
Понимание заголовка Vary
Опубликовано: 2022-03-10HTTP-заголовок Vary отправляется в миллиардах HTTP-ответов каждый день. Но его использование никогда не соответствовало его первоначальному замыслу, и многие разработчики неправильно понимают, что он делает, или даже не осознают, что их веб-сервер отправляет его. С появлением подсказок для клиентов, вариантов и ключевых спецификаций различные ответы получают новый старт.
Что Вари?
История Vary начинается с прекрасной идеи о том, как должна работать сеть. В принципе, URL-адрес представляет собой не веб-страницу, а концептуальный ресурс, например выписку по счету. Представьте, что вы хотите увидеть свою банковскую выписку: вы заходите на bank.com и отправляете запрос GET для /statement . Пока все хорошо, но вы не сказали, в каком формате вы хотите получить выражение. Вот почему ваш браузер также будет включать что-то вроде Accept: text/html в ваш запрос. Теоретически, по крайней мере, это означает, что вместо этого вы можете сказать Accept: text/csv и получить тот же ресурс в другом формате.

Поскольку один и тот же URL-адрес теперь создает разные ответы в зависимости от значения заголовка Accept , любой кеш, в котором хранится этот ответ, должен знать, что этот заголовок важен. Сервер сообщает нам, что заголовок Accept важен следующим образом:
Vary: Accept Вы можете прочитать это как «Этот ответ зависит от значения заголовка Accept вашего запроса».
Это в основном не работает в сегодняшней сети. Так называемые «согласования контента» были отличной идеей, но провалились. Однако это не означает, что Vary бесполезен. Приличная часть страниц, которые вы посещаете в Интернете, содержат заголовок Vary в ответе — возможно, они есть и на ваших веб-сайтах, но вы об этом не знаете. Итак, если заголовок не работает для согласования контента, почему он до сих пор так популярен и как браузеры с этим справляются? Давайте взглянем.
Ранее я писал о Vary в связи с сетями доставки контента (CDN), теми промежуточными кэшами (такими как Fastly, CloudFront и Akamai), которые вы можете поместить между своими серверами и пользователем. Браузеры также должны понимать и реагировать на правила Vary, и то, как они это делают, отличается от того, как Vary обрабатывается CDN. В этом посте я исследую темный мир вариаций кеша в браузере.
Сегодняшние варианты использования для изменения в браузере
Как мы видели ранее, традиционное использование Vary заключается в выполнении согласования контента с использованием заголовков Accept , Accept-Language и Accept-Encoding , и исторически первые два из них с треском провалились. Изменение Accept-Encoding для доставки ответов, сжатых Gzip или Brotli, где это поддерживается, в основном работает достаточно хорошо, но в наши дни все браузеры поддерживают Gzip, так что это не очень интересно.
Как насчет некоторых из этих сценариев?
- Мы хотим показывать изображения, которые точно соответствуют ширине экрана пользователя. Если пользователь изменит размер своего браузера, мы загрузим новые изображения (в зависимости от подсказок клиента).
- Если пользователь выходит из системы, мы хотим избежать использования каких-либо страниц, которые были кэшированы во время входа в систему (с использованием файла cookie в качестве
Key). - Пользователи браузеров, поддерживающих формат изображений WebP, должны получать изображения WebP; в противном случае они должны получить JPEG.
- При использовании браузера на экране с высокой плотностью пользователь должен получать 2-кратные изображения. Если они переместят окно браузера на экран стандартной плотности и обновятся, они должны получить 1x изображения.
Кэши полностью вниз
В отличие от пограничных кешей, которые действуют как один гигантский кеш, совместно используемый всеми пользователями, браузер предназначен только для одного пользователя, но у него есть много разных кешей для разных, конкретных целей:
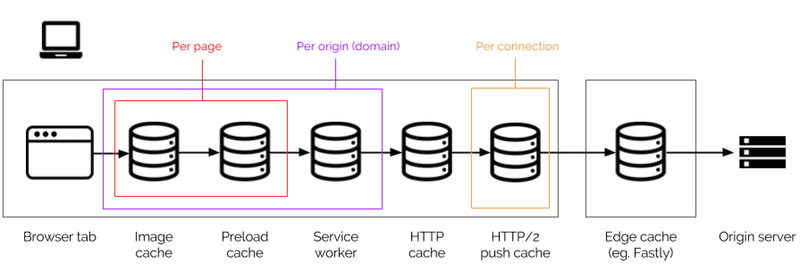
Некоторые из них являются совершенно новыми, и точное понимание того, из какого кеша загружается контент, представляет собой сложный расчет, который плохо поддерживается инструментами разработчика. Вот что делают эти кеши:
- кэш изображений
Это кеш на уровне страницы, в котором хранятся данные декодированного изображения, так что, например, если вы включаете одно и то же изображение на страницу несколько раз, браузеру нужно загрузить и декодировать его только один раз. - предварительная загрузка кеша
Это также относится к странице и сохраняет все, что было предварительно загружено в заголовкеLinkили<link rel="preload">, даже если ресурс обычно не кэшируется. Как и кеш изображений, кеш предварительной загрузки уничтожается, когда пользователь уходит со страницы. - API кеша сервисного работника
Это обеспечивает серверную часть кэша с программируемым интерфейсом; поэтому здесь ничего не хранится, если вы специально не поместите это туда с помощью кода JavaScript в сервис-воркере. Это также будет проверено, только если вы явно сделаете это в обработчикеfetchсервисного работника. Кэш сервис-воркера ограничен исходной областью, и хотя его постоянство не гарантируется, он более устойчив, чем HTTP-кэш браузера. - HTTP-кэш
Это основной кеш, с которым люди больше всего знакомы. Это единственный кеш, который обращает внимание на заголовки кеша уровня HTTP, такие какCache-Control, и объединяет их с собственными эвристическими правилами браузера, чтобы определить, нужно ли что-то кэшировать и как долго. Он имеет самый широкий охват и используется всеми веб-сайтами; поэтому, если два несвязанных веб-сайта загружают один и тот же ресурс (например, Google Analytics), они могут иметь одно и то же попадание в кеш. - Кэш HTTP/2 push (или «кэш H2 push»)
Он связан с соединением и хранит объекты, которые были отправлены с сервера, но еще не были запрошены какой-либо страницей, использующей соединение. Он привязан к страницам, использующим конкретное соединение, что по сути то же самое, что и область одного источника, но также уничтожается при закрытии соединения.
Из них лучше всего определены HTTP-кеш и кэш сервис-воркеров. Что касается кешей изображений и предварительной загрузки, некоторые браузеры могут реализовать их как единый «кеш памяти», привязанный к рендерингу конкретной навигации, но мысленная модель, которую я здесь описываю, по-прежнему является правильным способом осмысления этого процесса. См. примечание к спецификации по preload , если вам интересно. В случае пуш-сервера H2 обсуждение судьбы этого кеша остается активным.
Порядок, в котором запрос проверяет эти кеши, прежде чем выйти в сеть, важен, потому что запрос чего-то может перетащить это из внешнего уровня кэширования во внутренний. Например, если ваш сервер HTTP/2 отправляет таблицу стилей вместе со страницей, которая в ней нуждается, и эта страница также предварительно загружает таблицу стилей с помощью <link rel="preload"> , тогда таблица стилей в конечном итоге будет касаться трех кеши в браузере. Во-первых, он будет находиться в push-кэше H2, ожидая запроса. Когда браузер отображает страницу и доходит до тега preload , он извлекает таблицу стилей из push-кэша через HTTP-кэш (который может хранить ее, в зависимости от заголовка Cache-Control таблицы стилей) и сохраняет это в кеше предварительной загрузки.
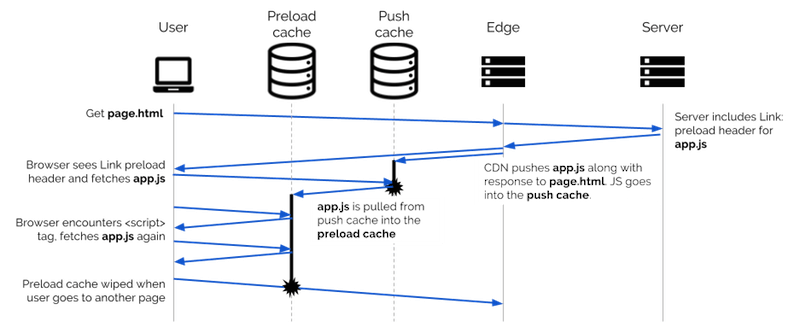
Представляем Vary в качестве валидатора
Итак, что произойдет, если мы возьмем эту ситуацию и добавим к ней Вэри?
В отличие от промежуточных кешей (таких как CDN), браузеры обычно не реализуют возможность хранения нескольких вариантов URL-адреса . Причина этого в том, что вещи, для которых мы обычно используем Vary (в основном Accept-Encoding и Accept-Language ), не меняются часто в контексте одного пользователя. Accept-Encoding может измениться (но, вероятно, не изменится) при обновлении браузера, а Accept-Language , скорее всего, изменится только в том случае, если вы отредактируете языковые настройки вашей операционной системы. Также оказалось, что таким образом намного проще реализовать Vary, хотя некоторые авторы спецификаций считают, что это было ошибкой.
Для браузера в большинстве случаев не будет большой потерей хранить только один вариант, но важно, чтобы мы случайно не использовали вариант, который больше не действителен, если «измененные» данные действительно изменятся.
Компромисс заключается в том, чтобы обращаться с Vary как с валидатором, а не как с ключом. Браузеры вычисляют ключи кеша обычным способом (по сути, используя URL-адрес), а затем, если они засчитывают попадание, они проверяют, удовлетворяет ли запрос всем правилам Vary, запеченным в кэшированном ответе. Если это не так, то браузер рассматривает запрос как промах в кеше и переходит к следующему уровню кеша или выходит в сеть. Когда получен новый ответ, он перезапишет кешированную версию, даже если технически это другой вариант.

Демонстрация разнообразного поведения
Чтобы продемонстрировать, как работает Vary , я сделал небольшой набор тестов. Тест загружает ряд разных URL-адресов, различающихся по разным заголовкам, и определяет, попал ли запрос в кеш или нет. Первоначально я использовал для этого ResourceTiming, но для большей совместимости я в конечном итоге переключился на измерение того, сколько времени занимает выполнение запроса (и намеренно добавил 1-секундную задержку к ответам на стороне сервера, чтобы сделать разницу действительно очевидной).
Давайте посмотрим на каждый из типов кеша и на то, как должен работать Vary и действительно ли он так работает. Для каждого теста я показываю здесь, следует ли ожидать результата от кеша («ПОПАДАНИЕ» или «ПРОМАХ») и что на самом деле произошло.
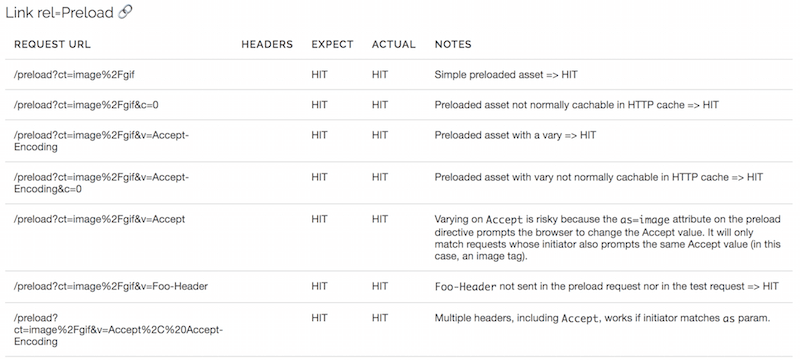
Предварительная загрузка
В настоящее время предварительная загрузка поддерживается только в Chrome, где предварительно загруженные ответы хранятся в кеше памяти до тех пор, пока они не потребуются странице. Ответы также заполняют кеш HTTP на пути к кешу предварительной загрузки, если они поддерживают HTTP-кэширование. Поскольку указание заголовков запроса с предварительной загрузкой невозможно, а кэш предварительной загрузки длится только до тех пор, пока страница, протестировать это сложно, но мы, по крайней мере, можем видеть, что объекты с заголовком Vary успешно предварительно загружаются:
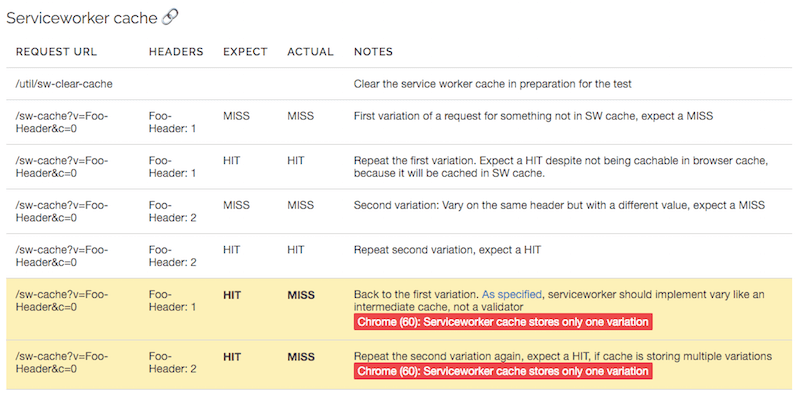
API кэша сервис-воркеров
Chrome и Firefox поддерживают сервис-воркеры, и при разработке спецификации сервис-воркеров авторы хотели исправить то, что они считали неработающими реализациями в браузерах, чтобы Vary в браузере работал больше как CDN. Это означает, что, хотя браузер должен хранить только одну вариацию в кеше HTTP, он должен хранить несколько вариаций в Cache API. Firefox (54) делает это правильно, в то время как Chrome использует ту же логику «вариант-валидатор», что и для кэша HTTP (ошибка отслеживается).
HTTP-кэш
Основной HTTP-кеш должен отслеживать Vary и делает это последовательно (в качестве валидатора) во всех браузерах. Подробнее об этом читайте в статье Марка Ноттингема «Пересмотр состояния кэширования браузера».
Кэш HTTP/2 Push
Vary следует соблюдать, но на практике ни один браузер не соблюдает его, и браузеры будут счастливо сопоставлять и использовать отправленные ответы с запросами, которые содержат случайные значения в заголовках, от которых зависят ответы.

Морщина «304 (не изменено)»
Статус ответа HTTP «304 (не изменен)» завораживает. Наш «уважаемый лидер», Артур Бергман, указал мне на эту жемчужину в спецификации кэширования HTTP (выделено мной):
Сервер, генерирующий ответ 304, должен создать любое из следующих полей заголовка, которые были бы отправлены в ответе 200 (ОК) на тот же запрос:
Cache-Control,Content-Location,Date,ETag,ExpiresиVary.
Почему ответ 304 возвращает заголовок Vary ? Сюжет усложняется, когда вы читаете о том, что вы должны делать при получении ответа 304 , содержащего эти заголовки:
Если для обновления выбран сохраненный ответ, кэш должен \[…] использовать другие поля заголовка, представленные в ответе 304 (не изменено), чтобы заменить все экземпляры соответствующих полей заголовка в сохраненном ответе.
Чего ждать? Итак, если заголовок Vary 304 отличается от заголовка в существующем кэшированном объекте, мы должны обновить кэшированный объект? Но это может означать, что он больше не соответствует сделанному нами запросу!
В этом сценарии, на первый взгляд, 304 одновременно сообщает вам, что вы можете и не можете использовать кешированную версию. Конечно, если бы сервер действительно не хотел, чтобы вы использовали кешированную версию, он отправил бы 200 , а не 304 ; таким образом, кешированную версию определенно следует использовать, но после применения к ней обновлений она может не использоваться снова для будущего запроса, идентичного тому, который фактически заполнил кеш в первую очередь.
(Примечание: в Fastly мы не уважаем эту особенность спецификации. Поэтому, если мы получим 304 с вашего исходного сервера, мы продолжим использовать кэшированный объект без изменений, за исключением сброса TTL.)
Браузеры, кажется, уважают это, но с причудой. Они обновляют не только заголовки ответов, но и заголовки запросов, которые с ними связаны, чтобы гарантировать, что после обновления кэшированный ответ соответствует текущему запросу. Кажется, это имеет смысл. В спецификации это не упоминается, поэтому производители браузеров могут делать все, что им заблагорассудится; к счастью, все браузеры ведут себя одинаково.
Подсказки для клиентов
Функция клиентских подсказок Google — одна из самых важных новых вещей, произошедших с Vary в браузере за долгое время. В отличие от Accept-Encoding и Accept-Language , Client Hints описывают значения, которые могут регулярно меняться по мере того, как пользователь перемещается по вашему веб-сайту, в частности следующие:
-
DPR
Соотношение пикселей устройства, плотность пикселей экрана (может варьироваться, если у пользователя несколько экранов) -
Save-Data
Включил ли пользователь режим сохранения данных -
Viewport-Width
Ширина текущего окна просмотра в пикселях -
Width
Желаемая ширина ресурса в физических пикселях
Эти значения могут изменяться не только для одного пользователя, но и диапазон значений, связанных с шириной, велик. Таким образом, мы можем полностью использовать Vary с этими заголовками, но мы рискуем снизить эффективность нашего кэша или даже сделать кэширование неэффективным.
Предложение ключевого заголовка
Клиентские подсказки и другие очень детализированные заголовки подходят для предложения, над которым работает Марк, под названием Key. Давайте рассмотрим пару примеров:
Key: Viewport-Width;div=50 Это говорит о том, что ответ варьируется в зависимости от значения заголовка запроса Viewport-Width , но округляется до ближайшего числа, кратного 50 пикселям!
Key: cookie;param=sessionAuth;param=flags Добавление этого заголовка в ответ означает, что мы используем два конкретных файла cookie: sessionAuth и flags . Если они не изменились, мы можем повторно использовать этот ответ для будущего запроса.
Итак, основные отличия Key от Vary :
-
Keyпозволяет варьировать подполя в заголовках, что внезапно делает возможным изменение файлов cookie, потому что вы можете изменить только один файл cookie — это было бы огромно; - отдельные значения могут быть объединены в диапазоны , чтобы увеличить вероятность попадания в кеш, что особенно полезно для изменения таких вещей, как ширина области просмотра.
- все варианты с одним и тем же URL должны иметь один и тот же ключ. Таким образом, если кеш получает новый ответ для URL-адреса, для которого у него уже есть некоторые существующие варианты, и значение заголовка
Keyнового ответа не соответствует значениям в этих существующих вариантах, тогда все варианты должны быть удалены из кеша.
На момент написания ни один браузер или CDN не поддерживали Key , хотя в некоторых CDN вы могли бы получить тот же эффект, разделив входящие заголовки на несколько частных заголовков и варьируя их (см. Fastly»), поэтому браузеры являются основной областью, в которой Key может оказать влияние.
Требование, чтобы все варианты имели один и тот же рецепт ключа, несколько ограничивает, и я хотел бы видеть в спецификации какую-то опцию «раннего выхода». Это позволит вам делать такие вещи, как «Изменяться в зависимости от состояния аутентификации, а если вы вошли в систему, также изменяться в зависимости от предпочтений».
Варианты предложения
Key — хороший общий механизм, но некоторые заголовки имеют более сложные правила для своих значений, и понимание семантики этих значений может помочь нам найти автоматизированные способы уменьшения вариаций кэша. Например, представьте, что два запроса приходят с разными значениями Accept-Language , en-gb и en-us , но хотя ваш веб-сайт поддерживает языковые варианты, у вас есть только один «английский». Если мы ответим на запрос на английском языке США, и этот ответ кэшируется в CDN, то его нельзя будет повторно использовать для запроса английского языка в Великобритании, потому что значение Accept-Language будет другим, а кеш недостаточно умен, чтобы знать лучше. .
Введите, с большой помпой, предложение Variants. Это позволило бы серверам описывать, какие варианты они поддерживают, позволяя кэшам принимать более разумные решения о том, какие варианты на самом деле отличаются, а какие фактически одинаковы.
На данный момент Variants — это очень ранний проект, и, поскольку он предназначен для помощи с Accept-Encoding и Accept-Language , его полезность скорее ограничена общими кэшами, такими как CDN, а не кэшами браузера. Но он прекрасно сочетается с Key и дополняет картину для лучшего контроля за изменениями кеша.
Заключение
Здесь многое можно понять, и хотя может быть интересно понять, как работает браузер внутри, есть также несколько простых вещей, которые вы можете извлечь из него:
- Большинство браузеров рассматривают
Varyкак валидатор. Если вы хотите кэшировать несколько отдельных вариантов, найдите способ вместо этого использовать разные URL-адреса. - Браузеры игнорируют
Varyдля ресурсов, отправляемых с помощью HTTP/2-сервера, поэтому не меняйте ничего, что вы отправляете. - В браузерах масса кешей, и работают они по-разному. Стоит попытаться понять, как ваши решения о кэшировании влияют на производительность в каждом из них, особенно в контексте
Vary. -
Varyне так полезен, как мог бы быть, иKeyв паре с Client Hints начинает это менять. Следите за поддержкой браузера, чтобы узнать, когда вы сможете начать их использовать.
Идите вперед и будьте изменчивы.