
KerasとPyTorch:KerasとPyTorchの違い
公開: 2020-12-28この記事を読んでいる場合は、ディープラーニングの分野に足を踏み入れており、おそらく最初のディープラーニングプロジェクトを構築する途中である可能性があります。 ディープラーニングで利用できる多数のフレームワークとライブラリ(Keras、PyTorch、Tensorflow、FastAPIなど)について混乱しているかもしれません。

ディープラーニングのためのさまざまなフレームワーク
この記事では、KerasとPyTorchの比較について説明します。これらはディープラーニングで最も人気のある2つのAPI/フレームワークです。 また、2つのうちどちらが次のディープラーニングプロジェクトの構築に適しているかについても学習します。
比較は、次の要因に基づいて行われます。
- 創発
- 使いやすさ
- デバッグ
- パフォーマンス
- 人気
- 結論:いつ、なぜ何を使用するのですか?
目次
創発
Kerasはディープラーニングの高レベルAPIです。 これは、Tensorflow(Googleによるもう1つの人気のあるディープラーニングフレームワーク)上に構築されたオープンソースライブラリであり、Tensorflowコードの記述と実行がはるかに簡単になります。 Kerasは、開発者がそれほど複雑にすることなくディープラーニングモデルを構築できるようにすることを使命として、2015年にFrancoisCholletによって開発されました。 使いやすさと構文の単純さで非常に人気があります。
PyTorchは、Pythonディープラーニングの低レベルフレームワーク(Tensorflowなど)です。 トーチライブラリをベースにしたオープンソースライブラリです。 PyTorchは、2016年にFacebookのAIリサーチチームによって開発されました。PyTorchは、Kerasとは異なり、初心者にとってはそれほど簡単ではないかもしれません。 しかし、PyTorchが提供するのは、大規模な実世界のデータセットに対する優れた柔軟性と非常に高速な実行です。

勝者:描く
また読む: TensorflowとPyTorch
使いやすさ
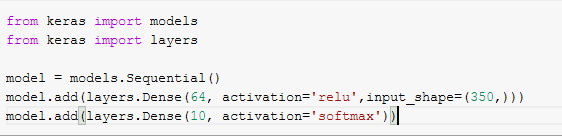
実は、Kerasは、PyTorchと比較して、ディープラーニングを学習するための頼りになるフレームワークでした。 前に述べたように、Kerasは構文的に簡単であるべきだということを念頭に置いて開発されました。 したがって、深層学習モデルを準備する際の基本的な手順は、データの読み込み、モデルの定義、モデルのコンパイル、モデルのトレーニング、そして最後に評価です。 上記のすべての手順は、非常に数行のコードで実行できます。 たとえば、単純なニューラルネットワークモデルを定義するために、Kerasでできることは次のとおりです。
モデル定義
ご覧のとおり、いくつかのハイパーパラメータを指定してmodel.add(…)を使用するだけで、ニューラルネットワークモデルにレイヤーを挿入できます。 別のmodel.add(…)とブーム! 別のレイヤー! とても簡単です。
ここで、モデルの定義とコンパイルの後、いくつかのデータセットでモデルをトレーニングする必要があります。
ええと、Kerasの場合、それは簡単なことです。 入力データと出力データ、およびいくつかのハイパーパラメータに言及しているmodel.fit(…)を使用するだけで、出来上がりです! モデルはトレーニングプロセスを正常に開始します(1行のコードのみ)。
![]()
これらのシンプルで簡潔で読みやすい構文により、Kerasはディープラーニングの初心者だけでなく開発者の間でも非常に人気のある言語になっています。
一方、PyTorchは少し簡潔ではなく、より複雑になっています。 PyTorchを使用すると、ディープラーニングモデルを実行するためのすべての基本的な手順を明示的に実行する必要があります。 モデルをトレーニングするだけの場合は、次のことを行う必要があります。トレーニングの各バッチの開始時に重みを初期化し、順方向パスと逆方向パスを実行し、損失を計算し、それに応じて重みを更新します。
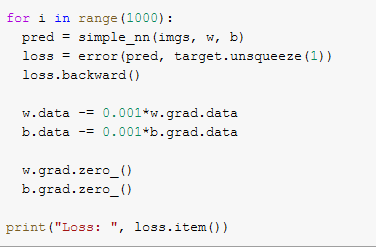

PyTorchトレーニングセクションだけ
PyTorchを使用すると、細部に精通する必要があるため、PyTorchを使用して、ディープラーニングの分野に参入したばかりの初心者にとっては非常に困難な作業になる可能性があることがわかります。
勝者: Keras
デバッグ
デバッグは物事が面白くなるところです。
ご存知のように、Kerasには.fit(…)、.compile(…)などの単純な関数がたくさんあり、コードを簡単に書くのに役立ちます。 したがって、Kerasでは、エラーが発生する可能性はわずかです。 ただし、コードにエラーが発生した場合(これは完全に正常です)、通常、デバッグは非常に困難です。 その理由は、非常に多くの詳細がさまざまな関数にカプセル化されているため、実際にどこが間違っているかを見つけるために、それらすべての詳細を視覚化する必要があるためです。
明示的に示されたPyTorchコードを使用すると、デバッグが非常に簡単になります。 ニューラルネットワークのすべての詳細がコードに示されているため、エラーを見つけるのは比較的簡単な作業です。 重み、バイアス、ネットワークレイヤーを必要に応じて変更してから、モデルの実行を再試行できます。
勝者: PyTorch
パフォーマンス
さて、パフォーマンスの面では、KerasはPyTorchと比較して遅れています。
Kerasは構文上の理由から非常に人気があるかもしれませんが、巨大なデータセットを扱う場合は一般的には好まれません。 Kerasは計算が遅く、プロトタイプのようなモデルについて最初のアイデアを持っている必要がある小さなデータセットに一般的に使用されます。 これらのモデルには通常、巨大なデータセットやオンラインデータセットがないため、多くの初心者が最初のDLモデルとして使用します。
PyTorchはこの要素で本当に輝いています。 PyTorchとTensorFlowは、ユーザーが巨大なデータセットを処理する際のフレームワークとして使用されます。 PyTorchは、Kerasよりもはるかに高速で、メモリと最適化が優れています。 前述のように、PyTorchは、ディープラーニングモデルを定義または変更する柔軟性を提供するのに優れています。 したがって、PyTorchはスケーラブルなソリューションの構築に使用されます。 業界レベルのデータセットはPyTorchにとって問題ではなく、モデルを非常に簡単かつ迅速にコンパイルおよびトレーニングできます。
勝者: PyTorch
必読:オープンソースのディープラーニングライブラリ
人気
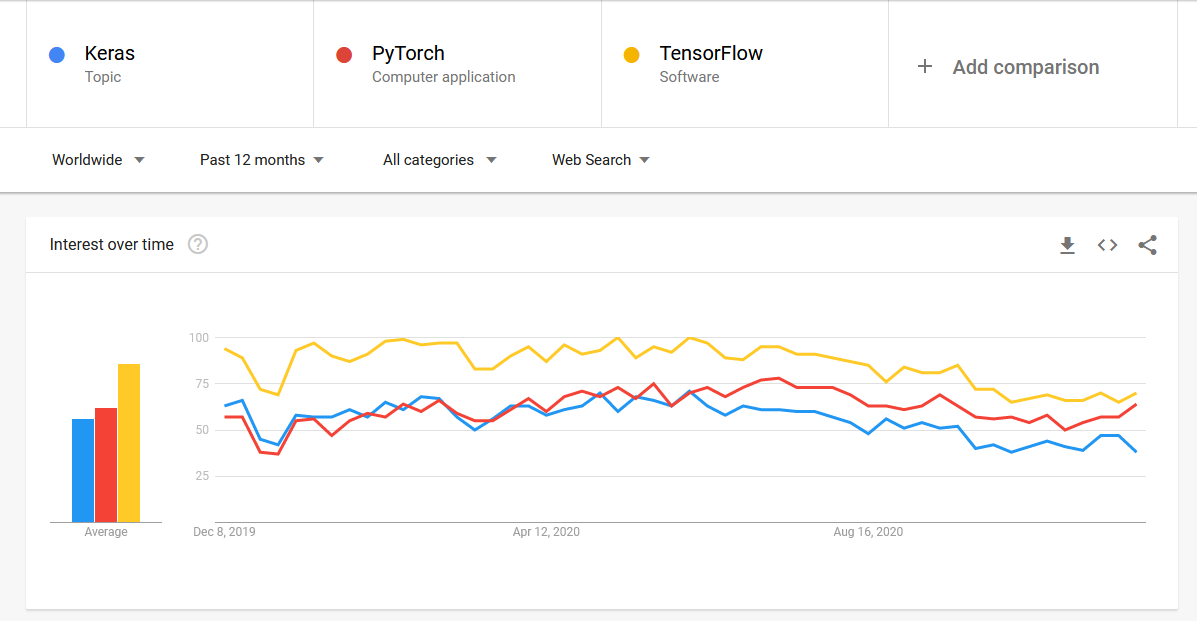
出典:Googleトレンド2020
まず、一方のフレームワークが他方よりも人気がある場合、研究者が常にその人気のあるフレームワークを他方よりも使用しているとは限らないということを言う必要があります。 問題ごとにフレームワークを切り替える傾向があります。
そうは言っても、上記のGoogle Trends 2020の視覚化からわかるように、TensorFlowは明らかに世界中で人気があり、PyTorchとKerasがそれに続きます。 同様の種類の結果は、ほとんどすべての視覚化で観察されます。 Tensorflowは、人気の点で間違いなく勝者です。 ただし、ネイティブのTensorflowまたはネイティブのKerasをPyTorchと比較することはできません。 私たちが目にする結果は、通常、TensorFlow v /sPyTorchのAPIとしてのKerasです。
勝者: Kerasを使用したTensorflow
結論
したがって、最後の質問が発生します。 KerasとPyTorchのどちらが良いですか?
まあ、答えはユーザーによって異なります。 ユーザーとしてディープラーニングの分野に参入したばかりで、最初のディープラーニングモデルの構築に非常に熱心な場合は、モデルにTensorFlowのインターフェースとしてKerasを実装する必要があります。 それは非常に初心者に優しいです、そしてまた素晴らしい役に立つオンラインコミュニティを持っています。 Kerasに感謝します。 ディープラーニングを教えることはかつてないほど容易になりました。
ただし、ディープラーニングの経験が比較的豊富な場合(おそらくこれをすでに知っている可能性があります)、もちろん、PyTorchは2つの中でより優れたフレームワークです。 PyTorchは急速に人気が高まっています。
ディープラーニング分野のパイオニアであるIanGoodfellow、Andrej Karpathy、スタンフォード大学などのトップ大学は、パフォーマンス、速度、柔軟性の点で優れているため、PyTorchに切り替えました。 PyTorchを使用すると、コンピュータービジョンの問題をこれまでになく簡単に解決できます。
ディープラーニングとそれに関連するさまざまなフレームワークの詳細については、upGradの機械学習とディープラーニングのPG認定コースをご覧ください。