego uczenia się.
Krok 6: Rozwijaj się

Po pracy ze wszystkimi blokami konstrukcyjnymi nadszedł czas, aby zmagać się z dużymi zestawami danych i zastosować całą wiedzę zdobytą w poprzednich 5 krokach.
Zapoznaj się ze sposobami obsługi plików danych dla uczenia maszynowego , aby dowiedzieć się, jak obsługiwać duże zestawy danych (teoretycznie). Następnie zaimplementuj zdobytą wiedzę za pomocą Publicznie Dostępnych Zbiorów Danych.
Krok 7: Ćwicz i rozwijaj się

Ostatnim krokiem jest po prostu przećwiczenie i powtórzenie wyżej wymienionych 6 kroków. Jesteś teraz w punkcie, w którym możesz budować własne modele uczenia maszynowego. Nadszedł czas, aby udoskonalić te umiejętności i być coraz lepszym.
Jeśli praca jest Twoim lśniącym garnkiem złota na końcu tęczy, możesz przygotować się na rozmowę kwalifikacyjną, przechodząc przez niezbędne pytania dotyczące uczenia maszynowego — regresja logistyczna.
Powyższe wysoce praktyczne kroki zapewnią, że nauczysz się, jak zostać inżynierem uczenia maszynowego w jak najkrótszym czasie i nadal opanujesz wszystkie wymagane umiejętności. Jedyna wymagana rzecz. Konsekwencja i regularna praktyka. Uzbrojony w te 2 cechy, nie ma powodu, dla którego Twoje pragnienie zostania inżynierem uczenia maszynowego nie zostanie spełnione.
Czas powitać nową erę technologii z Tobą jako jej zwiastunem.
Kto może studiować uczenie maszynowe?
Uczenie maszynowe to wiodąca technologia wykorzystująca sztuczną inteligencję. Kariera w uczeniu maszynowym jest trudna i satysfakcjonująca. Uczenie maszynowe to złożona dziedzina, która wymaga wiedzy z zakresu nauki o danych, programowania, narzędzi głębokiego uczenia itp. Lista może stale rosnąć wraz z rozwojem dziedziny. Zaletą jest to, że w Internecie można znaleźć szeroką gamę kursów z zakresu Data Science, Machine Learning, Inżynierii oprogramowania. Licencjat z informatyki, statystyki lub matematyki jest preferowany do kariery w uczeniu maszynowym.
Czy uczenie maszynowe to wiecznie zielone pole?
Uczenie maszynowe szybko ewoluowało w ciągu ostatnich kilku lat i oczekuje się, że w nadchodzących dziesięcioleciach wzrośnie znacznie bardziej. W uczeniu maszynowym wykorzystano różne narzędzia, które doprowadziły do globalnych zastosowań, od sztucznej inteligencji po rozgałęzienie w poddziedzinie. Przewiduje się, że globalny rynek uczenia maszynowego do 2024 r. będzie wart aż 30,6 miliarda dolarów. Uczenie maszynowe zostało zintegrowane z sztuczną inteligencją, tworząc modele, widzenie komputerowe, robotykę, audio i rozpoznawanie wideo oraz umacniając swój wpływ na branżę technologiczną. Nie ogranicza się już do aplikacji komputerowych; rozciąga się na inne obszary w branży, aby wspomóc ich rozwój.
Jakie kariery możesz rozpocząć po uczeniu maszynowym?
Kariera w uczeniu maszynowym będzie dynamiczna i futurystyczna, oferując wyzwanie, uznanie i stabilność. Zakres uczenia maszynowego rozciąga się z branży technologicznej i integruje się z innymi obszarami. Aby zostać specjalistą ds. uczenia maszynowego, nie musisz już mieć doświadczenia z ML. Dogłębna znajomość oprogramowania, Data Science, umiejętności technicznych i miękkich itp. to podstawowe wymagania, aby rozpocząć karierę w ML. Inżynier ML koncentruje się bardziej na językach programowania, podczas gdy analityk danych przewiduje opłacalne rozwiązania, analizując dane. Mimo że uczenie maszynowe może mieć wiele karier, wszystkie one wykorzystują podstawy uczenia maszynowego, nauki o danych, analityki i NLP.