
Python으로 처음부터 신경망 구현하기 [예제 포함]
게시 됨: 2020-12-07이 기사에서는 스크래치에서 신경망을 훈련하고 구축하는 방법을 배웁니다.
우리는 Churn 데이터셋을 사용하여 신경망을 훈련할 것입니다. 신경망 훈련은 복잡하지 않습니다. 모델이 쉽게 데이터를 가져와 장애물 없이 스스로 학습할 수 있도록 데이터를 사전 처리해야 합니다. 다음과 같이 진행합니다.
- 텐서플로 설치
- 라이브러리 가져오기
- 데이터 세트 가져오기
- 입력 데이터 변환
- 데이터 분할
- 모델 초기화
- 모델 구축
- 모델 훈련
- 모델 평가
해지율은 회사의 가입자 또는 특정 기간에 중단되는 경향이 있는 당사자의 측정값입니다. 이 비율은 이익을 결정하고 새로운 고객을 확보하기 위한 계획을 수립하는 데 필수적인 역할을 합니다. 간단히 말해서 기업의 성장은 해지율로 측정할 수 있다고 말할 수 있습니다.
이 데이터 세트에는 13개의 기능이 있지만 요구 사항을 충족하는 몇 가지 기능만 사용하여 사용자를 중단할 가능성을 예측합니다.
세계 최고의 대학에서 기계 학습 온라인 과정 을 배우십시오. 석사, 이그 제 큐 티브 PGP 또는 고급 인증 프로그램을 획득하여 경력을 빠르게 추적하십시오.
목차
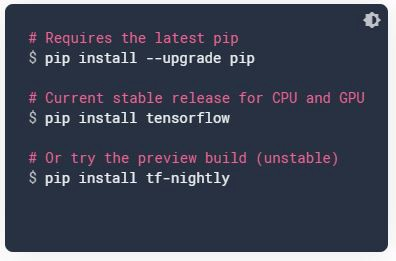
텐서플로우 설치
PC 또는 노트북에 GPU가 없으면 Google Colab을 사용하거나 Jupyter 노트북을 사용할 수 있습니다. 시스템을 사용하는 경우 pip를 업그레이드한 후 다음과 같이 TensorFlow를 설치합니다.

이미지 소스
라이브러리 가져오기
위의 코드 라인에서 프로세스에 필요한 모든 라이브러리를 가져왔습니다.
Numpy → 배열에 대한 수학 연산을 수행하는 데 사용되는 라이브러리입니다.
Pandas → Pandas 데이터 프레임으로 데이터 파일을 로드하고 데이터를 분석합니다.
Matplotlib → 데이터 그래프를 그리기 위해 pyplot을 가져왔습니다 .
데이터 세트 가져오기
데이터 세트는 CSV 형식이므로 pandas 작업을 사용하여 데이터 세트를 로드합니다. 그런 다음 데이터 세트를 종속 및 독립 변수로 분할합니다. 여기서 X는 독립으로 간주되고 Y는 종속으로 간주됩니다.
데이터 변환
데이터 세트에는 지리 와 성별 이라는 두 가지 범주형 기능이 있습니다 . 이 두 기능에 대한 더미를 만들어야 하므로 get_dummies 메서드를 사용한 다음 이를 독립 기능 데이터에 추가합니다.
더미를 만들고 데이터에 연결하면 기차 데이터에서 원래 기능(예: 성별 및 지리)을 제거합니다.

읽기: 머신 러닝과 신경망
데이터 분할
하위 라이브러리인 model_selection인 Sklearn에서 train_test_split을 가져오며, 이는 훈련 세트와 테스트 세트를 분할하는 데 사용됩니다. 우리는 분할을 수행하기 위해 train_test_split 함수를 사용할 수 있습니다. test_size = 0.3은 테스트를 위해 보류해야 하는 데이터의 백분율을 나타냅니다.
데이터 정규화
모든 특성 값이 동일한 범위에 있는지 확인하는 것이 중요합니다. 모델이 기능 간의 기본 패턴을 학습하고 결정을 내리는 방법을 배우는 것은 어려울 수 있으므로 StandardScaler 방법을 사용하여 데이터를 동일한 범위로 정규화합니다.
종속성 가져오기
이제 심층 신경망을 구성하는 데 필요한 기능을 가져옵니다.
모델 구축
이제 우리의 모델을 만들 시간입니다!. 이제 순차 모델을 초기화해 보겠습니다. 순차 API를 사용하면 대부분의 문제에 대해 레이어별로 모델을 생성할 수 있습니다.
모델을 만들기 전에 가장 먼저 해야 할 일은 모델 개체 자체를 만드는 것입니다. 이 개체는 Sequential이라는 클래스의 인스턴스가 됩니다.
첫 번째 완전 연결 계층 추가
레이어의 유형과 기능에 대해 잘 모르는 경우 알고 있어야 하는 대부분의 개념을 알려주는 신경망 소개에 대한 내 블로그를 확인하는 것이 좋습니다.
이것은 이 연산의 출력이 선형성을 깨기 위해 ReLU 활성화 함수를 적용하는 6개의 뉴런을 가져야 한다는 것을 의미하고 입력 뉴런의 수는 11입니다. 우리는 .add() 메소드를 사용하여 이러한 모든 하이퍼파라미터를 추가합니다.
이 은닉층의 출력에 6개의 노드가 있는 동일한 구성의 은닉층을 추가합니다.
출력 레이어
이 계층의 출력에는 사용자가 구독을 유지하는지 또는 떠나는지 알려주는 노드가 하나만 있습니다. 이 계층에서는 활성화 함수로 sigmoid를 사용합니다.
자세히 알아보기: 딥 러닝과 신경망
컴파일
이제 네트워크를 옵티마이저와 연결해야 합니다. 최적화 프로그램은 오류를 기반으로 네트워크의 가중치를 업데이트합니다. 이 프로세스를 역전파라고 합니다.
여기서 우리는 옵티마이저로 adam 을 사용할 것입니다. 우리의 결과는 이진법에 관한 것이기 때문에 이진 교차 엔트로피를 사용하고 우리가 사용하는 메트릭은 정확도 입니다.
모델 훈련
이 단계는 기본 패턴, 데이터 간의 관계를 학습하고 지식을 기반으로 새로운 결과를 예측하기 위해 모델을 훈련해야 하는 중요한 경로입니다.
model.fit() 메서드를 사용 하여 모델을 훈련합니다. 메서드 내부에 세 개의 인수를 전달합니다.
입력 → x_train은 네트워크에 공급되는 입력입니다.
출력 → 여기에는 x_train, 즉 y_train에 대한 정답이 포함됩니다.
no.of.epochs → 데이터셋으로 네트워크를 학습시킬 횟수를 의미합니다.
평가하다
두 개의 인수를 전달해야 하는 sklearn 라이브러리에서 accuracy_score를 가져와서 모델의 성능을 평가할 수 있습니다. 하나는 실제 출력이고 다른 하나는 예측 출력입니다.
더 읽어 보기: 현실 세계의 신경망 애플리케이션
결론
지금은 여기까지입니다. 첫 번째 신경망 구축이 즐거웠기를 바랍니다. 행복한 배움!
기계 학습에 대해 자세히 알아보려면 IIIT-B 및 upGrad의 기계 학습 및 AI 경영자 PG 프로그램을 확인하세요. 이 프로그램은 일하는 전문가를 위해 설계되었으며 450시간 이상의 엄격한 교육, 30개 이상의 사례 연구 및 과제, IIIT를 제공합니다. -B 동문 자격, 5개 이상의 실용적인 실습 캡스톤 프로젝트 및 최고의 기업과의 취업 지원.