
تنفيذ الشبكات العصبية من الصفر باستخدام بايثون [مع أمثلة]
نشرت: 2020-12-07في هذه المقالة ، سوف نتعلم كيفية تدريب وبناء شبكة عصبية من سكراتش.
سنستخدم مجموعة بيانات Churn لتدريب شبكتنا العصبية. تدريب الشبكة العصبية ليس معقدًا. نحتاج إلى معالجة بياناتنا مسبقًا حتى يتمكن نموذجنا من أخذ بياناتنا بسهولة وتدريب نفسه دون أي عقبات. سوف تمضي على النحو التالي:
- قم بتثبيت Tensorflow
- مكتبات الاستيراد
- قم باستيراد مجموعة البيانات
- تحويل بيانات الإدخال
- تقسيم البيانات
- تهيئة النموذج
- بناء النموذج
- تدريب النموذج
- قم بتقييم النموذج
معدل التموج هو مقياس المشتركين في الشركة أو الطرف الذي يميل إلى التوقف في فترة زمنية محددة. يلعب هذا المعدل دورًا أساسيًا في تحديد الأرباح ووضع الخطط لكسب عملاء جدد. بعبارات بسيطة ، يمكننا القول أنه يمكن قياس نمو الشركة من خلال معدل Churn.
في مجموعة البيانات هذه ، لدينا ثلاثة عشر ميزة ، لكننا نستخدم فقط بعض الميزات التي تفي بمتطلباتنا للتنبؤ بفرصة التوقف عن مستخدم.
تعلم دورة التعلم الآلي عبر الإنترنت من أفضل الجامعات في العالم. احصل على درجة الماجستير أو برنامج PGP التنفيذي أو برامج الشهادات المتقدمة لتسريع مسار حياتك المهنية.
جدول المحتويات
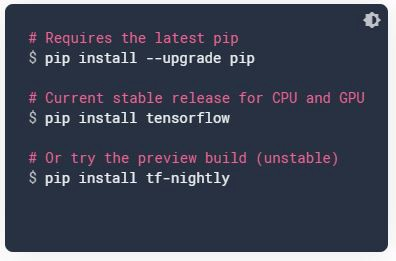
قم بتثبيت TensorFlow
يمكننا إما استخدام Google Colab إذا كان جهاز الكمبيوتر أو الكمبيوتر المحمول الخاص بك لا يحتوي على GPU أو يمكنك استخدام Jupyter Notebooks. إذا كنت تستخدم نظامك ، فقم بترقية النقطة ، ثم قم بتثبيت TensorFlow على النحو التالي.

مصدر الصورة
مكتبات الاستيراد
في سطور الكود أعلاه ، قمت للتو باستيراد جميع المكتبات التي سأحتاجها في هذه العملية.
Numpy → هي مكتبة تستخدم لإجراء عمليات حسابية على المصفوفات.
Pandas → لتحميل ملف البيانات كإطار بيانات Pandas وتحليل البيانات.
Matplotlib → لقد قمت باستيراد pyplot لرسم الرسوم البيانية للبيانات .
استيراد مجموعة البيانات
مجموعة البيانات الخاصة بنا بصيغة CSV ، لذلك نقوم بتحميل مجموعة البيانات باستخدام عمليات الباندا. ثم قمنا بتقسيم مجموعة البيانات إلى متغيرات تابعة ومستقلة ، حيث تعتبر X مستقلة ، وتعتبر Y على أنها تابعة.
تحويل البيانات
في مجموعة البيانات الخاصة بنا ، لدينا ميزتان فئويتان ، الجغرافيا والجنس . نحتاج إلى إنشاء دمى لهاتين الميزتين ، لذلك نستخدم طريقة get_dummies ثم نلحقها ببيانات الميزات المستقلة.

بمجرد أن ننتهي من إنشاء دمى وربطها ببياناتنا ، سنزيل الميزات الأصلية ، أي الجنس والجغرافيا ، من بيانات القطار الخاصة بنا.
قراءة: التعلم الآلي مقابل الشبكات العصبية
تقسيم البيانات
من Sklearn ، نموذج_الاختيار للمكتبة الفرعية ، سنقوم باستيراد train_test_split ، والذي يُستخدم لتقسيم مجموعات القطار والاختبار. يمكننا استخدام الدالة train_test_split لإجراء الانقسام. يشير حجم test_size = 0.3 إلى النسبة المئوية للبيانات التي يجب الاحتفاظ بها للاختبار.
تطبيع البيانات
من الضروري التأكد من أن جميع قيم الميزات تقع في نفس النطاق. سيكون من الصعب على النموذج معرفة الأنماط الأساسية بين الميزات وتعلم كيفية اتخاذ القرارات ، لذلك نقوم بتطبيع بياناتنا في نفس النطاق باستخدام طريقة StandardScaler .
تبعيات الاستيراد
الآن ، سنقوم باستيراد الوظائف المطلوبة لبناء شبكة عصبية عميقة.
بناء النموذج
حان الوقت لبناء نموذجنا !. الآن دعونا نبدأ نموذجنا المتسلسل. تسمح لك واجهة برمجة التطبيقات المتسلسلة بإنشاء نماذج طبقة تلو طبقة لمعظم المشكلات.
أول شيء يتعين علينا القيام به قبل بناء نموذج هو إنشاء كائن نموذجي نفسه. سيكون هذا الكائن مثيلاً للفئة المسماة Sequential.
إضافة أول طبقة متصلة بالكامل
إذا لم تكن على دراية بأنواع الطبقات ووظائفها ، فإنني أوصي بمراجعة مدونتي على مقدمة إلى الشبكات العصبية ، والتي تتيح لك معرفة معظم المفاهيم التي يجب أن تكون على دراية بها.
هذا يعني أن ناتج هذه العملية يجب أن يحتوي على ستة خلايا عصبية نطبق فيها وظيفة تنشيط ReLU لكسر الخطية ، وعدد الخلايا العصبية المدخلة هو 11. نضيف كل هذه المعلمات الفائقة باستخدام طريقة .add () .
سنضيف طبقة مخفية بنفس التكوين حيث سيكون لمخرجات هذه الطبقة المخفية ستة عقد.
طبقة الإخراج
سيكون لمخرجات هذه الطبقة عقدة واحدة فقط ، والتي تخبر ما إذا كان المستخدم سيبقى أو غادر الاشتراك. في هذه الطبقة ، نستخدم السيني كوظيفة التنشيط لدينا.
تعرف على المزيد حول: Deep Learning vs Neural Networks
تجميع
الآن نحن بحاجة إلى ربط شبكتنا بمحسِّن. سيقوم المُحسِّن بتحديث أوزان شبكتنا بناءً على الخطأ. تُعرف هذه العملية بالانتشار الخلفي.
هنا سوف نستخدم آدم كمحسِّن لدينا. نظرًا لأن نتيجتنا تتعلق بالثنائي ، فإننا نستخدم الانتروبيا الثنائية ، والمقاييس التي نستخدمها هي الدقة .
تدريب النموذج
هذه المرحلة هي المسار الحاسم حيث نحتاج إلى تدريب نموذجنا لمعرفة الأنماط الأساسية والعلاقات بين البيانات والتنبؤ بالنتيجة الجديدة بناءً على معرفتها.
نستخدم طريقة model.fit () لتدريب النموذج. نقوم بتمرير ثلاث حجج داخل العملية ، وهي
الإدخال → x_train هو الإدخال الذي يتم تغذيته للشبكة
الناتج → هذا يحتوي على الإجابات الصحيحة لـ x_train ، أي y_train
no.of.epochs → يعني عدد المرات التي ستقوم فيها بتدريب الشبكة باستخدام مجموعة البيانات.
يقيم
يمكنك تقييم أداء النموذج عن طريق استيراد دقة الدرجات من مكتبة sklearn التي تحتاج فيها إلى تمرير وسيطتين. أحدهما هو الناتج الفعلي ، والآخر هو المخرجات المتوقعة.
اقرأ أيضًا : تطبيقات الشبكة العصبية في العالم الحقيقي
خاتمة
هذا كل شئ حتى الان. أتمنى أن تكون قد استمتعت ببناء شبكتك العصبية الأولى. تعلم سعيد!
إذا كنت مهتمًا بمعرفة المزيد عن التعلم الآلي ، فراجع برنامج IIIT-B & upGrad's Executive PG في التعلم الآلي والذكاء الاصطناعي المصمم للمهنيين العاملين ويقدم أكثر من 450 ساعة من التدريب الصارم ، وأكثر من 30 دراسة حالة ومهمة ، IIIT -ب حالة الخريجين ، 5+ مشاريع التخرج العملية العملية والمساعدة في العمل مع الشركات الكبرى.