
Creazione di applicazioni front-end serverless utilizzando Google Cloud Platform
Pubblicato: 2022-03-10Di recente, il paradigma di sviluppo delle applicazioni ha iniziato a passare dalla necessità di distribuire, ridimensionare e aggiornare manualmente le risorse utilizzate all'interno di un'applicazione all'affidarsi a fornitori di servizi cloud di terze parti per eseguire la maggior parte della gestione di queste risorse.
In qualità di sviluppatore o organizzazione che desidera creare un'applicazione adatta al mercato nel più breve tempo possibile, il tuo obiettivo principale potrebbe essere quello di fornire il servizio applicativo principale ai tuoi utenti mentre dedichi meno tempo alla configurazione, all'implementazione e allo stress test la tua applicazione. Se questo è il tuo caso d'uso, gestire la logica aziendale della tua applicazione in modo serverless potrebbe essere l'opzione migliore. Ma come?
Questo articolo è utile per gli ingegneri front-end che desiderano creare determinate funzionalità all'interno della propria applicazione o per i tecnici back-end che desiderano estrarre e gestire una determinata funzionalità da un servizio back-end esistente utilizzando un'applicazione serverless distribuita su Google Cloud Platform.
Nota : per beneficiare di ciò che verrà trattato qui, devi avere esperienza di lavoro con React. Non è richiesta alcuna esperienza precedente in applicazioni serverless.
Prima di iniziare, cerchiamo di capire cosa sono realmente le applicazioni serverless e come l'architettura serverless può essere utilizzata durante la creazione di un'applicazione nel contesto di un ingegnere front-end.
Applicazioni senza server
Le applicazioni serverless sono applicazioni suddivise in minuscole funzioni riutilizzabili basate su eventi, ospitate e gestite da provider di servizi cloud di terze parti all'interno del cloud pubblico per conto dell'autore dell'applicazione. Questi sono attivati da determinati eventi e vengono eseguiti su richiesta. Sebbene il suffisso " less " allegato alla parola serverless indichi l'assenza di un server, non è così al 100%. Queste applicazioni vengono ancora eseguite su server e altre risorse hardware, ma in questo caso tali risorse non vengono fornite dallo sviluppatore ma piuttosto da un provider di servizi cloud di terze parti. Quindi sono serverless per l'autore dell'applicazione, ma funzionano ancora su server e sono accessibili tramite Internet pubblico.
Un esempio d'uso di un'applicazione serverless sarebbe l'invio di e-mail a potenziali utenti che visitano la tua pagina di destinazione e si iscrivono alla ricezione di e-mail di lancio del prodotto. In questa fase, probabilmente non hai un servizio di back-end in esecuzione e non vorresti sacrificare il tempo e le risorse necessarie per crearne, distribuirlo e gestirlo, tutto perché devi inviare e-mail. Qui puoi scrivere un singolo file che utilizza un client di posta elettronica e distribuirlo a qualsiasi provider cloud che supporta l'applicazione serverless e consentire loro di gestire questa applicazione per tuo conto mentre colleghi questa applicazione serverless alla tua pagina di destinazione.
Sebbene ci siano un sacco di ragioni per cui potresti prendere in considerazione l'utilizzo di applicazioni serverless o Functions As A Service (FAAS) come vengono chiamate, per la tua applicazione front-end, ecco alcuni motivi molto importanti che dovresti considerare:
- Ridimensionamento automatico dell'applicazione
Le applicazioni serverless sono ridimensionate orizzontalmente e questo " scalabilità orizzontale" viene eseguito automaticamente dal provider cloud in base alla quantità di chiamate, quindi lo sviluppatore non deve aggiungere o rimuovere manualmente risorse quando l'applicazione è sottoposta a un carico pesante. - Efficacia dei costi
Essendo basate su eventi, le applicazioni serverless vengono eseguite solo quando necessario e ciò si riflette sugli addebiti poiché vengono fatturati in base al numero di volte invocato. - Flessibilità
Le applicazioni serverless sono progettate per essere altamente riutilizzabili e ciò significa che non sono vincolate a un singolo progetto o applicazione. Una particolare funzionalità può essere estratta in un'applicazione serverless, distribuita e utilizzata in più progetti o applicazioni. Le applicazioni serverless possono anche essere scritte nella lingua preferita dell'autore dell'applicazione, sebbene alcuni provider di servizi cloud supportino solo un numero inferiore di lingue.
Quando si utilizzano applicazioni serverless, ogni sviluppatore ha una vasta gamma di provider cloud all'interno del cloud pubblico da utilizzare. Nel contesto di questo articolo ci concentreremo sulle applicazioni serverless su Google Cloud Platform, su come vengono create, gestite, distribuite e su come si integrano anche con altri prodotti su Google Cloud. Per fare ciò, aggiungeremo nuove funzionalità a questa applicazione React esistente mentre lavoriamo attraverso il processo di:
- Archiviazione e recupero dei dati dell'utente sul cloud;
- Creazione e gestione di cron job su Google Cloud;
- Distribuzione di funzioni cloud su Google Cloud.
Nota : le applicazioni serverless non sono vincolate solo a React, purché il framework o la libreria front-end preferita possa effettuare una richiesta HTTP , può utilizzare un'applicazione serverless.
Funzioni Google Cloud
Google Cloud consente agli sviluppatori di creare applicazioni serverless utilizzando Cloud Functions e di eseguirle utilizzando Functions Framework. Come vengono chiamate, le funzioni cloud sono funzioni guidate da eventi riutilizzabili distribuite su Google Cloud per ascoltare un trigger specifico tra i sei trigger di eventi disponibili e quindi eseguire l'operazione per cui è stato scritto.
Le funzioni cloud di breve durata ( con un timeout di esecuzione predefinito di 60 secondi e un massimo di 9 minuti ) possono essere scritte utilizzando JavaScript, Python, Golang e Java ed eseguite utilizzando il loro runtime. In JavaScript, possono essere eseguiti utilizzando solo alcune versioni disponibili del runtime Node e sono scritti sotto forma di moduli CommonJS utilizzando JavaScript semplice poiché vengono esportati come funzione principale da eseguire su Google Cloud.
Un esempio di una funzione cloud è quello sotto che è un boilerplate vuoto per la funzione per gestire i dati di un utente.
// index.js exports.firestoreFunction = function (req, res) { return res.status(200).send({ data: `Hello ${req.query.name}` }); } Sopra abbiamo un modulo che esporta una funzione. Quando viene eseguito, riceve gli argomenti di richiesta e risposta simili a un percorso HTTP .
Nota : una funzione cloud corrisponde a ogni protocollo HTTP quando viene effettuata una richiesta. Vale la pena notare quando si aspettano dati nell'argomento della richiesta poiché i dati allegati quando si effettua una richiesta per eseguire una funzione cloud sarebbero presenti nel corpo della richiesta per le richieste POST mentre nel corpo della query per le richieste GET .
Le funzioni cloud possono essere eseguite localmente durante lo sviluppo installando il pacchetto @google-cloud/functions-framework all'interno della stessa cartella in cui si trova la funzione scritta o eseguendo un'installazione globale per utilizzarla per più funzioni eseguendo npm i -g @google-cloud/functions-framework dalla riga di comando. Una volta installato, dovrebbe essere aggiunto allo script package.json con il nome del modulo esportato simile a quello seguente:
"scripts": { "start": "functions-framework --target=firestoreFunction --port=8000", } Sopra abbiamo un singolo comando all'interno dei nostri script nel file package.json che esegue il functions-framework e specifica anche firestoreFunction come funzione di destinazione da eseguire localmente sulla porta 8000 .
Possiamo testare l'endpoint di questa funzione effettuando una richiesta GET alla porta 8000 su localhost usando curl. Incollare il comando seguente in un terminale lo farà e restituirà una risposta.
curl https://localhost:8000?name="Smashing Magazine Author" Il comando precedente effettua una richiesta con un metodo GET HTTP e risponde con un codice di stato 200 e un dato oggetto contenente il nome aggiunto nella query.
Distribuzione di una funzione cloud
Tra i metodi di distribuzione disponibili, un modo rapido per distribuire una funzione cloud da una macchina locale consiste nell'usare il cloud Sdk dopo averlo installato. L'esecuzione del comando seguente dal terminale dopo aver autenticato gcloud sdk con il tuo progetto su Google Cloud, distribuirebbe una funzione creata localmente al servizio Cloud Function.
gcloud functions deploy "demo-function" --runtime nodejs10 --trigger-http --entry-point=demo --timeout=60 --set-env-vars=[name="Developer"] --allow-unauthenticatedUsando i flag spiegati di seguito, il comando sopra distribuisce una funzione attivata da HTTP sul cloud di Google con il nome " funzione demo ".
- NOME
Questo è il nome assegnato a una funzione cloud durante la distribuzione ed è obbligatorio. -
region
Questa è la regione in cui deve essere distribuita la funzione cloud. Per impostazione predefinita, viene distribuito inus-central1. -
trigger-http
Questo seleziona HTTP come tipo di trigger della funzione. -
allow-unauthenticated
Ciò consente di richiamare la funzione al di fuori di Google Cloud tramite Internet utilizzando il relativo endpoint generato senza verificare se il chiamante è autenticato. -
source
Percorso locale dal terminale al file che contiene la funzione da distribuire. -
entry-point
Questo è il modulo esportato specifico da distribuire dal file in cui sono state scritte le funzioni. -
runtime
Questo è il runtime della lingua da utilizzare per la funzione in questo elenco di runtime accettati. -
timeout
Questo è il tempo massimo in cui una funzione può essere eseguita prima del timeout. È di 60 secondi per impostazione predefinita e può essere impostato su un massimo di 9 minuti.
Nota : fare in modo che una funzione consenta richieste non autenticate significa che chiunque abbia l'endpoint della tua funzione può anche effettuare richieste senza che tu lo conceda. Per mitigare ciò, possiamo assicurarci che l'endpoint rimanga privato utilizzandolo tramite variabili di ambiente o richiedendo intestazioni di autorizzazione su ogni richiesta.
Ora che la nostra funzione demo è stata implementata e abbiamo l'endpoint, possiamo testare questa funzione come se fosse utilizzata in un'applicazione del mondo reale utilizzando un'installazione globale di autocannon. L'esecuzione di autocannon -d=5 -c=300 CLOUD_FUNCTION_URL dal terminale aperto genererebbe 300 richieste simultanee alla funzione cloud entro una durata di 5 secondi. Questo è più che sufficiente per avviare la funzione cloud e generare anche alcune metriche che possiamo esplorare sulla dashboard della funzione.
Nota : l'endpoint di una funzione verrà stampato nel terminale dopo la distribuzione. In caso contrario, eseguire gcloud function describe FUNCTION_NAME dal terminale per ottenere i dettagli sulla funzione distribuita incluso l'endpoint.
Utilizzando la scheda delle metriche sulla dashboard, possiamo vedere una rappresentazione visiva dell'ultima richiesta composta da quante invocazioni sono state effettuate, quanto tempo sono durate, l'impronta di memoria della funzione e quante istanze sono state create per gestire le richieste effettuate.
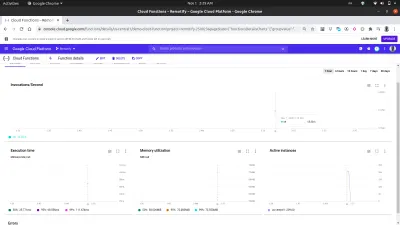
Uno sguardo più da vicino al grafico delle istanze attive nell'immagine sopra mostra la capacità di ridimensionamento orizzontale delle funzioni cloud, poiché possiamo vedere che 209 istanze sono state avviate in pochi secondi per gestire le richieste effettuate utilizzando il cannone automatico.
Registri delle funzioni cloud
Ogni funzione distribuita nel cloud di Google ha un registro e ogni volta che questa funzione viene eseguita, viene creata una nuova voce in quel registro. Dalla scheda Registro nella dashboard della funzione, possiamo vedere un elenco di tutte le voci di registro da una funzione cloud.
Di seguito sono riportate le voci di registro della nostra funzione demo-function distribuita creata a seguito delle richieste che abbiamo effettuato utilizzando autocannon .
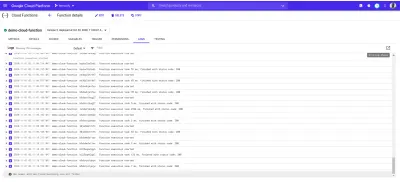
Ciascuna delle voci di registro sopra mostra esattamente quando una funzione è stata eseguita, quanto tempo ha impiegato l'esecuzione e con quale codice di stato è terminata. Se sono presenti errori risultanti da una funzione, i dettagli dell'errore inclusa la riga in cui si è verificato verranno visualizzati nei registri qui.
Logs Explorer su Google Cloud può essere utilizzato per visualizzare dettagli più completi sui log da una funzione cloud.
Funzioni cloud con applicazioni front-end
Le funzioni cloud sono molto utili e potenti per gli ingegneri front-end. Un ingegnere front-end senza la conoscenza della gestione delle applicazioni back-end può estrarre una funzionalità in una funzione cloud, distribuirla su Google Cloud e utilizzarla in un'applicazione front-end effettuando richieste HTTP alla funzione cloud tramite il suo endpoint.
Per mostrare come le funzioni cloud possono essere utilizzate in un'applicazione front-end, aggiungeremo più funzionalità a questa applicazione React. L'applicazione dispone già di un routing di base tra l'autenticazione e l'impostazione delle home page. Lo espanderemo per utilizzare l'API React Context per gestire lo stato dell'applicazione poiché l'uso delle funzioni cloud create verrebbe eseguito all'interno dei riduttori dell'applicazione.
Per iniziare, creiamo il contesto della nostra applicazione utilizzando l'API createContext e creiamo anche un riduttore per la gestione delle azioni all'interno della nostra applicazione.
// state/index.js import { createContext } from “react”;export const UserReducer = (azione, stato) => { switch (action.type) { case “CREATE-USER”: break; caso “UPLOAD-USER-IMAGE”: interruzione; caso “FETCH-DATA” : interruzione caso “LOGOUT” : interruzione; default: console.log(
${action.type} is not recognized) } };export const userState = { utente: null, isLoggedIn : false };
export const UserContext = createContext(userState);
In precedenza, abbiamo iniziato con la creazione di una funzione UserReducer che contiene un'istruzione switch, che consente di eseguire un'operazione in base al tipo di azione inviata al suo interno. L'istruzione switch ha quattro casi e queste sono le azioni che tratteremo. Per ora non fanno ancora nulla, ma quando iniziamo a integrarci con le nostre funzioni cloud, implementeremmo in modo incrementale le azioni da eseguire al loro interno.
Abbiamo anche creato ed esportato il contesto della nostra applicazione utilizzando l'API React createContext e gli abbiamo fornito un valore predefinito dell'oggetto userState che contiene un valore utente attualmente che verrebbe aggiornato da null ai dati dell'utente dopo l'autenticazione e anche un valore booleano isLoggedIn per sapere se l'utente è connesso o meno.
Ora possiamo procedere a consumare il nostro contesto, ma prima di farlo, dobbiamo avvolgere l'intero albero dell'applicazione con il provider collegato a UserContext affinché i componenti figli possano sottoscrivere la modifica del valore del nostro contesto.
// index.js import React from "react"; import ReactDOM from "react-dom"; import "./index.css"; import App from "./app"; import { UserContext, userState } from "./state/"; ReactDOM.render( <React.StrictMode> <UserContext.Provider value={userState}> <App /> </UserContext.Provider> </React.StrictMode>, document.getElementById("root") ); serviceWorker.unregister(); Avvolgiamo la nostra applicazione di immissione con il provider UserContext nel componente radice e abbiamo passato il nostro valore predefinito userState creato in precedenza nel valore prop.
Ora che lo stato dell'applicazione è completamente configurato, possiamo passare alla creazione del modello di dati dell'utente utilizzando Google Cloud Firestore tramite una funzione cloud.
Gestione dei dati dell'applicazione
I dati di un utente all'interno di questa applicazione sono costituiti da un ID univoco, un'e-mail, una password e l'URL di un'immagine. Utilizzando una funzione cloud, questi dati verranno archiviati sul cloud utilizzando il servizio Cloud Firestore offerto su Google Cloud Platform.
Google Cloud Firestore , un database NoSQL flessibile è stato ricavato dal database Firebase Realtime con nuove funzionalità avanzate che consentono query più ricche e veloci insieme al supporto dei dati offline. I dati all'interno del servizio Firestore sono organizzati in raccolte e documenti simili ad altri database NoSQL come MongoDB.
È possibile accedere visivamente al Firestore tramite Google Cloud Console. Per avviarlo, apri il riquadro di navigazione a sinistra e scorri verso il basso fino alla sezione Database e fai clic su Firestore. Ciò mostrerebbe l'elenco delle raccolte per gli utenti con dati esistenti o richiederebbe all'utente di creare una nuova raccolta quando non esiste una raccolta esistente. Creeremmo una raccolta di utenti da utilizzare con la nostra applicazione.
Simile ad altri servizi su Google Cloud Platform, Cloud Firestore ha anche una libreria client JavaScript creata per essere utilizzata in un ambiente nodo ( verrà generato un errore se utilizzato nel browser ). Per improvvisare utilizziamo Cloud Firestore in una funzione cloud utilizzando il pacchetto @google-cloud/firestore .
Utilizzo di Cloud Firestore con una funzione cloud
Per iniziare, rinomineremo la prima funzione che abbiamo creato da demo-function a firestoreFunction , quindi la espanderemo per connetterci con Firestore e salvare i dati nella raccolta dei nostri utenti.
require("dotenv").config(); const { Firestore } = require("@google-cloud/firestore"); const { SecretManagerServiceClient } = require("@google-cloud/secret-manager"); const client = new SecretManagerServiceClient(); exports.firestoreFunction = function (req, res) { return { const { email, password, type } = req.body; const firestore = new Firestore(); const document = firestore.collection("users"); console.log(document) // prints details of the collection to the function logs if (!type) { res.status(422).send("An action type was not specified"); } switch (type) { case "CREATE-USER": break case "LOGIN-USER": break; default: res.status(422).send(`${type} is not a valid function action`) } }; Per gestire più operazioni che coinvolgono il fire-store, abbiamo aggiunto un'istruzione switch con due casi per gestire le esigenze di autenticazione della nostra applicazione. La nostra istruzione switch valuta un'espressione di type che aggiungiamo al corpo della richiesta quando si effettua una richiesta a questa funzione dalla nostra applicazione e ogni volta che questo type di dati non è presente nel nostro corpo della richiesta, la richiesta viene identificata come una richiesta errata e un codice di stato 400 accanto a un messaggio per indicare il type mancante viene inviato come risposta.
Stabiliamo una connessione con Firestore utilizzando la libreria Application Default Credentials (ADC) all'interno della libreria client di Cloud Firestore. Nella riga successiva, chiamiamo il metodo di raccolta in un'altra variabile e passiamo il nome della nostra raccolta. Utilizzeremo questo per eseguire ulteriormente altre operazioni sulla raccolta dei documenti contenuti.
Nota : le librerie client per i servizi su Google Cloud si connettono al rispettivo servizio utilizzando una chiave dell'account di servizio creata e trasmessa durante l'inizializzazione del costruttore. Quando la chiave dell'account di servizio non è presente, per impostazione predefinita utilizza le credenziali predefinite dell'applicazione che a sua volta si connette utilizzando i ruoli IAM assegnati alla funzione cloud.

Dopo aver modificato il codice sorgente di una funzione che è stata distribuita localmente utilizzando Gcloud SDK, possiamo eseguire nuovamente il comando precedente da un terminale per aggiornare e ridistribuire la funzione cloud.
Ora che è stata stabilita una connessione, possiamo implementare il caso CREATE-USER per creare un nuovo utente utilizzando i dati del corpo della richiesta.
require("dotenv").config(); const { Firestore } = require("@google-cloud/firestore"); const path = require("path"); const { v4 : uuid } = require("uuid") const cors = require("cors")({ origin: true }); const client = new SecretManagerServiceClient(); exports.firestoreFunction = function (req, res) { return cors(req, res, () => { const { email, password, type } = req.body; const firestore = new Firestore(); const document = firestore.collection("users"); if (!type) { res.status(422).send("An action type was not specified"); } switch (type) { case "CREATE-USER": if (!email || !password) { res.status(422).send("email and password fields missing"); } const id = uuid() return bcrypt.genSalt(10, (err, salt) => { bcrypt.hash(password, salt, (err, hash) => { document.doc(id) .set({ id : id email: email, password: hash, img_uri : null }) .then((response) => res.status(200).send(response)) .catch((e) => res.status(501).send({ error : e }) ); }); }); case "LOGIN": break; default: res.status(400).send(`${type} is not a valid function action`) } }); }; Abbiamo generato un UUID utilizzando il pacchetto uuid da utilizzare come ID del documento che sta per essere salvato passandolo nel metodo set sul documento e anche l'id dell'utente. Per impostazione predefinita, viene generato un ID casuale su ogni documento inserito, ma in questo caso aggiorneremo il documento durante la gestione del caricamento dell'immagine e l'UUID è ciò che verrà utilizzato per ottenere l'aggiornamento di un particolare documento. Invece di memorizzare la password dell'utente in testo normale, la saltiamo prima usando bcryptjs, quindi memorizziamo l'hash del risultato come password dell'utente.
Integrando la funzione cloud firestoreFunction nell'app, la utilizziamo dal caso CREATE_USER all'interno del riduttore utente.
Dopo aver fatto clic sul pulsante Crea account , viene inviata un'azione ai riduttori con un tipo CREATE_USER per effettuare una richiesta POST contenente l'e-mail digitata e la password all'endpoint della funzione firestoreFunction .
import { createContext } from "react"; import { navigate } from "@reach/router"; import Axios from "axios"; export const userState = { user : null, isLoggedIn: false, }; export const UserReducer = (state, action) => { switch (action.type) { case "CREATE_USER": const FIRESTORE_FUNCTION = process.env.REACT_APP_FIRESTORE_FUNCTION; const { userEmail, userPassword } = action; const data = { type: "CREATE-USER", email: userEmail, password: userPassword, }; Axios.post(`${FIRESTORE_FUNCTION}`, data) .then((res) => { navigate("/home"); return { ...state, isLoggedIn: true }; }) .catch((e) => console.log(`couldnt create user. error : ${e}`)); break; case "LOGIN-USER": break; case "UPLOAD-USER-IMAGE": break; case "FETCH-DATA" : break case "LOGOUT": navigate("/login"); return { ...state, isLoggedIn: false }; default: break; } }; export const UserContext = createContext(userState); Sopra, abbiamo utilizzato Axios per effettuare la richiesta alla firestoreFunction e dopo che questa richiesta è stata risolta abbiamo impostato lo stato iniziale dell'utente da null ai dati restituiti dalla richiesta e infine instradamo l'utente alla home page come utente autenticato .
A questo punto, un nuovo utente può creare correttamente un account e essere indirizzato alla home page. Questo processo mostra come utilizziamo Firestore per eseguire una creazione di base di dati da una funzione cloud.
Gestione dell'archiviazione dei file
L'archiviazione e il recupero dei file di un utente in un'applicazione è il più delle volte una funzionalità molto necessaria all'interno di un'applicazione. In un'applicazione connessa a un backend node.js, Multer viene spesso utilizzato come middleware per gestire i dati multipart/form in cui arriva un file caricato. Ma in assenza del backend node.js, potremmo usare un file online servizio di archiviazione come Google Cloud Storage per archiviare risorse di applicazioni statiche.
Google Cloud Storage è un servizio di archiviazione file disponibile a livello globale utilizzato per archiviare qualsiasi quantità di dati come oggetti per applicazioni in bucket. È sufficientemente flessibile per gestire l'archiviazione di risorse statiche per applicazioni di piccole e grandi dimensioni.
Per utilizzare il servizio Cloud Storage all'interno di un'applicazione, potremmo utilizzare gli endpoint dell'API di archiviazione disponibili o utilizzando la libreria client di archiviazione del nodo ufficiale. Tuttavia, la libreria client Node Storage non funziona all'interno di una finestra del browser, quindi potremmo utilizzare una funzione cloud in cui utilizzeremo la libreria.
Un esempio di ciò è la funzione Cloud sottostante che si connette e carica un file in un Cloud Bucket creato.
const cors = require("cors")({ origin: true }); const { Storage } = require("@google-cloud/storage"); const StorageClient = new Storage(); exports.Uploader = (req, res) => { const { file } = req.body; StorageClient.bucket("TEST_BUCKET") .file(file.name) .then((response) => { console.log(response); res.status(200).send(response) }) .catch((e) => res.status(422).send({error : e})); }); };Dalla funzione cloud sopra, stiamo eseguendo le due seguenti operazioni principali:
Innanzitutto, creiamo una connessione al Cloud Storage all'interno del
Storage constructordi Storage e utilizza la funzione ADC (Application Default Credentials) su Google Cloud per autenticarsi con il Cloud Storage.In secondo luogo, carichiamo il file incluso nel corpo della richiesta nel nostro
TEST_BUCKETchiamando il metodo.filee passando il nome del file. Poiché si tratta di un'operazione asincrona, utilizziamo una promessa per sapere quando questa azione è stata risolta e inviamo una risposta200, terminando così il ciclo di vita dell'invocazione.
Ora possiamo espandere la funzione Uploader Cloud sopra per gestire il caricamento dell'immagine del profilo di un utente. La funzione cloud riceverà l'immagine del profilo di un utente, la memorizzerà nel bucket cloud della nostra applicazione e quindi aggiornerà i dati img_uri dell'utente all'interno della raccolta dei nostri utenti nel servizio Firestore.
require("dotenv").config(); const { Firestore } = require("@google-cloud/firestore"); const cors = require("cors")({ origin: true }); const { Storage } = require("@google-cloud/storage"); const StorageClient = new Storage(); const BucketName = process.env.STORAGE_BUCKET exports.Uploader = (req, res) => { return Cors(req, res, () => { const { file , userId } = req.body; const firestore = new Firestore(); const document = firestore.collection("users"); StorageClient.bucket(BucketName) .file(file.name) .on("finish", () => { StorageClient.bucket(BucketName) .file(file.name) .makePublic() .then(() => { const img_uri = `https://storage.googleapis.com/${Bucket}/${file.path}`; document .doc(userId) .update({ img_uri, }) .then((updateResult) => res.status(200).send(updateResult)) .catch((e) => res.status(500).send(e)); }) .catch((e) => console.log(e)); }); }); };Ora abbiamo ampliato la funzione di caricamento sopra per eseguire le seguenti operazioni extra:
- Innanzitutto, effettua una nuova connessione al servizio Firestore per ottenere la raccolta dei nostri
usersinizializzando il costruttore Firestore e utilizza le credenziali di default dell'applicazione (ADC) per autenticarsi con Cloud Storage. - Dopo aver caricato il file aggiunto nel corpo della richiesta, lo rendiamo pubblico per essere accessibile tramite un URL pubblico chiamando il metodo
makePublicsul file caricato. Secondo il controllo di accesso predefinito di Cloud Storage, senza rendere pubblico un file, non è possibile accedere a un file su Internet e per essere in grado di farlo quando l'applicazione viene caricata.
Nota : rendere pubblico un file significa che chiunque utilizzi la tua applicazione può copiare il collegamento al file e avere accesso illimitato al file. Un modo per evitarlo è utilizzare un URL firmato per concedere l'accesso temporaneo a un file all'interno del tuo bucket invece di renderlo completamente pubblico.
- Successivamente, aggiorniamo i dati esistenti dell'utente per includere l'URL del file caricato. Troviamo i dati dell'utente particolare utilizzando la query
WHEREdi Firestore e utilizziamo l'userIdutente incluso nel corpo della richiesta, quindi impostiamo il campoimg_uriper contenere l'URL dell'immagine appena aggiornata.
La funzione Upload cloud di cui sopra può essere utilizzata all'interno di qualsiasi applicazione con utenti registrati nel servizio Firestore. Tutto ciò che serve per effettuare una richiesta POST all'endpoint, inserendo l'IS dell'utente e un'immagine nel corpo della richiesta.
Un esempio di ciò all'interno dell'applicazione è il caso UPLOAD-FILE che effettua una richiesta POST alla funzione e pone il collegamento dell'immagine restituito dalla richiesta nello stato dell'applicazione.
# index.js import Axios from 'axios' const UPLOAD_FUNCTION = process.env.REACT_APP_UPLOAD_FUNCTION export const UserReducer = (state, action) => { switch (action.type) { case "CREATE-USER" : # .....CREATE-USER-LOGIC .... case "UPLOAD-FILE": const { file, id } = action return Axios.post(UPLOAD_FUNCTION, { file, id }, { headers: { "Content-Type": "image/png", }, }) .then((response) => {}) .catch((e) => console.log(e)); default : return console.log(`${action.type} case not recognized`) } } Dal caso di commutazione sopra, facciamo una richiesta POST usando Axios a UPLOAD_FUNCTION passando il file aggiunto da includere nel corpo della richiesta e abbiamo anche aggiunto un'immagine Content-Type nell'intestazione della richiesta.
Dopo un caricamento riuscito, la risposta restituita dalla funzione cloud contiene il documento dati dell'utente che è stato aggiornato per contenere un URL valido dell'immagine caricata nel cloud storage di google. Possiamo quindi aggiornare lo stato dell'utente per contenere i nuovi dati e questo aggiornerà anche l'elemento src dell'immagine del profilo dell'utente nel componente del profilo.
Gestione dei lavori Cron
Le attività automatiche ripetitive come l'invio di e-mail agli utenti o l'esecuzione di un'azione interna in un momento specifico sono il più delle volte una funzionalità inclusa nelle applicazioni. In una normale applicazione node.js, tali attività possono essere gestite come lavori cron utilizzando node-cron o node-schedule. Quando si creano applicazioni serverless utilizzando Google Cloud Platform, Cloud Scheduler è progettato anche per eseguire un'operazione cron.
Nota : sebbene Cloud Scheduler funzioni in modo simile all'utilità cron Unix nella creazione di lavori che verranno eseguiti in futuro, è importante notare che Cloud Scheduler non esegue un comando come fa l'utilità cron. Piuttosto esegue un'operazione utilizzando una destinazione specificata.
Come suggerisce il nome, Cloud Scheduler consente agli utenti di pianificare un'operazione da eseguire in futuro. Ogni operazione è chiamata lavoro e i lavori possono essere creati, aggiornati e persino distrutti visivamente dalla sezione Scheduler di Cloud Console. Oltre a un campo nome e descrizione, i lavori su Cloud Scheduler sono costituiti da quanto segue:
- Frequenza
Viene utilizzato per pianificare l'esecuzione del lavoro Cron. Le pianificazioni vengono specificate utilizzando il formato unix-cron originariamente utilizzato durante la creazione di lavori in background sulla tabella cron in un ambiente Linux. Il formato unix-cron consiste in una stringa con cinque valori ciascuno che rappresenta un punto temporale. Di seguito possiamo vedere ciascuna delle cinque stringhe e i valori che rappresentano.
- - - - - - - - - - - - - - - - minute ( - 59 ) | - - - - - - - - - - - - - hour ( 0 - 23 ) | | - - - - - - - - - - - - day of month ( 1 - 31 ) | | | - - - - - - - - - month ( 1 - 12 ) | | | | - - - - - -- day of week ( 0 - 6 ) | | | | | | | | | | | | | | | | | | | | | | | | | * * * * *Lo strumento generatore Crontab è utile quando si tenta di generare un valore frequenza-tempo per un lavoro. Se hai difficoltà a mettere insieme i valori temporali, il generatore di Crontab ha un menu a discesa visivo in cui puoi selezionare i valori che compongono una pianificazione e copiare il valore generato e usarlo come frequenza.
- Fuso orario
Il fuso orario da cui viene eseguito il lavoro cron. A causa della differenza di orario tra i fusi orari, i lavori cron eseguiti con diversi fusi orari specificati avranno tempi di esecuzione diversi. - Obbiettivo
Questo è ciò che viene utilizzato nell'esecuzione del lavoro specificato. Una destinazione potrebbe essere un tipoHTTPin cui il lavoro effettua una richiesta all'ora specificata all'URL o un argomento Pub/Sub in cui il lavoro può pubblicare messaggi o estrarre messaggi e infine un'applicazione App Engine.
Il Cloud Scheduler si combina perfettamente con le funzioni cloud attivate da HTTP. Quando un lavoro all'interno del Cloud Scheduler viene creato con la sua destinazione impostata su HTTP, questo lavoro può essere utilizzato per eseguire una funzione cloud. Tutto ciò che deve essere fatto è specificare l'endpoint della funzione cloud, specificare il verbo HTTP della richiesta, quindi aggiungere tutti i dati che devono essere passati per funzionare nel campo del corpo visualizzato. Come mostrato nell'esempio seguente:
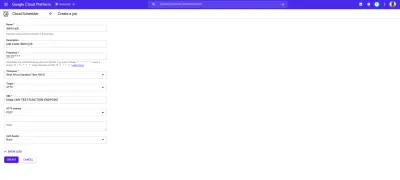
Il lavoro cron nell'immagine sopra verrà eseguito entro le 9:00 ogni giorno effettuando una richiesta POST all'endpoint di esempio di una funzione cloud.
Un caso d'uso più realistico di un processo cron è l'invio di e-mail programmate agli utenti a un determinato intervallo utilizzando un servizio di posta esterno come Mailgun. Per vederlo in azione, creeremo una nuova funzione cloud che invia un'e-mail HTML a un indirizzo e-mail specificato utilizzando il pacchetto JavaScript nodemailer per connettersi a Mailgun:
# index.js require("dotenv").config(); const nodemailer = require("nodemailer"); exports.Emailer = (req, res) => { let sender = process.env.SENDER; const { reciever, type } = req.body var transport = nodemailer.createTransport({ host: process.env.HOST, port: process.env.PORT, secure: false, auth: { user: process.env.SMTP_USERNAME, pass: process.env.SMTP_PASSWORD, }, }); if (!reciever) { res.status(400).send({ error: `Empty email address` }); } transport.verify(function (error, success) { if (error) { res .status(401) .send({ error: `failed to connect with stmp. check credentials` }); } }); switch (type) { case "statistics": return transport.sendMail( { from: sender, to: reciever, subject: "Your usage satistics of demo app", html: { path: "./welcome.html" }, }, (error, info) => { if (error) { res.status(401).send({ error : error }); } transport.close(); res.status(200).send({data : info}); } ); default: res.status(500).send({ error: "An available email template type has not been matched.", }); } };Using the cloud function above we can send an email to any user's email address specified as the receiver value in the request body. It performs the sending of emails through the following steps:
- It creates an SMTP transport for sending messages by passing the
host,userandpasswhich stands for password, all displayed on the user's Mailgun dashboard when a new account is created. - Next, it verifies if the SMTP transport has the credentials needed in order to establish a connection. If there's an error in establishing the connection, it ends the function's invocation and sends back a
401 unauthenticatedstatus code. - Next, it calls the
sendMailmethod to send the email containing the HTML file as the email's body to the receiver's email address specified in thetofield.
Note : We use a switch statement in the cloud function above to make it more reusable for sending several emails for different recipients. This way we can send different emails based on the type field included in the request body when calling this cloud function.
Now that there is a function that can send an email to a user; we are left with creating the cron job to invoke this cloud function. This time, the cron jobs are created dynamically each time a new user is created using the official Google cloud client library for the Cloud Scheduler from the initial firestoreFunction .
We expand the CREATE-USER case to create the job which sends the email to the created user at a one-day interval.
require("dotenv").config();cloc const { Firestore } = require("@google-cloud/firestore"); const scheduler = require("@google-cloud/scheduler") const cors = require("cors")({ origin: true }); const EMAILER = proccess.env.EMAILER_ENDPOINT const parent = ScheduleClient.locationPath( process.env.PROJECT_ID, process.env.LOCATION_ID ); exports.firestoreFunction = function (req, res) { return cors(req, res, () => { const { email, password, type } = req.body; const firestore = new Firestore(); const document = firestore.collection("users"); const client = new Scheduler.CloudSchedulerClient() if (!type) { res.status(422).send({ error : "An action type was not specified"}); } switch (type) { case "CREATE-USER":const job = { httpTarget: { uri: process.env.EMAIL_FUNCTION_ENDPOINT, httpMethod: "POST", body: { email: email, }, }, schedule: "*/30 */6 */5 10 4", timezone: "Africa/Lagos", }if (!email || !password) { res.status(422).send("email and password fields missing"); } return bcrypt.genSalt(10, (err, salt) => { bcrypt.hash(password, salt, (err, hash) => { document .add({ email: email, password: hash, }) .then((response) => {client.createJob({ parent : parent, job : job }).then(() => res.status(200).send(response)) .catch(e => console.log(`unable to create job : ${e}`) )}) .catch((e) => res.status(501).send(`error inserting data : ${e}`) ); }); }); default: res.status(422).send(`${type} is not a valid function action`) } }); };
From the snippet above, we can see the following:
- A connection to the Cloud Scheduler from the Scheduler constructor using the Application Default Credentials (ADC) is made.
- We create an object consisting of the following details which make up the cron job to be created:
-
uri
The endpoint of our email cloud function in which a request would be made to. -
body
This is the data containing the email address of the user to be included when the request is made. -
schedule
The unix cron format representing the time when this cron job is to be performed.
-
- After the promise from inserting the user's data document is resolved, we create the cron job by calling the
createJobmethod and passing in the job object and the parent. - The function's execution is ended with a
200status code after the promise from thecreateJoboperation has been resolved.
After the job is created, we'll see it listed on the scheduler page.
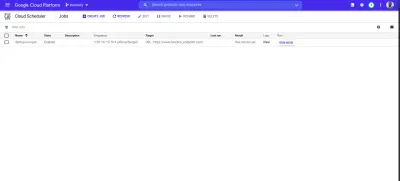
From the image above we can see the time scheduled for this job to be executed. We can decide to manually run this job or wait for it to be executed at the scheduled time.
Conclusione
Within this article, we have had a good look into serverless applications and the benefits of using them. We also had an extensive look at how developers can manage their serverless applications on the Google Cloud using Cloud Functions so you now know how the Google Cloud is supporting the use of serverless applications.
Within the next years to come, we will certainly see a large number of developers adapt to the use of serverless applications when building applications. If you are using cloud functions in a production environment, it is recommended that you read this article from a Google Cloud advocate on “6 Strategies For Scaling Your Serverless Applications”.
The source code of the created cloud functions are available within this Github repository and also the used front-end application within this Github repository. The front-end application has been deployed using Netlify and can be tested live here.
Riferimenti
- Google Cloud
- Cloud Functions
- Cloud Source Repositories
- Cloud Scheduler overview
- Cloud Firestore
- “6 Strategies For Scaling Your Serverless Applications,” Preston Holmes