
วิศวกรแมชชีนเลิร์นนิงทำอะไรได้บ้าง บทบาท ความรับผิดชอบ และทักษะ
เผยแพร่แล้ว: 2019-12-17ใน รายงาน Future of Work ปี 2019 ของ Robert Half , Brandon Purell นักวิเคราะห์อาวุโสของ Forrester Research กล่าวว่า:
“ความสำเร็จในอนาคตของบริษัทใดๆ ร้อยเปอร์เซ็นต์ขึ้นอยู่กับการนำแมชชีนเลิร์นนิงมาใช้ เพื่อให้บริษัทประสบความสำเร็จในยุคของลูกค้า พวกเขาจำเป็นต้องคาดการณ์สิ่งที่ลูกค้าต้องการ และการเรียนรู้ด้วยเครื่องเป็นสิ่งจำเป็นอย่างยิ่งสำหรับสิ่งนั้น”
ด้วยจำนวนองค์กรที่เพิ่มขึ้นในการสำรวจและใช้ประโยชน์จากเครื่องมือของ Data Science – AI และ ML – ความต้องการผู้เชี่ยวชาญที่มีทักษะในสาขาเหล่านี้จึงเพิ่มสูงขึ้น บทบาทของ Machine Learning Engineer เป็นหนึ่งในบทบาทด้าน Data Science ที่มีความต้องการสูงที่สุดในอุตสาหกรรม
วันนี้ เราจะเจาะลึกถึงบทบาทของ Machine Learning Engineer และทำความเข้าใจความรับผิดชอบและข้อกำหนดหลัก
สารบัญ
การเพิ่มขึ้นของการเรียนรู้ของเครื่อง
โดยพื้นฐานแล้ว บทบาทของ Machine Learning Engineer คือการแต่งงานระหว่างสองบทบาทสำคัญในอุตสาหกรรม – นักวิทยาศาสตร์ข้อมูลและวิศวกรซอฟต์แวร์
ในขณะที่จุดสนใจหลักของ Data Scientist คือการทดลองกับ Big Data วิศวกรซอฟต์แวร์มุ่งเน้นไปที่การเขียนโปรแกรม (การเขียนโค้ด) เป็นหลัก บทบาททั้งสองแตกต่างกันโดยเนื้อแท้ งานของ Data Scientist เป็นงานเชิงวิเคราะห์มากขึ้น ผู้เชี่ยวชาญด้านการวิเคราะห์เหล่านี้ใช้ทักษะทางคณิตศาสตร์ สถิติ การวิเคราะห์ และเครื่องมือ ML ผสมผสานกันเพื่อรวบรวม ประมวลผล และวิเคราะห์ชุดข้อมูลขนาดใหญ่เพื่อให้ได้ข้อมูลเชิงลึก

ในทางกลับกัน วิศวกรซอฟต์แวร์เป็นผู้เชี่ยวชาญด้านการเขียนโปรแกรม/โปรแกรมเมอร์ที่เขียนโปรแกรมที่ปรับขนาดได้และออกแบบระบบซอฟต์แวร์สำหรับบริษัทต่างๆ สำหรับพวกเขา แนวคิดทั้งหมดของ ML ดูเหมือนห่างไกล โมเดลที่สร้างขึ้นโดย Data Scientists นั้นส่วนใหญ่เข้าใจยากสำหรับวิศวกรซอฟต์แวร์ – พวกมันซับซ้อน ไม่แสดงรูปแบบการออกแบบที่ชัดเจน และไม่สะอาด (ทุกอย่างขัดกับสิ่งที่วิศวกรซอฟต์แวร์เรียนรู้!)
นี่คือเหตุผลที่บริษัทต่างๆ รู้สึกว่าต้องการ Machine Learning Engineer ซึ่งเป็นมืออาชีพที่สามารถนำสิ่งที่ดีที่สุดของทั้งสองโลกมารวมกัน องค์กรต้องการใครสักคนที่สามารถไขรหัสของ Data Scientists ให้กระจ่าง และทำให้มีประโยชน์และเข้าถึงได้มากขึ้น วิศวกรแมชชีนเลิร์นนิ่งรวมกฎหมายและกฎเกณฑ์ของโลก Data Science เข้ากับการเขียนโปรแกรม เพื่อช่วยให้องค์กรได้รับประโยชน์อย่างเต็มที่จากเทคโนโลยี AI/ML ในขณะที่ปฏิบัติตามแนวทางปฏิบัติและโปรโตคอลในการเขียนโปรแกรมมาตรฐาน
วิศวกรแมชชีนเลิร์นนิงทำอะไรได้บ้าง
งานของ Machine Learning Engineer ค่อนข้างคล้ายกับงานของ Data Scientist ในแง่ที่ว่าทั้งสองบทบาทเกี่ยวข้องกับการทำงานกับข้อมูลปริมาณมหาศาล ดังนั้นทั้งวิศวกรการเรียนรู้ของเครื่องและนักวิทยาศาสตร์ข้อมูลจึงต้องมีทักษะการจัดการข้อมูลที่ยอดเยี่ยม อย่างไรก็ตาม นั่นคือความคล้ายคลึงกันทั้งหมดที่บทบาททั้งสองนี้มีร่วมกัน
นักวิทยาศาสตร์ข้อมูลให้ความสำคัญกับการสร้างข้อมูลเชิงลึกอันมีค่าเพื่อขับเคลื่อนการเติบโตของธุรกิจผ่านการตัดสินใจที่เน้นข้อมูลเป็นหลัก ในทางตรงกันข้าม Machine Learning Engineers มุ่งเน้นไปที่การออกแบบซอฟต์แวร์ที่ทำงานด้วยตนเองสำหรับระบบอัตโนมัติของแบบจำลองเชิงคาดการณ์
ในแบบจำลองดังกล่าว ทุกครั้งที่ซอฟต์แวร์ทำงาน ซอฟต์แวร์จะใช้ผลลัพธ์ของการดำเนินการนั้นเพื่อดำเนินการในอนาคตด้วยความแม่นยำที่มากขึ้น สิ่งนี้ประกอบขึ้นเป็นกระบวนการ "เรียนรู้" ของซอฟต์แวร์ เครื่องมือแนะนำ Netflix และ Amazon เป็นตัวอย่างที่ดีที่สุดของซอฟต์แวร์อัจฉริยะประเภทนี้
โดยปกติ วิศวกรแมชชีนเลิร์นนิงจะทำงานร่วมกันอย่างใกล้ชิดกับนักวิทยาศาสตร์ข้อมูล ในขณะที่ Data Scientists ดึงข้อมูลเชิงลึกที่มีความหมายจากชุดข้อมูลขนาดใหญ่และสื่อสารข้อมูลไปยังผู้มีส่วนได้ส่วนเสียทางธุรกิจ วิศวกรการเรียนรู้ของเครื่องจะตรวจสอบให้แน่ใจว่าแบบจำลองที่นักวิทยาศาสตร์ข้อมูลใช้สามารถนำเข้าข้อมูลแบบเรียลไทม์จำนวนมหาศาลเพื่อสร้างผลลัพธ์ที่แม่นยำยิ่งขึ้น
ความรับผิดชอบของวิศวกรการเรียนรู้ของเครื่อง
- เพื่อศึกษาและแปลงต้นแบบวิทยาศาสตร์ข้อมูล
- เพื่อออกแบบและพัฒนาระบบและโครงร่างการเรียนรู้ของเครื่อง
- เพื่อทำการวิเคราะห์ทางสถิติและปรับแต่งแบบจำลองโดยใช้ผลการทดสอบ
- เพื่อค้นหาชุดข้อมูลที่มีทางออนไลน์เพื่อวัตถุประสงค์ในการฝึกอบรม
- เพื่อฝึกอบรมและฝึกอบรมระบบและแบบจำลอง ML อีกครั้งเมื่อจำเป็น
- เพื่อขยายและเพิ่มกรอบงานและไลบรารี ML ที่มีอยู่
- เพื่อพัฒนาแอพ Machine Learning ตามความต้องการของลูกค้า/ลูกค้า
- เพื่อทำการวิจัย ทดลอง และใช้อัลกอริธึมและเครื่องมือ ML ที่เหมาะสม
- เพื่อวิเคราะห์ความสามารถในการแก้ปัญหาและกรณีการใช้งานของอัลกอริธึม ML และจัดอันดับตามความน่าจะเป็นที่ประสบความสำเร็จ
- เพื่อสำรวจและแสดงภาพข้อมูลเพื่อความเข้าใจที่ดีขึ้นและระบุความแตกต่างในการกระจายข้อมูลที่อาจส่งผลกระทบต่อประสิทธิภาพของแบบจำลองเมื่อปรับใช้ในสถานการณ์จริง
ทักษะที่จำเป็นในการเป็นวิศวกรการเรียนรู้ของเครื่อง
- ระดับสูงในวิทยาการคอมพิวเตอร์/คณิตศาสตร์/สถิติหรือสาขาที่เกี่ยวข้อง
- ทักษะทางคณิตศาสตร์และสถิติขั้นสูง (พีชคณิตเชิงเส้น แคลคูลัส สถิติเบย์ ค่าเฉลี่ย ค่ามัธยฐาน ความแปรปรวน ฯลฯ)
- ทักษะการสร้างแบบจำลองข้อมูลและสถาปัตยกรรมข้อมูลที่แข็งแกร่ง
- มีประสบการณ์การเขียนโปรแกรมในภาษา Python, R, Java, C++ เป็นต้น
- ความรู้เกี่ยวกับกรอบงาน Big Data เช่น Hadoop, Spark, Pig, Hive, Flume เป็นต้น
- มีประสบการณ์ในการทำงานกับเฟรมเวิร์ก ML เช่น TensorFlow และ Keras
- มีประสบการณ์ในการทำงานกับไลบรารีและแพ็คเกจ ML ต่างๆ เช่น Scikit learn, Theano, Tensorflow, Matplotlib, Caffe เป็นต้น
- สื่อสารเป็นลายลักษณ์อักษรและด้วยวาจาที่แข็งแกร่ง
- ทักษะด้านมนุษยสัมพันธ์และการทำงานร่วมกันที่ดีเยี่ยม
เงินเดือนวิศวกรการเรียนรู้ของเครื่อง
จากรายงานของ Indeed ปี 2019 – งานที่ดีที่สุดในสหรัฐอเมริกาและอินเดีย – Machine Learning Engineer ครองตำแหน่งผู้นำในรายการด้วยเงินเดือนเฉลี่ย $146,085 สิ่งที่น่าสนใจกว่าคือบทบาทของวิศวกร ML บันทึกการเพิ่มขึ้นอย่างมาก 344% ตั้งแต่ปี 2015!

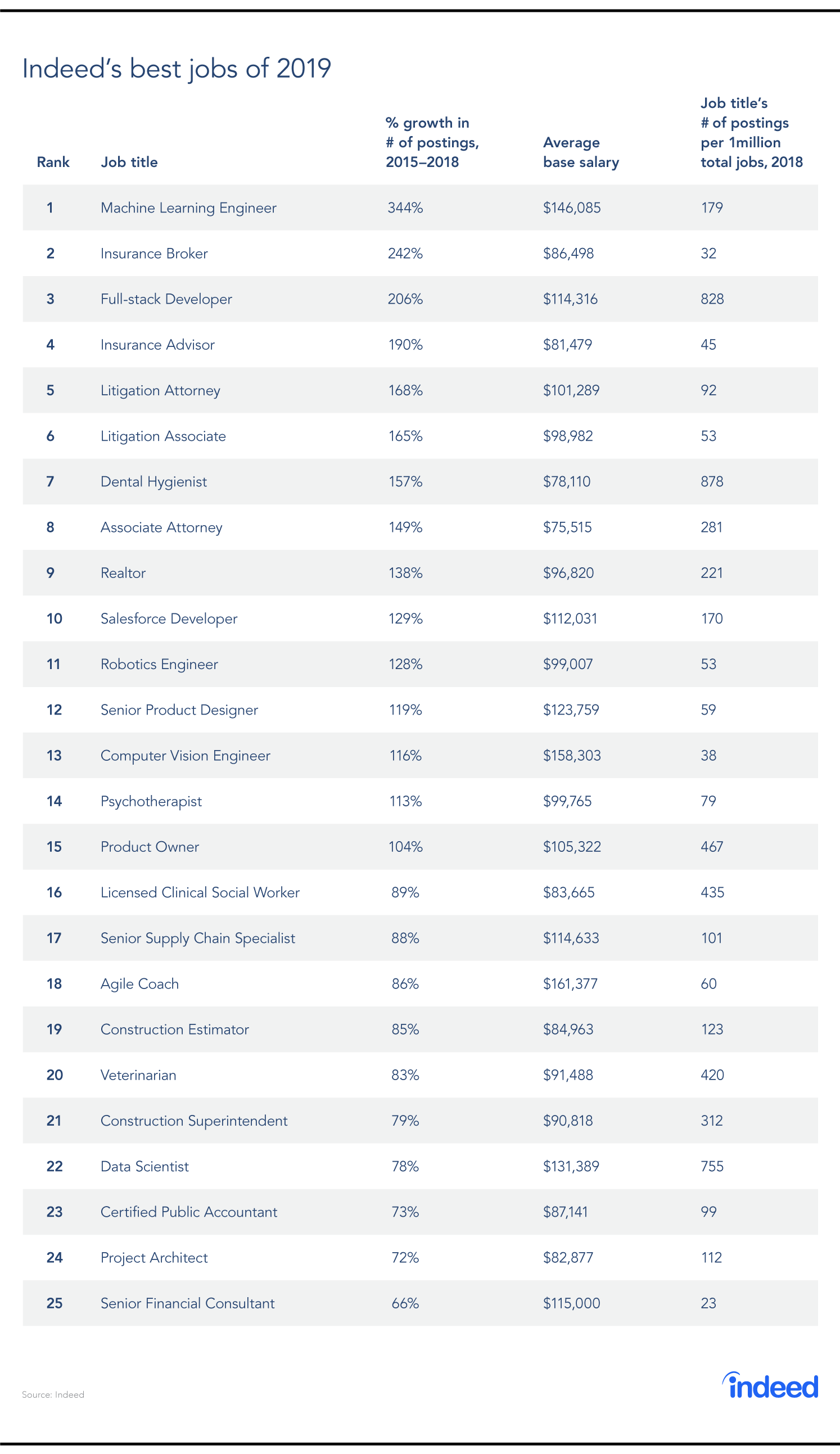
แหล่งที่มา
Glassdoor ยืนยันว่า เงินเดือนประจำปีเฉลี่ยของวิศวกรการเรียนรู้ของเครื่อง ในอินเดียอยู่ที่ Rs. 7,95,677. แม้ว่าเงินเดือนของวิศวกรแมชชีนเลิร์นนิงจะสูงกว่าค่าเฉลี่ยของประเทศ เช่นเดียวกับงานอื่น ๆ มันขึ้นอยู่กับขนาดและชื่อเสียงของบริษัท ที่ตั้ง ชุดทักษะ วุฒิการศึกษา และประสบการณ์ทางวิชาชีพของหลักสูตร
นี่คือ แผนภูมิเงินเดือนของ ML Engineers ในบริษัทชั้นนำในอุตสาหกรรมบางแห่ง:
- ไมโครซอฟต์ – อาร์เอส 14,62,000 – 22,44,000 LPA
- Accenture – อาร์เอส 10,11,000 – 15,28,000 LPA
- Quantiphi – อาร์เอส 8,50,481 LPA
- บริการที่ปรึกษาทาทา – Rs. 4,12,706 LPA
- อินโฟซิส – อาร์เอส 3,77,000 – 6,69,000 LPA
อ่านเพิ่มเติมเกี่ยวกับเงินเดือนการเรียนรู้ของเครื่องในอินเดีย
ทำไมความต้องการ Machine Learning Engineer จึงเพิ่มขึ้น?
ในทศวรรษที่ผ่านมา ความต้องการวิศวกรแมชชีนเลิร์นนิงเกินความจำเป็นของนักวิทยาศาสตร์ข้อมูล ในรายงานงาน LinkedIn US Job ปี 2017 วิศวกรแมชชีนเลิร์นนิ่งได้รับการจัดอันดับสูงสุดโดยมีอัตราการเติบโต 9.8 เท่าในห้าปี (2012-17)
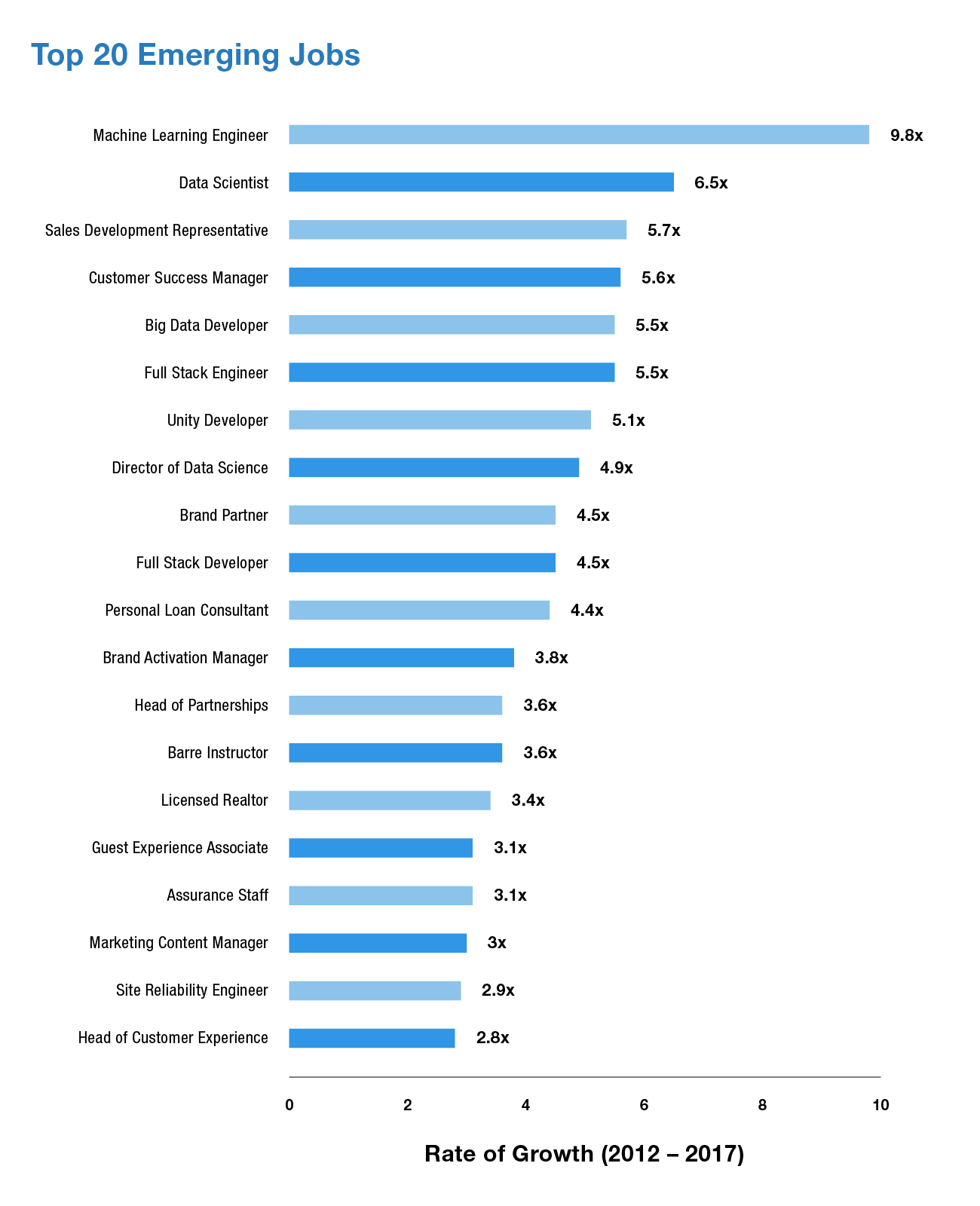
แหล่งที่มา
สำหรับตลาดแมชชีน เลิร์นนิงทั่วโลก คาดการณ์ว่าจะเกิน 39,986.7 ล้านดอลลาร์ภายในปี 2568 ซึ่งเติบโตที่ CAGR ที่ 49.7% ระหว่างปี 2560 ถึง 2568 สถิติเหล่านี้แสดงให้เห็นชัดเจนว่าตลาด ML กำลังขยายตัวอย่างรวดเร็วอย่างที่ไม่เคยมีมาก่อน ในแง่ของการแข่งขันที่เพิ่มขึ้น บริษัทต่างๆ จะต้องจ้างวิศวกร ML ที่มีความสามารถร่วมกับผู้เชี่ยวชาญด้าน Data Science คนอื่นๆ เพื่อให้มีพื้นฐานที่มั่นคงในตลาด
ด้วยการเรียนรู้ด้วยเครื่องอย่างรวดเร็วในอุตสาหกรรมสมัยใหม่ แอปพลิเคชันและกรณีการใช้งานจึงมีความหลากหลายเช่นเดียวกับ Big Data
ธุรกิจและองค์กรต่างใช้ประโยชน์จาก ML สำหรับการตรวจจับสแปมและการตรวจจับการฉ้อโกง สำหรับระบบจดจำภาพและคำพูด เพื่อสร้างผู้ช่วยส่วนตัวอัจฉริยะ (Siri, Alexa) และรถยนต์อิสระ เพื่อเปิดใช้งานบ้านอัจฉริยะและพลังงาน IoT; เพื่อสร้างการคาดการณ์ปริมาณการใช้ข้อมูลที่ถูกต้อง เพื่อปรับแต่งบริการโซเชียลมีเดียและบริการช็อปปิ้ง/ดูสินค้าออนไลน์ เพื่อปรับแต่งผลลัพธ์ของเครื่องมือค้นหา และอื่นๆ อีกมากมาย
บทสรุป
เร็วๆ นี้จะมีการค้นพบครั้งใหม่ที่น่าประหลาดใจเช่นนี้ซึ่งเป็นผู้บุกเบิกโดย Machine Learning และวิศวกรของ Machine Learning จะยังคงเป็นส่วนสำคัญของการดำเนินงาน ML ดังกล่าวทั้งหมด
คุณสามารถตรวจสอบ PG Diploma in Machine Learning และ AI ซึ่ง มีการฝึกอบรมเชิงปฏิบัติการเชิงปฏิบัติ ผู้ให้คำปรึกษาในอุตสาหกรรมแบบตัวต่อตัว กรณีศึกษาและการมอบหมายงาน 12 กรณี สถานะศิษย์เก่า IIIT-B และอื่นๆ
อนาคตของแมชชีนเลิร์นนิงคืออะไร?
การเรียนรู้ของเครื่องกำลังค่อยๆ เข้าสู่ทุกภาคส่วนของสังคม ตั้งแต่วัตถุที่จดจำเสียงไปจนถึงอุปกรณ์อัจฉริยะ สิ่งประดิษฐ์ใหม่ทั้งหมดนี้ใช้ประโยชน์จากการเรียนรู้ของเครื่อง ทุกวันนี้แมชชีนเลิร์นนิงถูกใช้ในภาคการธนาคาร ภาคความบันเทิงและสื่อ ภาคการลงทุน และภาคอื่นๆ อีกมากมาย มีอีกหลายภาคส่วนที่ยังไม่ได้ถูกแตะต้องโดยแมชชีนเลิร์นนิง แต่ผู้เชี่ยวชาญด้านแมชชีนเลิร์นนิงกำลังทำการค้นคว้าอย่างช้าๆ เพื่อเข้าถึงภาคส่วนเหล่านี้ ผู้เชี่ยวชาญด้านแมชชีนเลิร์นนิงมีความต้องการสูง เนื่องจากบริษัทสตาร์ทอัพด้านเทคโนโลยีเกือบทุกแห่งและองค์กรรายใหญ่ต้องการจ้างพวกเขาให้มาช่วยปรับให้เข้ากับบริษัทของตน
อะไรคือความสัมพันธ์ระหว่างปัญญาประดิษฐ์และการเรียนรู้ของเครื่อง?
Machine Learning คือการศึกษาระบบที่สามารถเรียนรู้จากประสบการณ์ในอดีต เช่น ข้อมูล เมื่อเราพูดถึงแมชชีนเลิร์นนิง เรามักจะอ้างถึงการสร้างแบบจำลองเชิงคาดการณ์ ซึ่งเป็นฟิลด์ย่อยของแมชชีนเลิร์นนิง เกี่ยวข้องกับการสร้างแบบจำลองจากข้อมูลเพื่อคาดการณ์ตามข้อมูลใหม่ ปัญญาประดิษฐ์เป็นหน่วยของวิทยาการคอมพิวเตอร์ที่เน้นการพัฒนาคอมพิวเตอร์อัจฉริยะที่มีสติปัญญาเหมือนมนุษย์ รวมถึงความสามารถที่หลากหลาย เช่น การเรียนรู้ การจดจำ และการกำหนดเป้าหมาย ปัญญาประดิษฐ์มีสาขาย่อยที่เรียกว่าการเรียนรู้ของเครื่อง
กรณีการใช้งานจริงของการเรียนรู้ของเครื่องมีอะไรบ้าง
แมชชีนเลิร์นนิงมีการใช้งานที่หลากหลาย ตั้งแต่ธุรกิจไปจนถึงวิทยาศาสตร์และการแพทย์ ใช้ในทางการแพทย์เพื่อค้นหาฐานข้อมูลทางเคมีขนาดใหญ่ และพิจารณาว่าสารประกอบคล้ายยาชนิดใดมีแนวโน้มที่จะจับกับโปรตีนตัวรับจำเพาะมากที่สุด ใช้ในการค้นหาเว็บและคำแนะนำเพื่อจดจำและค้นหาข้อมูล ค้นหาการค้นหาที่เกี่ยวข้อง คาดการณ์ผลลัพธ์ที่เกี่ยวข้องกับเรามากที่สุด และส่งคืนผลลัพธ์ที่มีการจัดอันดับ ใช้ในธนาคารและการเงินเพื่อพิจารณาว่าผู้สมัครมีสิทธิ์หรือไม่ ระบุการฉ้อโกงบัตรเครดิต และค้นหาแนวโน้มตลาดหุ้นที่อาจเกิดขึ้น นอกจากนี้ แมชชีนเลิร์นนิงยังใช้ในด้านต่างๆ เช่น การรู้จำข้อความและคำพูด ตลอดจนในอวกาศ ดาราศาสตร์ วิทยาการหุ่นยนต์ โซเชียลเน็ตเวิร์ก และการโฆษณา