
Feuilles de triche d'apprentissage automatique que tout ingénieur ML devrait connaître
Publié: 2020-07-29Au cours des deux dernières décennies, l'apprentissage automatique a radicalement changé la façon dont les choses fonctionnent et la façon dont les décisions sont prises. Aujourd'hui, presque toutes les industries utilisent efficacement différents concepts d'apprentissage automatique d'une manière ou d'une autre. Pour cette raison, il y a eu une augmentation drastique du nombre d'emplois liés à l'apprentissage automatique, et de plus en plus de demandeurs d'emploi et de débutants font de leur mieux pour acquérir des compétences en apprentissage automatique.
Nous savons tous que l'apprentissage automatique est un vaste domaine et qu'il existe de nombreux concepts dont il faut se souvenir, même s'il est fréquemment exposé à des tâches similaires. Par conséquent, il devient facile pour les apprenants de réviser et de revisiter les concepts de base et les astuces s'ils ont accès à quelques notes courtes. Cela les aide à se préparer aux entretiens, à se référer tout en apportant de nouveaux changements et même à découvrir rapidement un nouveau concept. Par conséquent, dans cet article, nous énumérerons les meilleures feuilles de triche d'apprentissage automatique qui aideront les professionnels et les apprenants de l'apprentissage automatique.
Table des matières
Feuille de triche Python par Dave Child
Pour démarrer tout développement numérique, il faut un langage de programmation. Python est le langage de programmation préféré des passionnés d'apprentissage automatique en raison de sa facilité d'utilisation, de son accessibilité totale et de son excellent support communautaire. Par conséquent, garder la syntaxe et les astuces de base à portée de main aide chaque fois que vous avez besoin de parfaire le fonctionnement du langage.
Cette belle feuille de Dave Child contient toutes les fonctions essentielles des chaînes, des listes, etc. Elle contient également un vaste ensemble d'informations sur le système et les variables locales, le découpage et les méthodes de formatage des données. Par conséquent, pour les passionnés d'apprentissage automatique, cette feuille de triche pour Python répond à l'objectif de mémorisation et de référencement rapides.
La feuille de triche Python pour les amateurs d'apprentissage automatique par Dave Child peut être trouvée ici .
Aide-mémoire Numpy par Justin
Nous savons tous que l'apprentissage automatique est une question de chiffres. En fait, dans l'apprentissage automatique, nous avons un grand ensemble ou de grands tableaux de nombres. Bien qu'il existe des options intégrées telles que des listes et des tuples pour gérer ces données, elles ne sont pas aussi utilisables que les exigences. Ainsi, la plupart des passionnés d'apprentissage automatique utilisent une bibliothèque dédiée aux calculs numériques appelée Numpy.

Numpy est l'une des bibliothèques les plus populaires qui peut gérer de grands tableaux et les manipuler en fonction des besoins des utilisateurs. Tout en jouant avec un large ensemble de données, Numpy fait gagner beaucoup de temps à l'utilisateur et lui permet de comprendre intuitivement plus facilement le flux et la structure des données.
Cette belle feuille de triche de Justin couvre toutes les principales techniques syntaxiques utilisées dans Numpy. Il comprend toutes les opérations sur les tableaux primaires, l'accès multidimensionnel, etc. Une vue rapide de la distribution ordinaire et binomiale est également fournie.
La feuille de triche d'apprentissage automatique Numpy est accessible ici .
Pandas Cheat Sheet par Sanjeev
Si vous pratiquez un apprentissage automatique intensif, il y a de fortes chances que vous lisiez et écriviez régulièrement différents types de données. Bien que Python ait des bibliothèques intégrées pour effectuer la tâche, il ne répond pas aux attentes en matière de lecture et d'analyse de grandes quantités de données complexes. Pour cela, la plupart des professionnels de l'apprentissage automatique et des apprenants utilisent Pandas.
Pandas est une bibliothèque qui permet aux utilisateurs de lire très facilement des formulaires de données complexes, de sélectionner des informations importantes et d'écrire des données en conséquence. Par conséquent, garder une feuille de triche à portée de main aide à référencer rapidement la syntaxe et les techniques.
Cette feuille de triche fournit un aperçu rapide des fonctions essentielles telles que la lecture des données, la sélection du tri, etc. En plus de cela, elle comprend également des requêtes de données de base telles que les jointures, les fusions, etc.
La feuille de triche d'apprentissage automatique Pandas est accessible ici .
Aide-mémoire Matplotlib par Justin
Matplotlib peut dessiner rapidement des graphiques et des diagrammes complexes.
La source
Lorsque vous êtes censé travailler avec une énorme quantité de données, il devient parfois difficile d'analyser et de visualiser le type et le flux de données. Avant de faire des algorithmes, il est impératif de comprendre comment les données se comportent. À cette fin, nous utilisons des représentations visuelles. Il existe plusieurs graphiques et tracés comme un graphique à barres, une boîte à moustaches, des graphiques linéaires, etc. qui peuvent être tracés à cette fin.

Matplotlib est une bibliothèque magnifiquement conçue qui aide les utilisateurs à tracer plusieurs types de graphiques en un seul endroit. Il est tendance pour sa facilité d'utilisation et sa flexibilité.
Cette feuille de triche vous donne un accès instantané pour tracer des diagrammes et des figures de base. Il montre toute la syntaxe du composant populaire Pyplot de matplotlib pour tracer des graphiques à barres, des graphiques linéaires, des légendes, des camemberts, etc.
La feuille de triche d'apprentissage automatique Matplotlib peut être trouvée ici .
Aide-mémoire Scikit Learn par Sati
Nous avons maintenant toutes les feuilles de triche nécessaires pour gérer les données. Une fois que nous obtenons les données, nous avons tendance à leur appliquer des algorithmes et des modèles d'apprentissage automatique dans le but de mieux comprendre les données structurées. Rédiger des modèles à partir de zéro est une tâche très fastidieuse et répétitive. Par conséquent, les professionnels ont développé des bibliothèques spécifiques pour exécuter ces modèles et former de plus en plus de nouveaux modèles sur les ensembles de données que nous obtenons.
L'une de ces bibliothèques est Scikit Learn. C'est l'une des bibliothèques les plus populaires utilisées pour former de nouveaux modèles et les tester sur des données réelles. Différents algorithmes allant de la régression logistique au clustering complexe peuvent être utilisés à l'aide de cette bibliothèque. Par conséquent, il est essentiel de garder à portée de main toute la syntaxe et les concepts de base.
Cette feuille de triche comprend toute la syntaxe de base et la théorie de la régression, de la validation croisée, du clustering, etc., complétée par des visualisations triviales.
La feuille de triche d'apprentissage automatique pour Scikit Learn est accessible ici .
Feuille de triche d'apprentissage en profondeur 1webzem
Les modèles d'apprentissage en profondeur offrent une meilleure précision sur une grande quantité de données.
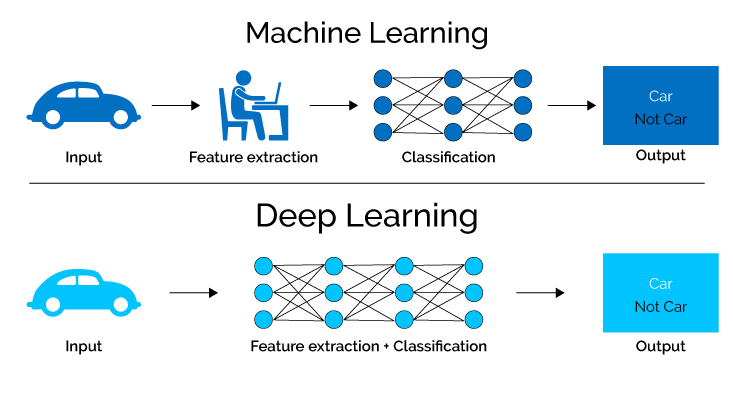
La source
Bien que Scikit couvre une large gamme d'algorithmes d'apprentissage automatique, lorsque les données deviennent plus massives et que les modèles deviennent complexes, ces algorithmes tendent vers un point de saturation en termes de précision. Par conséquent, nous avons besoin de modèles plus sophistiqués et robustes alimentés par Deep Learning. Les mathématiques et la théorie impliquées dans les algorithmes d'apprentissage en profondeur sont très complexes et nécessitent des révisions fréquentes. Par conséquent, l'utilisation d'une feuille de triche est très conseillée.
La feuille de triche d'apprentissage en profondeur de 1webzem contient la plupart des algorithmes sous-jacents, la syntaxe de la bibliothèque d'apprentissage en profondeur la plus populaire - Keras, et quelques concepts théoriques fréquemment utilisés.
La feuille de triche d'apprentissage automatique pour l'apprentissage en profondeur est accessible ici .
Lisez aussi: Aide-mémoire Tensorflow
La route à suivre
Si vous êtes un passionné d'apprentissage automatique et que vous souhaitez progresser dans votre carrière, vous devriez opter pour le diplôme PG d'upGrad en apprentissage automatique et IA. Ce programme est encadré par l'un des meilleurs instructeurs de l'IIIT-B. Il couvrira tous les sujets essentiels tels que la visualisation de données, l'apprentissage automatique, l'apprentissage en profondeur, etc., suivis de projets industriels réels.
Quelles sont les compétences nécessaires pour devenir ingénieur en machine learning ?
Vous devez certainement avoir une bonne compréhension des concepts de génie logiciel et de programmation. De plus, vous devez être familiarisé avec des concepts tels que la PNL, l'apprentissage par renforcement, etc. Outre les compétences techniques, certaines compétences générales sont également requises. Vous devez savoir communiquer avec vos clients et les membres de votre équipe. Dernier point mais non le moindre, vous devriez avoir soif d'en savoir plus sur le ML afin de grandir et éventuellement de bien performer.
Quelles sont les certifications obligatoires requises si vous souhaitez devenir ingénieur ML ?
La plupart des emplois d'ingénierie en apprentissage automatique nécessitent un baccalauréat dans un domaine connexe comme l'informatique, les mathématiques ou les statistiques, et certains exigent même une maîtrise ou un doctorat. dans l'apprentissage automatique, la vision par ordinateur, les réseaux de neurones, l'apprentissage en profondeur ou un autre sujet similaire. Les certifications en apprentissage automatique, en intelligence artificielle ou en science des données sont bénéfiques en dehors de l'enseignement supérieur car elles offrent des compétences applicables.
Dois-je apprendre SQL si je veux devenir ingénieur en machine learning ?
En apprentissage automatique, la détection de formes est une étape cruciale. En organisant d'énormes quantités de données, SQL améliore considérablement la reconnaissance des formes. SQL est le langage le plus simple pour interroger des données. De plus, la maîtrise de SQL vous permettra de tirer parti ultérieurement de l'efficacité en combinant SQL avec Python. Par conséquent, SQL exploite les avantages du langage R lorsqu'il est utilisé en combinaison avec une base de données relationnelle pour les applications d'apprentissage automatique. Si vous voulez être un ingénieur en apprentissage automatique, comprendre SQL est non seulement nécessaire, mais cela facilitera également une grande partie de votre travail.