
テキストマイニングとは:テクニックとアプリケーション
公開: 2019-06-02テキストマイニングは、世界のデータの80%近くを形成する非構造化データを分析および処理するための最も重要な方法の1つです。 今日、大多数の組織や機関は大量のデータを収集してデータウェアハウスやクラウドプラットフォームに保存しています。このデータは、複数のソースから新しいデータが流入するにつれて、分単位で指数関数的に増加し続けます。
その結果、企業や組織にとって、従来のツールを使用して大量のテキストデータを保存、処理、分析することが課題になっています。 データサイエンスプログラムで自分自身をスキルアップすると、課題を克服するのに役立ちます。 テキストマイニングについてもっと話しましょう。
目次
テキストマイニングとは何ですか?
ウィキペディアによると、「テキストマイニングは、テキストデータマイニングとも呼ばれ、テキスト分析とほぼ同等であり、テキストから高品質の情報を取得するプロセスです。」 この定義は、テキストマイニングの主要なコードであり、非構造化データを掘り下げて、テキストデータソースの探索に必要な意味のあるパターンと洞察を抽出します。
テキストマイニングは、情報検索、データマイニング、機械学習、統計学、計算言語学のツールを組み込んで統合しているため、学際的な分野にほかなりません。 テキストマイニングは、半構造化または非構造化形式で保存された自然言語テキストを処理します。
データ分析をビジネス成果に結び付ける12の方法テキストマイニングに含まれる5つの基本的な手順は次のとおりです。
- いくつか例を挙げると、プレーンテキスト、Webページ、PDFファイル、電子メール、ブログなどの複数のデータソースから非構造化データを収集します。
- 前処理およびクレンジング操作を実行することにより、データから異常を検出して削除します。 データクレンジングを使用すると、データ内に隠された貴重な情報を抽出して保持し、特定の単語の語源を特定するのに役立ちます。
- このために、あなたは多くのテキストマイニングツールとテキストマイニングアプリケーションを手に入れます。
- 非構造化データから抽出されたすべての関連情報を構造化形式に変換します。
- 管理情報システム(MIS)を介してデータ内のパターンを分析します。
- すべての貴重な情報を安全なデータベースに保存して、傾向分析を推進し、組織の意思決定プロセスを強化します。
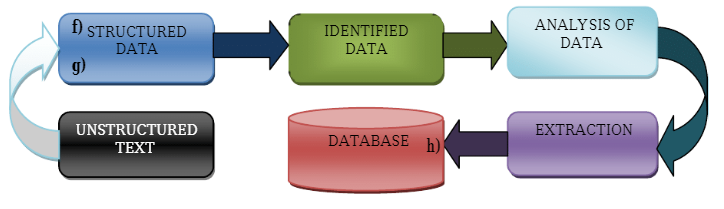
テキストマイニング技術
テキストマイニング技術は、テキストのマイニングとそこからの洞察の発見に入るプロセスで理解できます。 これらのテキストマイニング技術は、通常、実行にさまざまなテキストマイニングツールとアプリケーションを使用します。 それでは、さまざまなテキストマイニング手法を見てみましょう。
ここで、テキストマイニング手法で使用される最も有名な手法を見てみましょう。
1.情報抽出
これは最も有名なテキストマイニング手法です。 情報交換とは、膨大な量のテキストデータから意味のある情報を抽出するプロセスを指します。 このテキストマイニング手法は、半構造化または非構造化テキストからのエンティティ、属性、およびそれらの関係の抽出を識別することに焦点を当てています。 抽出された情報はすべて、将来のアクセスと取得のためにデータベースに保存されます。 結果の有効性と関連性は、適合率と再現率のプロセスを使用してチェックおよび評価されます。
2.情報検索
情報検索(IR)は、特定の単語またはフレーズのセットに基づいて、関連する関連パターンを抽出するプロセスを指します。 このテキストマイニング手法では、IRシステムはさまざまなアルゴリズムを使用して、ユーザーの行動を追跡および監視し、それに応じて関連データを検出します。 GoogleとYahooの検索エンジンは2つの最も有名なIRシステムです。
データサイエンスとは何ですか? データサイエンティストとは誰ですか? アナリティクスとは何ですか?3.分類
これは、「教師あり」学習の一形態であるテキストマイニング手法の1つであり、通常の言語のテキストが、その内容に応じて事前定義された一連のトピックに割り当てられます。 したがって、分類、つまり自然言語処理(NLP)は、テキストドキュメントを収集して処理および分析し、各ドキュメントの適切なトピックまたはインデックスを明らかにするプロセスです。 共参照方法は、テキストデータから関連する同義語と略語を抽出するためにNLPの一部として一般的に使用されます。 今日、NLPは、パーソナライズされたコマーシャルの配信から、スパムのフィルタリングや階層的な定義の下でのWebページの分類など、さまざまなコンテキストで使用される自動化されたプロセスになっています。
4.クラスタリング
クラスタリングは、最も重要なテキストマイニング手法の1つです。 これは、テキスト情報の固有の構造を識別し、さらに分析するためにそれらを関連するサブグループまたは「クラスター」に編成しようとします。 クラスタリングプロセスにおける重要な課題は、事前情報がなくても、ラベルのないテキストデータから意味のあるクラスターを形成することです。 クラスター分析は、データ配布を支援する、または検出されたクラスターで実行されている他のテキストマイニングアルゴリズムの前処理ステップとして機能する標準のテキストマイニングツールです。

5.要約
テキストの要約とは、エンドユーザーにとって価値のある情報を保持する特定のテキストの圧縮バージョンを自動的に生成するプロセスを指します。 このテキストマイニング手法の目的は、複数のテキストソースを参照して、元のドキュメントの全体的な意味と意図を本質的に同じに保ちながら、かなりの割合の情報を簡潔な形式で含むテキストの要約を作成することです。 テキスト要約は、決定木、ニューラルネットワーク、回帰モデル、群知能などのテキスト分類を採用するさまざまな方法を統合および組み合わせます。
「データサイエンティストになる方法」に答えました!
テキストマイニングのアプリケーション
テキストマイニング技術とテキストマイニングツールは、学界やヘルスケアから企業やソーシャルメディアプラットフォームに至るまで、業界に急速に浸透しています。 これにより、多くのテキストマイニングアプリケーションが生まれています。 今日、世界中で使用されているテキストマイニングアプリケーションをいくつか紹介します。
2019年の自然言語処理の5つのアプリケーション1.リスク管理
ビジネス部門の失敗の主な原因の1つは、適切または不十分なリスク分析の欠如です。 SAS Text Minerなどのテキストマイニングテクノロジーを利用したリスク管理ソフトウェアを採用および統合することで、企業はビジネス市場の現在のすべてのトレンドを常に把握し、潜在的なリスクを軽減する能力を高めることができます。 テキストマイニングツールとテクノロジーは、何千ものテキストデータソースから関連情報を収集し、抽出された洞察間のリンクを作成できるため、企業は適切な情報に適切なタイミングでアクセスでき、それによってリスク管理プロセス全体が強化されます。
2.カスタマーケアサービス
テキストマイニング技術、特にNLPは、カスタマーケアの分野でますます重要になっています。 企業はテキスト分析ソフトウェアに投資して、調査、顧客フィードバック、顧客からの電話などのさまざまなソースからのテキストデータにアクセスすることで、全体的な顧客体験を向上させています。テキスト分析は、企業の応答時間を短縮し、不満に対処することを目的としています。迅速かつ効率的に顧客の。
読む:インドのデータマイニングプロジェクト
3.不正の検出
テキストマイニング技術に裏打ちされたテキスト分析は、テキスト形式でデータの大部分を収集するドメインに多大な機会を提供します。 保険会社や金融会社はこの機会を利用しています。 テキスト分析の結果を関連する構造化データと組み合わせることにより、これらの企業は、請求を迅速に処理し、不正を検出して防止することができるようになりました。
4.ビジネスインテリジェンス
組織や企業は、ビジネスインテリジェンスの一部としてテキストマイニング技術を活用し始めています。 テキストマイニング技術は、顧客の行動や傾向に関する深い洞察を提供するだけでなく、企業がライバルの長所と短所を分析するのに役立ち、市場での競争上の優位性をもたらします。 Cogito Intelligence PlatformやIBMテキスト分析などのテキストマイニングツールは、マーケティング戦略のパフォーマンス、最新の顧客および市場の傾向などに関する洞察を提供します。
5.ソーシャルメディア分析
ソーシャルメディアプラットフォームのパフォーマンスを分析するためだけに設計された多くのテキストマイニングツールがあります。 これらは、ニュース、ブログ、電子メールなどからオンラインで生成されたテキストを追跡および解釈するのに役立ちます。さらに、テキストマイニングツールは、ソーシャルメディア上のブランドの投稿、いいね、フォロワーの数を効率的に分析できるため、あなたのブランドやオンラインコンテンツとやり取りしている人々の反応。 分析により、ターゲットオーディエンスにとって「何がホットで何がそうでないか」を理解することができます。
この有益な記事が、テキストマイニングの基本と業界でのそのアプリケーションを理解するのに役立つことを願っています。 データサイエンス技術について詳しく知りたい場合は、IIITバンガロアのデータサイエンスのエグゼクティブPGプログラムをご覧ください。
テキストマイニングの利点は何ですか?
テキストマイニングは、新しい情報を見つけたり、特定の研究質問への回答を支援したりするために、膨大な数のドキュメントを分析するプロセスです。 テキストマイニングは、テキストデータの海で失われるはずの事実、つながり、主張を明らかにします。 テキストマイニングは、電子メール、ニュース、およびブログによって作成されたテキストの追跡と解釈を支援することができます。 企業は、テキストマイニング技術を使用して、ブランドの認知度、投稿、いいね、フォロワーを評価できます。 これにより、組織は顧客がブランドやコンテンツにどのように反応するかを明確に把握できます。 基本的なテキストマイニングを簡単に実行できるオープンソースツールも多数あります。
テキストマイニングで最も重要な問題は何ですか?
テキストデータには、スペルの誤りや文型などの追加の問題があり、関連情報を抽出して分析することが困難になります。 テキストマイニングプロセス中に、ドメイン知識の統合、可変概念の粒度、多言語テキストの改良、自然言語処理のあいまいさなどの重要な問題と障害が発生します。 同義語と反意語はすべてテキストで使用されるため、両方を考慮したテキストマイニング手法で問題が発生します。 ドキュメントのコレクションが膨大で、同じドメイン内の複数の分野からのものである場合、それらを分類するのは難しい場合があります。
テキストマイニングツールを使用すると、どのように作業が簡単になりますか?
テキストマイニングテクノロジーは、組織が洞察を得てデータに基づいた選択を行うのを支援するために、調査の回答や電子メールからツイートや製品レビューに至るまで、さまざまな形式のテキストを分析するために使用されます。 良いニュースは、テキストマイニングの開始を支援するために利用できるいくつかのオンラインリソースとツールがあることです。 ただし、多くの組織は、テキストマイニングソフトウェアを作成するか取得するかの決定に直面しています。 コーディング方法を知っている場合は、オープンソースツールを使用して独自のテキストマイニングモデルを作成できます。 時間やリソースがない場合は、費用対効果が高く、正確で、信頼できるオンラインツールが多数あります。