
Créer des applications frontales sans serveur à l'aide de Google Cloud Platform
Publié: 2022-03-10Récemment, le paradigme de développement des applications a commencé à passer du déploiement, de la mise à l'échelle et de la mise à jour manuels des ressources utilisées dans une application à la dépendance à des fournisseurs de services cloud tiers pour effectuer la majeure partie de la gestion de ces ressources.
En tant que développeur ou organisation qui souhaite créer une application adaptée au marché dans les plus brefs délais, votre objectif principal peut être de fournir votre service d'application de base à vos utilisateurs pendant que vous consacrez moins de temps à la configuration, au déploiement et aux tests de résistance. ton application. Si tel est votre cas d'utilisation, la gestion de la logique métier de votre application sans serveur pourrait être votre meilleure option. Mais comment?
Cet article s'adresse aux ingénieurs frontaux qui souhaitent créer certaines fonctionnalités au sein de leur application ou aux ingénieurs backend qui souhaitent extraire et gérer certaines fonctionnalités d'un service backend existant à l'aide d'une application sans serveur déployée sur Google Cloud Platform.
Remarque : Pour bénéficier de ce qui sera couvert ici, vous devez avoir une expérience de travail avec React. Aucune expérience préalable dans les applications sans serveur n'est requise.
Avant de commencer, comprenons ce que sont réellement les applications sans serveur et comment l'architecture sans serveur peut être utilisée lors de la création d'une application dans le contexte d'un ingénieur front-end.
Applications sans serveur
Les applications sans serveur sont des applications décomposées en minuscules fonctions événementielles réutilisables, hébergées et gérées par des fournisseurs de services cloud tiers au sein du cloud public pour le compte de l'auteur de l'application. Ceux-ci sont déclenchés par certains événements et sont exécutés à la demande. Bien que le suffixe « moins » attaché au mot sans serveur indique l'absence de serveur, ce n'est pas le cas à 100 %. Ces applications fonctionnent toujours sur des serveurs et d'autres ressources matérielles, mais dans ce cas, ces ressources ne sont pas provisionnées par le développeur mais plutôt par un fournisseur de services cloud tiers. Ils sont donc sans serveur pour l'auteur de l'application, mais fonctionnent toujours sur des serveurs et sont accessibles via l'Internet public.
Un exemple d'utilisation d'une application sans serveur serait l'envoi d'e-mails aux utilisateurs potentiels qui visitent votre page de destination et s'abonnent pour recevoir des e-mails de lancement de produit. À ce stade, vous n'avez probablement pas de service back-end en cours d'exécution et vous ne voudriez pas sacrifier le temps et les ressources nécessaires pour en créer, déployer et gérer un, tout cela parce que vous devez envoyer des e-mails. Ici, vous pouvez écrire un seul fichier qui utilise un client de messagerie et le déployer sur n'importe quel fournisseur de cloud qui prend en charge les applications sans serveur et les laisser gérer cette application en votre nom pendant que vous connectez cette application sans serveur à votre page de destination.
Bien qu'il existe une tonne de raisons pour lesquelles vous pourriez envisager d'utiliser des applications sans serveur ou des fonctions en tant que service (FAAS) comme on les appelle, pour votre application frontale, voici quelques raisons très notables que vous devriez considérer :
- Mise à l'échelle automatique des applications
Les applications sans serveur sont mises à l'échelle horizontalement et cette « mise à l'échelle » est automatiquement effectuée par le fournisseur de Cloud en fonction du nombre d'invocations, de sorte que le développeur n'a pas à ajouter ou supprimer manuellement des ressources lorsque l'application est sous forte charge. - Rentabilité
Étant pilotées par les événements, les applications sans serveur ne s'exécutent qu'en cas de besoin, ce qui se répercute sur les frais car elles sont facturées en fonction du nombre d'appels. - Souplesse
Les applications sans serveur sont conçues pour être hautement réutilisables, ce qui signifie qu'elles ne sont pas liées à un seul projet ou application. Une fonctionnalité particulière peut être extraite dans une application sans serveur, déployée et utilisée dans plusieurs projets ou applications. Les applications sans serveur peuvent également être écrites dans la langue préférée de l'auteur de l'application, bien que certains fournisseurs de cloud ne prennent en charge qu'un plus petit nombre de langues.
Lorsqu'il utilise des applications sans serveur, chaque développeur dispose d'un vaste éventail de fournisseurs de cloud au sein du cloud public à utiliser. Dans le cadre de cet article, nous nous concentrerons sur les applications sans serveur sur Google Cloud Platform - comment elles sont créées, gérées, déployées et comment elles s'intègrent également à d'autres produits sur Google Cloud. Pour ce faire, nous ajouterons de nouvelles fonctionnalités à cette application React existante tout en travaillant sur le processus de :
- Stockage et récupération des données de l'utilisateur sur le cloud ;
- Créer et gérer des tâches cron sur Google Cloud ;
- Déploiement de Cloud Functions sur Google Cloud.
Remarque : Les applications sans serveur ne sont pas liées à React uniquement, tant que votre framework ou bibliothèque frontal préféré peut faire une requête HTTP , il peut utiliser une application sans serveur.
Fonctions Google Cloud
Le Google Cloud permet aux développeurs de créer des applications sans serveur à l'aide de Cloud Functions et de les exécuter à l'aide de Functions Framework. Comme on les appelle, les fonctions cloud sont des fonctions événementielles réutilisables déployées sur Google Cloud pour écouter un déclencheur spécifique parmi les six déclencheurs d'événement disponibles, puis effectuer l'opération pour laquelle elle a été écrite.
Les fonctions cloud de courte durée ( avec un délai d'exécution par défaut de 60 secondes et un maximum de 9 minutes ) peuvent être écrites à l'aide de JavaScript, Python, Golang et Java et exécutées à l'aide de leur environnement d'exécution. En JavaScript, ils peuvent être exécutés en utilisant uniquement certaines versions disponibles de l'environnement d'exécution Node et sont écrits sous la forme de modules CommonJS utilisant du JavaScript brut car ils sont exportés en tant que fonction principale à exécuter sur Google Cloud.
Un exemple de fonction cloud est celui ci-dessous qui est un passe-partout vide pour que la fonction gère les données d'un utilisateur.
// index.js exports.firestoreFunction = function (req, res) { return res.status(200).send({ data: `Hello ${req.query.name}` }); } Ci-dessus, nous avons un module qui exporte une fonction. Lorsqu'il est exécuté, il reçoit les arguments de requête et de réponse similaires à une route HTTP .
Remarque : Une fonction cloud correspond à chaque protocole HTTP lorsqu'une requête est effectuée. Cela vaut la peine d'être noté lorsque des données sont attendues dans l'argument de requête, car les données jointes lors d'une demande d'exécution d'une fonction cloud seraient présentes dans le corps de la requête pour les requêtes POST tandis que dans le corps de la requête pour les requêtes GET .
Les fonctions cloud peuvent être exécutées localement pendant le développement en installant le package @google-cloud/functions-framework dans le même dossier où la fonction écrite est placée ou en effectuant une installation globale pour l'utiliser pour plusieurs fonctions en exécutant npm i -g @google-cloud/functions-framework depuis votre ligne de commande. Une fois installé, il doit être ajouté au script package.json avec le nom du module exporté similaire à celui ci-dessous :
"scripts": { "start": "functions-framework --target=firestoreFunction --port=8000", } Ci-dessus, nous avons une seule commande dans nos scripts dans le fichier package.json qui exécute le framework de fonctions et spécifie également firestoreFunction comme fonction cible à exécuter localement sur le port 8000 .
Nous pouvons tester le point de terminaison de cette fonction en faisant une requête GET au port 8000 sur localhost en utilisant curl. Coller la commande ci-dessous dans un terminal le fera et renverra une réponse.
curl https://localhost:8000?name="Smashing Magazine Author" La commande ci-dessus fait une requête avec une méthode GET HTTP et répond avec un code d'état 200 et une donnée d'objet contenant le nom ajouté dans la requête.
Déploiement d'une fonction cloud
Parmi les méthodes de déploiement disponibles, un moyen rapide de déployer une fonction cloud à partir d'une machine locale consiste à utiliser le Sdk cloud après l'avoir installé. L'exécution de la commande ci-dessous à partir du terminal après avoir authentifié le SDK gcloud avec votre projet sur Google Cloud déploierait une fonction créée localement sur le service Cloud Function.
gcloud functions deploy "demo-function" --runtime nodejs10 --trigger-http --entry-point=demo --timeout=60 --set-env-vars=[name="Developer"] --allow-unauthenticatedEn utilisant les drapeaux expliqués ci-dessous, la commande ci-dessus déploie une fonction déclenchée par HTTP sur le cloud Google avec le nom « demo-function ».
- NOM
Il s'agit du nom donné à une fonction cloud lors de son déploiement et il est obligatoire. -
region
Il s'agit de la région dans laquelle la fonction cloud doit être déployée. Par défaut, il est déployé surus-central1. -
trigger-http
Cela sélectionne HTTP comme type de déclencheur de la fonction. -
allow-unauthenticated
Cela permet à la fonction d'être appelée en dehors de Google Cloud via Internet à l'aide de son point de terminaison généré sans vérifier si l'appelant est authentifié. -
source
Chemin local du terminal au fichier contenant la fonction à déployer. -
entry-point
Il s'agit du module spécifique exporté à déployer à partir du fichier dans lequel les fonctions ont été écrites. -
runtime
Il s'agit du runtime de langage à utiliser pour la fonction parmi cette liste de runtime acceptés. -
timeout
Il s'agit de la durée maximale d'exécution d'une fonction avant l'expiration du délai. Il est de 60 secondes par défaut et peut être réglé sur un maximum de 9 minutes.
Remarque : Faire en sorte qu'une fonction autorise les requêtes non authentifiées signifie que toute personne disposant du point de terminaison de votre fonction peut également effectuer des requêtes sans que vous l'accordiez. Pour atténuer cela, nous pouvons nous assurer que le point de terminaison reste privé en l'utilisant via des variables d'environnement ou en demandant des en-têtes d'autorisation à chaque demande.
Maintenant que notre fonction de démonstration a été déployée et que nous avons le point de terminaison, nous pouvons tester cette fonction comme si elle était utilisée dans une application réelle à l'aide d'une installation globale d'autocannon. L'exécution d' autocannon -d=5 -c=300 CLOUD_FUNCTION_URL à partir du terminal ouvert générerait 300 requêtes simultanées à la fonction cloud dans un délai de 5 secondes. C'est plus que suffisant pour démarrer la fonction cloud et également générer des métriques que nous pouvons explorer sur le tableau de bord de la fonction.
Remarque : Le point de terminaison d'une fonction sera imprimé dans le terminal après le déploiement. Si ce n'est pas le cas, exécutez gcloud function describe FUNCTION_NAME depuis le terminal pour obtenir les détails de la fonction déployée, y compris le point de terminaison.
À l'aide de l'onglet des métriques sur le tableau de bord, nous pouvons voir une représentation visuelle de la dernière requête comprenant le nombre d'appels effectués, leur durée, l'empreinte mémoire de la fonction et le nombre d'instances tournées pour gérer les requêtes effectuées.
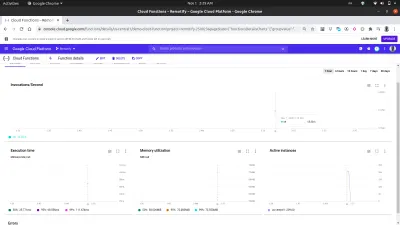
Un examen plus approfondi du graphique des instances actives dans l'image ci-dessus montre la capacité de mise à l'échelle horizontale des fonctions Cloud, car nous pouvons voir que 209 instances ont été créées en quelques secondes pour gérer les demandes effectuées à l'aide de l'autocanon.
Journaux de la fonction Cloud
Chaque fonction déployée sur le cloud Google a un journal et chaque fois que cette fonction est exécutée, une nouvelle entrée dans ce journal est créée. Dans l'onglet Journal du tableau de bord de la fonction, nous pouvons voir une liste de toutes les entrées de journaux d'une fonction cloud.
Vous trouverez ci-dessous les entrées de journal de notre demo-function déployée créée à la suite des demandes que nous avons effectuées à l'aide de autocannon .
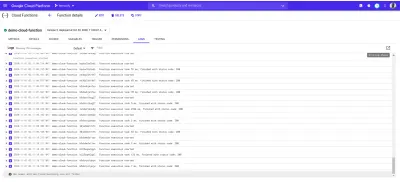
Chacune des entrées de journal ci-dessus indique exactement quand une fonction a été exécutée, combien de temps l'exécution a pris et avec quel code d'état elle s'est terminée. S'il y a des erreurs résultant d'une fonction, les détails de l'erreur, y compris la ligne à laquelle elle s'est produite, seront affichés dans les journaux ici.
L'explorateur de journaux sur Google Cloud peut être utilisé pour afficher des détails plus complets sur les journaux d'une fonction cloud.
Fonctions cloud avec applications frontales
Les fonctions cloud sont très utiles et puissantes pour les ingénieurs front-end. Un ingénieur frontal sans connaissance de la gestion des applications back-end peut extraire une fonctionnalité dans une fonction cloud, la déployer sur Google Cloud et l'utiliser dans une application frontale en adressant des requêtes HTTP à la fonction cloud via son point de terminaison.
Pour montrer comment les fonctions cloud peuvent être utilisées dans une application frontale, nous allons ajouter plus de fonctionnalités à cette application React. L'application dispose déjà d'un routage de base entre l'authentification et la configuration des pages d'accueil. Nous allons l'étendre pour utiliser l'API React Context pour gérer l'état de notre application car l'utilisation des fonctions cloud créées se ferait dans les réducteurs d'application.
Pour commencer, nous créons le contexte de notre application à l'aide de l'API createContext et créons également un réducteur pour gérer les actions dans notre application.
// state/index.js import { createContext } from “react”;export const UserReducer = (action, état) => { switch (action.type) { case "CREATE-USER": break; cas "UPLOAD-USER-IMAGE": pause ; cas « FETCH-DATA » : pause cas « LOGOUT » : pause ; par défaut : console.log(
${action.type} is not recognized) } } ;export const userState = { utilisateur : null, isLoggedIn : false } ;
export const UserContext = createContext(userState);
Ci-dessus, nous avons commencé par créer une fonction UserReducer qui contient une instruction switch, lui permettant d'effectuer une opération basée sur le type d'action qui lui est envoyée. L'instruction switch a quatre cas et ce sont les actions que nous allons gérer. Pour l'instant, ils ne font encore rien, mais lorsque nous commencerons à nous intégrer à nos fonctions cloud, nous mettrons progressivement en œuvre les actions à y effectuer.
Nous avons également créé et exporté le contexte de notre application à l'aide de l'API React createContext et lui avons donné une valeur par défaut de l'objet userState qui contient actuellement une valeur utilisateur qui serait mise à jour de null aux données de l'utilisateur après l'authentification et également une valeur booléenne isLoggedIn pour savoir si l'utilisateur est connecté ou non.
Nous pouvons maintenant continuer à consommer notre contexte, mais avant cela, nous devons encapsuler l'ensemble de notre arborescence d'applications avec le fournisseur attaché au UserContext pour que les composants enfants puissent souscrire au changement de valeur de notre contexte.
// index.js import React from "react"; import ReactDOM from "react-dom"; import "./index.css"; import App from "./app"; import { UserContext, userState } from "./state/"; ReactDOM.render( <React.StrictMode> <UserContext.Provider value={userState}> <App /> </UserContext.Provider> </React.StrictMode>, document.getElementById("root") ); serviceWorker.unregister(); Nous enveloppons notre application d'entrée avec le fournisseur UserContext au niveau du composant racine et transmettons notre valeur par défaut userState précédemment créée dans la valeur prop.
Maintenant que l'état de notre application est entièrement configuré, nous pouvons passer à la création du modèle de données de l'utilisateur à l'aide de Google Cloud Firestore via une fonction cloud.
Gestion des données d'application
Les données d'un utilisateur dans cette application se composent d'un identifiant unique, d'un e-mail, d'un mot de passe et de l'URL d'une image. À l'aide d'une fonction cloud, ces données seront stockées sur le cloud à l'aide du service Cloud Firestore proposé sur la plate-forme Google Cloud.
Google Cloud Firestore , une base de données NoSQL flexible, a été créée à partir de la base de données en temps réel Firebase avec de nouvelles fonctionnalités améliorées qui permettent des requêtes plus riches et plus rapides parallèlement à la prise en charge des données hors ligne. Les données du service Firestore sont organisées en collections et documents similaires à d'autres bases de données NoSQL telles que MongoDB.
Le Firestore est accessible visuellement via Google Cloud Console. Pour le lancer, ouvrez le volet de navigation de gauche et faites défiler jusqu'à la section Base de données et cliquez sur Firestore. Cela afficherait la liste des collections pour les utilisateurs avec des données existantes ou inviterait l'utilisateur à créer une nouvelle collection lorsqu'il n'y a pas de collection existante. Nous créerions une collection d' utilisateurs à utiliser par notre application.
Semblable à d'autres services sur Google Cloud Platform, Cloud Firestore dispose également d'une bibliothèque client JavaScript conçue pour être utilisée dans un environnement de nœud ( une erreur sera générée si elle est utilisée dans le navigateur ). Pour improviser, on utilise le Cloud Firestore dans une fonction cloud en utilisant le package @google-cloud/firestore .
Utilisation du Cloud Firestore avec une fonction Cloud
Pour commencer, nous allons renommer la première fonction que nous avons créée de demo-function en firestoreFunction , puis la développer pour se connecter au Firestore et enregistrer les données dans la collection de nos utilisateurs.
require("dotenv").config(); const { Firestore } = require("@google-cloud/firestore"); const { SecretManagerServiceClient } = require("@google-cloud/secret-manager"); const client = new SecretManagerServiceClient(); exports.firestoreFunction = function (req, res) { return { const { email, password, type } = req.body; const firestore = new Firestore(); const document = firestore.collection("users"); console.log(document) // prints details of the collection to the function logs if (!type) { res.status(422).send("An action type was not specified"); } switch (type) { case "CREATE-USER": break case "LOGIN-USER": break; default: res.status(422).send(`${type} is not a valid function action`) } }; Pour gérer plus d'opérations impliquant le fire-store, nous avons ajouté une instruction switch avec deux cas pour gérer les besoins d'authentification de notre application. Notre instruction switch évalue une expression de type que nous ajoutons au corps de la requête lors d'une requête à cette fonction depuis notre application et chaque fois que ces données de type ne sont pas présentes dans notre corps de requête, la requête est identifiée comme une requête incorrecte et un code d'état 400 à côté d'un message indiquant que le type manquant est envoyé en réponse.
Nous établissons une connexion avec Firestore à l'aide de la bibliothèque Application Default Credentials (ADC) dans la bibliothèque client Cloud Firestore. Sur la ligne suivante, nous appelons la méthode de collection dans une autre variable et transmettons le nom de notre collection. Nous allons l'utiliser pour effectuer d'autres opérations sur la collecte des documents contenus.
Remarque : Les bibliothèques clientes pour les services sur Google Cloud se connectent à leur service respectif à l'aide d'une clé de compte de service créée transmise lors de l'initialisation du constructeur. Lorsque la clé de compte de service n'est pas présente, elle utilise par défaut les informations d'identification par défaut de l'application qui, à leur tour, se connectent à l'aide des rôles IAM attribués à la fonction cloud.

Après avoir modifié le code source d'une fonction qui a été déployée localement à l'aide du SDK Gcloud, nous pouvons réexécuter la commande précédente depuis un terminal pour mettre à jour et redéployer la fonction cloud.
Maintenant qu'une connexion a été établie, nous pouvons implémenter le cas CREATE-USER pour créer un nouvel utilisateur en utilisant les données du corps de la requête.
require("dotenv").config(); const { Firestore } = require("@google-cloud/firestore"); const path = require("path"); const { v4 : uuid } = require("uuid") const cors = require("cors")({ origin: true }); const client = new SecretManagerServiceClient(); exports.firestoreFunction = function (req, res) { return cors(req, res, () => { const { email, password, type } = req.body; const firestore = new Firestore(); const document = firestore.collection("users"); if (!type) { res.status(422).send("An action type was not specified"); } switch (type) { case "CREATE-USER": if (!email || !password) { res.status(422).send("email and password fields missing"); } const id = uuid() return bcrypt.genSalt(10, (err, salt) => { bcrypt.hash(password, salt, (err, hash) => { document.doc(id) .set({ id : id email: email, password: hash, img_uri : null }) .then((response) => res.status(200).send(response)) .catch((e) => res.status(501).send({ error : e }) ); }); }); case "LOGIN": break; default: res.status(400).send(`${type} is not a valid function action`) } }); }; Nous avons généré un UUID en utilisant le package uuid à utiliser comme ID du document sur le point d'être enregistré en le passant dans la méthode set sur le document ainsi que l'identifiant de l'utilisateur. Par défaut, un identifiant aléatoire est généré sur chaque document inséré, mais dans ce cas, nous mettrons à jour le document lors de la gestion du téléchargement de l'image et l'UUID est ce qui sera utilisé pour obtenir la mise à jour d'un document particulier. Plutôt que de stocker le mot de passe de l'utilisateur en texte brut, nous le salons d'abord à l'aide de bcryptjs, puis stockons le hachage du résultat en tant que mot de passe de l'utilisateur.
En intégrant la fonction cloud firestoreFunction dans l'application, nous l'utilisons à partir du cas CREATE_USER dans le réducteur d'utilisateur.
Après avoir cliqué sur le bouton Créer un compte , une action est envoyée aux réducteurs avec un type CREATE_USER pour effectuer une requête POST contenant l'e-mail et le mot de passe saisis au point de terminaison de la fonction firestoreFunction .
import { createContext } from "react"; import { navigate } from "@reach/router"; import Axios from "axios"; export const userState = { user : null, isLoggedIn: false, }; export const UserReducer = (state, action) => { switch (action.type) { case "CREATE_USER": const FIRESTORE_FUNCTION = process.env.REACT_APP_FIRESTORE_FUNCTION; const { userEmail, userPassword } = action; const data = { type: "CREATE-USER", email: userEmail, password: userPassword, }; Axios.post(`${FIRESTORE_FUNCTION}`, data) .then((res) => { navigate("/home"); return { ...state, isLoggedIn: true }; }) .catch((e) => console.log(`couldnt create user. error : ${e}`)); break; case "LOGIN-USER": break; case "UPLOAD-USER-IMAGE": break; case "FETCH-DATA" : break case "LOGOUT": navigate("/login"); return { ...state, isLoggedIn: false }; default: break; } }; export const UserContext = createContext(userState); Ci-dessus, nous avons utilisé Axios pour faire la demande à firestoreFunction et une fois cette demande résolue, nous avons défini l'état initial de l'utilisateur de null aux données renvoyées par la demande et enfin nous avons redirigé l'utilisateur vers la page d'accueil en tant qu'utilisateur authentifié .
À ce stade, un nouvel utilisateur peut créer un compte avec succès et être redirigé vers la page d'accueil. Ce processus montre comment nous utilisons le Firestore pour effectuer une création de base de données à partir d'une fonction cloud.
Gestion du stockage de fichiers
Le stockage et la récupération des fichiers d'un utilisateur dans une application est la plupart du temps une fonctionnalité indispensable dans une application. Dans une application connectée à un backend node.js, Multer est souvent utilisé comme middleware pour gérer les données multipart/form dans lesquelles un fichier téléchargé entre. Mais en l'absence du backend node.js, nous pourrions utiliser un fichier en ligne service de stockage tel que Google Cloud Storage pour stocker les ressources d'application statiques.
Google Cloud Storage est un service de stockage de fichiers disponible dans le monde entier utilisé pour stocker n'importe quelle quantité de données en tant qu'objets pour les applications dans des compartiments. Il est suffisamment flexible pour gérer le stockage des actifs statiques pour les applications de petite et de grande taille.
Pour utiliser le service Cloud Storage dans une application, nous pouvons utiliser les points de terminaison de l'API de stockage disponibles ou en utilisant la bibliothèque cliente de stockage de nœud officielle. Cependant, la bibliothèque cliente Node Storage ne fonctionne pas dans une fenêtre de navigateur, nous pouvons donc utiliser une fonction Cloud dans laquelle nous utiliserons la bibliothèque.
Un exemple de ceci est la fonction Cloud ci-dessous qui se connecte et télécharge un fichier dans un compartiment Cloud créé.
const cors = require("cors")({ origin: true }); const { Storage } = require("@google-cloud/storage"); const StorageClient = new Storage(); exports.Uploader = (req, res) => { const { file } = req.body; StorageClient.bucket("TEST_BUCKET") .file(file.name) .then((response) => { console.log(response); res.status(200).send(response) }) .catch((e) => res.status(422).send({error : e})); }); };A partir de la fonction cloud ci-dessus, nous effectuons les deux opérations principales suivantes :
Tout d'abord, nous créons une connexion au Cloud Storage dans le
Storage constructorde stockage et il utilise la fonctionnalité Application Default Credentials (ADC) sur Google Cloud pour s'authentifier auprès du Cloud Storage.Deuxièmement, nous téléchargeons le fichier inclus dans le corps de la requête dans notre
TEST_BUCKETen appelant la méthode.fileet en transmettant le nom du fichier. Comme il s'agit d'une opération asynchrone, nous utilisons une promesse pour savoir quand cette action a été résolue et nous renvoyons une réponse200, mettant ainsi fin au cycle de vie de l'invocation.
Maintenant, nous pouvons étendre la fonction Uploader Cloud ci-dessus pour gérer le téléchargement de l'image de profil d'un utilisateur. La fonction cloud recevra l'image de profil d'un utilisateur, la stockera dans le compartiment cloud de notre application, puis mettra à jour les données img_uri de l'utilisateur dans la collection de nos utilisateurs dans le service Firestore.
require("dotenv").config(); const { Firestore } = require("@google-cloud/firestore"); const cors = require("cors")({ origin: true }); const { Storage } = require("@google-cloud/storage"); const StorageClient = new Storage(); const BucketName = process.env.STORAGE_BUCKET exports.Uploader = (req, res) => { return Cors(req, res, () => { const { file , userId } = req.body; const firestore = new Firestore(); const document = firestore.collection("users"); StorageClient.bucket(BucketName) .file(file.name) .on("finish", () => { StorageClient.bucket(BucketName) .file(file.name) .makePublic() .then(() => { const img_uri = `https://storage.googleapis.com/${Bucket}/${file.path}`; document .doc(userId) .update({ img_uri, }) .then((updateResult) => res.status(200).send(updateResult)) .catch((e) => res.status(500).send(e)); }) .catch((e) => console.log(e)); }); }); };Nous avons maintenant étendu la fonction Upload ci-dessus pour effectuer les opérations supplémentaires suivantes :
- Tout d'abord, il établit une nouvelle connexion au service Firestore pour obtenir notre collection d'
usersen initialisant le constructeur Firestore et il utilise les informations d'identification par défaut de l'application (ADC) pour s'authentifier auprès de Cloud Storage. - Après avoir téléchargé le fichier ajouté dans le corps de la requête, nous le rendons public afin d'être accessible via une URL publique en appelant la méthode
makePublicsur le fichier téléchargé. Selon le contrôle d'accès par défaut de Cloud Storage, sans rendre un fichier public, un fichier ne peut pas être consulté sur Internet et pour pouvoir le faire lors du chargement de l'application.
Remarque : Rendre un fichier public signifie que toute personne utilisant votre application peut copier le lien du fichier et avoir un accès illimité au fichier. Une façon d'éviter cela consiste à utiliser une URL signée pour accorder un accès temporaire à un fichier dans votre compartiment au lieu de le rendre entièrement public.
- Ensuite, nous mettons à jour les données existantes de l'utilisateur pour inclure l'URL du fichier téléchargé. Nous trouvons les données de l'utilisateur particulier à l'aide de la requête
WHEREde Firestore et nous utilisons l'userIdutilisateur inclus dans le corps de la requête, puis nous définissons le champimg_uripour qu'il contienne l'URL de l'image nouvellement mise à jour.
La fonction Upload cloud ci-dessus peut être utilisée dans n'importe quelle application ayant des utilisateurs enregistrés dans le service Firestore. Tout ce qu'il faut pour faire une requête POST au point de terminaison, en mettant le SI de l'utilisateur et une image dans le corps de la requête.
Un exemple de cela dans l'application est le cas UPLOAD-FILE qui fait une requête POST à la fonction et place le lien image renvoyé par la requête dans l'état de l'application.
# index.js import Axios from 'axios' const UPLOAD_FUNCTION = process.env.REACT_APP_UPLOAD_FUNCTION export const UserReducer = (state, action) => { switch (action.type) { case "CREATE-USER" : # .....CREATE-USER-LOGIC .... case "UPLOAD-FILE": const { file, id } = action return Axios.post(UPLOAD_FUNCTION, { file, id }, { headers: { "Content-Type": "image/png", }, }) .then((response) => {}) .catch((e) => console.log(e)); default : return console.log(`${action.type} case not recognized`) } } À partir du cas de commutation ci-dessus, nous effectuons une requête POST à l'aide d'Axios vers UPLOAD_FUNCTION en transmettant le fichier ajouté à inclure dans le corps de la requête et nous avons également ajouté une image Content-Type dans l'en-tête de la requête.
Après un téléchargement réussi, la réponse renvoyée par la fonction cloud contient le document de données de l'utilisateur qui a été mis à jour pour contenir une URL valide de l'image téléchargée sur le stockage en nuage Google. Nous pouvons ensuite mettre à jour l'état de l'utilisateur pour contenir les nouvelles données, ce qui mettra également à jour l'élément src de l'image de profil de l'utilisateur dans le composant de profil.
Gestion des tâches Cron
Les tâches automatisées répétitives telles que l'envoi d'e-mails aux utilisateurs ou l'exécution d'une action interne à un moment précis sont la plupart du temps une fonctionnalité incluse dans les applications. Dans une application node.js normale, ces tâches peuvent être gérées comme des tâches cron à l'aide de node-cron ou node-schedule. Lors de la création d'applications sans serveur à l'aide de Google Cloud Platform, Cloud Scheduler est également conçu pour effectuer une opération cron.
Remarque : Bien que le Cloud Scheduler fonctionne de la même manière que l'utilitaire cron Unix pour créer des tâches qui seront exécutées ultérieurement, il est important de noter que le Cloud Scheduler n'exécute pas de commande comme le fait l'utilitaire cron. Au lieu de cela, il effectue une opération en utilisant une cible spécifiée.
Comme son nom l'indique, le Cloud Scheduler permet aux utilisateurs de programmer une opération à effectuer ultérieurement. Chaque opération est appelée une tâche et les tâches peuvent être visuellement créées, mises à jour et même détruites à partir de la section Planificateur de Cloud Console. Outre un champ de nom et de description, les tâches sur Cloud Scheduler comprennent les éléments suivants :
- La fréquence
Ceci est utilisé pour planifier l'exécution de la tâche Cron. Les planifications sont spécifiées à l'aide du format unix-cron qui est utilisé à l'origine lors de la création de tâches en arrière-plan sur la table cron dans un environnement Linux. Le format unix-cron consiste en une chaîne de cinq valeurs représentant chacune un point dans le temps. Ci-dessous, nous pouvons voir chacune des cinq chaînes et les valeurs qu'elles représentent.
- - - - - - - - - - - - - - - - minute ( - 59 ) | - - - - - - - - - - - - - hour ( 0 - 23 ) | | - - - - - - - - - - - - day of month ( 1 - 31 ) | | | - - - - - - - - - month ( 1 - 12 ) | | | | - - - - - -- day of week ( 0 - 6 ) | | | | | | | | | | | | | | | | | | | | | | | | | * * * * *L'outil générateur Crontab est pratique lorsque vous essayez de générer une valeur fréquence-temps pour un travail. Si vous avez du mal à assembler les valeurs de temps, le générateur Crontab a une liste déroulante visuelle où vous pouvez sélectionner les valeurs qui composent un calendrier et vous copiez la valeur générée et l'utilisez comme fréquence.
- Fuseau horaire
Le fuseau horaire à partir duquel la tâche cron est exécutée. En raison de la différence de temps entre les fuseaux horaires, les tâches cron exécutées avec différents fuseaux horaires spécifiés auront des heures d'exécution différentes. - Cible
C'est ce qui est utilisé dans l'exécution du Job spécifié. Une cible peut être un typeHTTPoù la tâche envoie une requête à l'heure spécifiée à l'URL ou à un sujet Pub/Sub sur lequel la tâche peut publier des messages ou en extraire des messages et enfin une application App Engine.
Le Cloud Scheduler se combine parfaitement avec les fonctions Cloud déclenchées par HTTP. Lorsqu'une tâche dans Cloud Scheduler est créée avec sa cible définie sur HTTP, cette tâche peut être utilisée pour exécuter une fonction cloud. Tout ce qui doit être fait est de spécifier le point de terminaison de la fonction cloud, de spécifier le verbe HTTP de la requête, puis d'ajouter toutes les données devant être transmises à la fonction dans le champ de corps affiché. Comme le montre l'exemple ci-dessous :
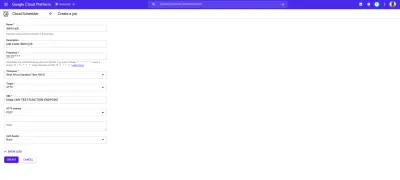
La tâche cron dans l'image ci-dessus s'exécutera tous les jours à 9 heures du matin en envoyant une requête POST à l'exemple de point de terminaison d'une fonction cloud.
Un cas d'utilisation plus réaliste d'une tâche cron consiste à envoyer des e-mails programmés aux utilisateurs à un intervalle donné à l'aide d'un service de messagerie externe tel que Mailgun. Pour voir cela en action, nous allons créer une nouvelle fonction cloud qui envoie un e-mail HTML à une adresse e-mail spécifiée en utilisant le package JavaScript nodemailer pour se connecter à Mailgun :
# index.js require("dotenv").config(); const nodemailer = require("nodemailer"); exports.Emailer = (req, res) => { let sender = process.env.SENDER; const { reciever, type } = req.body var transport = nodemailer.createTransport({ host: process.env.HOST, port: process.env.PORT, secure: false, auth: { user: process.env.SMTP_USERNAME, pass: process.env.SMTP_PASSWORD, }, }); if (!reciever) { res.status(400).send({ error: `Empty email address` }); } transport.verify(function (error, success) { if (error) { res .status(401) .send({ error: `failed to connect with stmp. check credentials` }); } }); switch (type) { case "statistics": return transport.sendMail( { from: sender, to: reciever, subject: "Your usage satistics of demo app", html: { path: "./welcome.html" }, }, (error, info) => { if (error) { res.status(401).send({ error : error }); } transport.close(); res.status(200).send({data : info}); } ); default: res.status(500).send({ error: "An available email template type has not been matched.", }); } };Using the cloud function above we can send an email to any user's email address specified as the receiver value in the request body. It performs the sending of emails through the following steps:
- It creates an SMTP transport for sending messages by passing the
host,userandpasswhich stands for password, all displayed on the user's Mailgun dashboard when a new account is created. - Next, it verifies if the SMTP transport has the credentials needed in order to establish a connection. If there's an error in establishing the connection, it ends the function's invocation and sends back a
401 unauthenticatedstatus code. - Next, it calls the
sendMailmethod to send the email containing the HTML file as the email's body to the receiver's email address specified in thetofield.
Note : We use a switch statement in the cloud function above to make it more reusable for sending several emails for different recipients. This way we can send different emails based on the type field included in the request body when calling this cloud function.
Now that there is a function that can send an email to a user; we are left with creating the cron job to invoke this cloud function. This time, the cron jobs are created dynamically each time a new user is created using the official Google cloud client library for the Cloud Scheduler from the initial firestoreFunction .
We expand the CREATE-USER case to create the job which sends the email to the created user at a one-day interval.
require("dotenv").config();cloc const { Firestore } = require("@google-cloud/firestore"); const scheduler = require("@google-cloud/scheduler") const cors = require("cors")({ origin: true }); const EMAILER = proccess.env.EMAILER_ENDPOINT const parent = ScheduleClient.locationPath( process.env.PROJECT_ID, process.env.LOCATION_ID ); exports.firestoreFunction = function (req, res) { return cors(req, res, () => { const { email, password, type } = req.body; const firestore = new Firestore(); const document = firestore.collection("users"); const client = new Scheduler.CloudSchedulerClient() if (!type) { res.status(422).send({ error : "An action type was not specified"}); } switch (type) { case "CREATE-USER":const job = { httpTarget: { uri: process.env.EMAIL_FUNCTION_ENDPOINT, httpMethod: "POST", body: { email: email, }, }, schedule: "*/30 */6 */5 10 4", timezone: "Africa/Lagos", }if (!email || !password) { res.status(422).send("email and password fields missing"); } return bcrypt.genSalt(10, (err, salt) => { bcrypt.hash(password, salt, (err, hash) => { document .add({ email: email, password: hash, }) .then((response) => {client.createJob({ parent : parent, job : job }).then(() => res.status(200).send(response)) .catch(e => console.log(`unable to create job : ${e}`) )}) .catch((e) => res.status(501).send(`error inserting data : ${e}`) ); }); }); default: res.status(422).send(`${type} is not a valid function action`) } }); };
From the snippet above, we can see the following:
- A connection to the Cloud Scheduler from the Scheduler constructor using the Application Default Credentials (ADC) is made.
- We create an object consisting of the following details which make up the cron job to be created:
-
uri
The endpoint of our email cloud function in which a request would be made to. -
body
This is the data containing the email address of the user to be included when the request is made. -
schedule
The unix cron format representing the time when this cron job is to be performed.
-
- After the promise from inserting the user's data document is resolved, we create the cron job by calling the
createJobmethod and passing in the job object and the parent. - The function's execution is ended with a
200status code after the promise from thecreateJoboperation has been resolved.
After the job is created, we'll see it listed on the scheduler page.
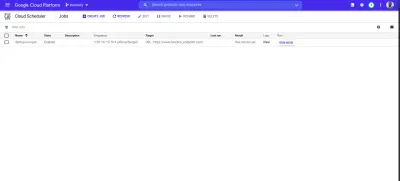
From the image above we can see the time scheduled for this job to be executed. We can decide to manually run this job or wait for it to be executed at the scheduled time.
Conclusion
Within this article, we have had a good look into serverless applications and the benefits of using them. We also had an extensive look at how developers can manage their serverless applications on the Google Cloud using Cloud Functions so you now know how the Google Cloud is supporting the use of serverless applications.
Within the next years to come, we will certainly see a large number of developers adapt to the use of serverless applications when building applications. If you are using cloud functions in a production environment, it is recommended that you read this article from a Google Cloud advocate on “6 Strategies For Scaling Your Serverless Applications”.
The source code of the created cloud functions are available within this Github repository and also the used front-end application within this Github repository. The front-end application has been deployed using Netlify and can be tested live here.
Les références
- Google Cloud
- Cloud Functions
- Cloud Source Repositories
- Cloud Scheduler overview
- Cloud Firestore
- “6 Strategies For Scaling Your Serverless Applications,” Preston Holmes