
データサイエンスのR:データサイエンスにRを選択する必要があるのはなぜですか?
公開: 2020-04-28データサイエンスと統計計算の世界で強力な言語であるRは、学生の間でますます人気が高まっています。 1990年代の初めに開発された後、プログラミング言語のユーザーインターフェイスを改善するために尽力されてきました。
初歩的なテキストエディタからインタラクティブなRStudioになり、Jupyter Notebooksになるまでの道のりで、Rは世界のデータサイエンスコミュニティの関与を維持してきました。
しかし、Rを正しく学習しないと、イライラする可能性があります。 あなたはおそらく、言語との闘いを文書化した学生のレビューに精通しているでしょう。 途中で諦めた人もいれば、行き詰まりを感じて、もっと構造化されたアプローチを必死に探している人もいます。
あなたがこれらのカテゴリーに該当するか、または新入生であるかどうかにかかわらず、言語にはいくつかの固有の問題があることを知って安心するかもしれません。 それで、あなたがそれが難しいと思うならば、あなた自身に厳しいことをやめなさい。 通常、あなたのモチベーションの源とあなたが学んでいることの間には明らかなミスマッチがあります。
彼らはこれらのかなり退屈な活動を愛しているので、誰もドライプラクティスの問題やコーディング構文に従事することを望んでいません。 絶対違う! 人々は、構文をマスターするこの長くて骨の折れるプロセスに耐えたいと思っています。なぜなら、それは彼らが良いものに卒業することを可能にするからです。 ただし、それを使って何かを実行できるようにするためにカバーしなければならない複雑で長いトピックの山は、苦痛を伴う可能性があります。
そして、あなたがあなたの目標を達成するためのより自然な方法があるかどうかを知るためにここに到着したなら、あなたはあなたがいるべき場所にいます。
Rを学び、学ぶ価値があると私に信じさせる、より構造化された方法があります! 興味のある人にとっては、他のプログラミング言語よりもRを学ぶことにはいくつかの明確な利点があります。 最も重要なことは、データサイエンスの日常のタスクは、Rの整然としたエコシステムを使用して簡単に実行できることです。Rプログラミング言語でのデータの視覚化は、シンプルかつ強力です。 また、最もフレンドリーで包括的なオンラインコミュニティの1つがあり、非常に役立ちます。
Rを学びたい場合は、何を扱っているのかを明確にし、全体像を包括的に把握する必要があります。 それがまさに私たちがここで行うことです。 初心者にとっては、Rの意味と、なぜRを学ぶのかという基本から始めて、Rに関して多くの疑問を抱くことが予想されます。 データ分析、データ操作、機械学習のより複雑な領域にそれを。 Rを学ぶ正しい方法に向けてガイドしながら、側面に1つずつ取り組んでいきましょう。
目次
Rとは何ですか?
R Foundationは、rを「統計計算とグラフィックスのための言語と環境」と表現しています。 それは、Rが明らかにそれよりもはるかに大きいため、非常に簡単に言えます。
以下は、プログラミング言語としてのRの決定的な特徴となった特性のリストです。
- データ分析ソフトウェア:データを理解したい人のために、Rはデータの視覚化、統計分析、および予測モデリングに使用できます。
- プログラミング言語:Rは、データの探索、視覚化、およびモデル化を可能にする演算子、関数、およびオブジェクトを提供するオブジェクト指向言語です。
- オープンソースソフトウェアプロジェクト:無料ですが、Rの数値精度と品質基準は非常に高いです。 言語のオープンインターフェイスにより、他のシステムやアプリケーションとの統合が容易になります。
- 統計分析環境:Rは、予測モデリングと統計で最も最先端の研究が行われる場所です。 これが、Rが到着後に新しく開発された技術を提供する最初のプラットフォームであることが多い理由です。 標準的な統計手法でも、Rでの実装は非常に簡単です。
- コミュニティ:大規模なオンラインコミュニティでは、Rには約200万人のユーザーがいます! Rプロジェクトのリーダーシップに一流のコンピューター科学者や統計家が含まれていることは驚くべきことではありません。
読む:初心者のためのRチュートリアル
なぜあなたはRを学ぶべきですか?
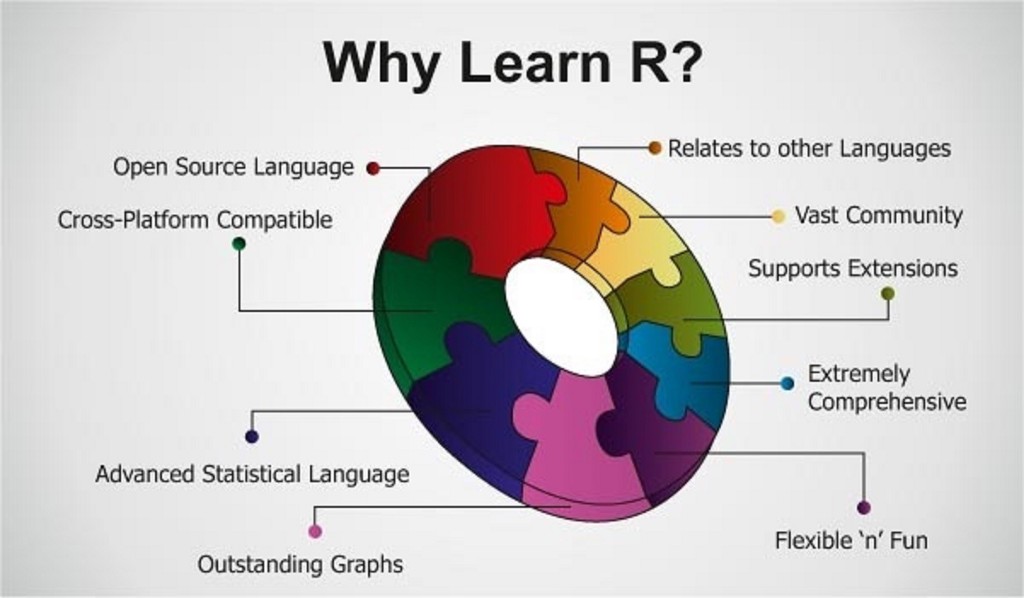
データサイエンスを学ぶにはPythonまたはRを学ぶ必要があるというのが一般的な信念です。ほとんどの人がRを選択する理由は、他のプログラミング言語に比べて明らかな利点があるためです。
ソース
- Rには簡単なコーディングスタイルがあります。
- オープンソースであるため、サブスクリプション料金や追加料金の支払いについて心配する必要はありません。
- さまざまな計算タスク用に7800を超えるカスタマイズされたパッケージに即座にアクセスできます。
- ヘルプが必要な場合は、圧倒的なコミュニティサポートと多数のフォーラムがあります。
- これは、他のいくつかのプラットフォームでしか提供できない高性能コンピューティング体験を約束します。
- 世界中のほとんどのデータサイエンス企業と分析は、Rを従業員の貴重なスキルと見なしています。
Rを学ぶ動機は何ですか?
Rを始める前に、少なくとも自分がRをやりたい理由を明確にすることが重要です。 あなたのモチベーションが何であるか、そしてあなたがこの旅からどのような期待を持っているかを知ることは興味深いでしょう。 信じられないかもしれませんが、この演習は、状況が厳しくなり、この場合は退屈な場合でも、必要なアンカーとして機能する可能性があります。 使用するデータの種類と構築するプロジェクトの種類を確認します。
言語を分析しますか? コンピュータビジョン? 株式市場を予測しますか? スポーツ統計を扱いますか? データサイエンスの将来の範囲はどのように見えますか? お気づきかもしれませんが、これらの側面では、単に「データサイエンティストであること」よりも少し深く掘り下げる必要があります。 データサイエンティストとしてやりたいことほど、データサイエンティストになることではありません。
あなたの最終目標を定義することはあなたの道を築く上で非常に重要です。 自分がその知識で何をしようとしているのかをすでに知っている場合、必要のないものに気を取られる可能性は低いです。 あなたはあなたの目標とその過程で重要な側面に集中し続けることができ、あなた自身で不必要なものから必要なものを取り除くことができます。
Rで基本を学ぶ
これをスキップする学習Rはありません。 最初のタスクは、コーディング環境に慣れることです。
RStudioインターフェース
最初の領域は、実行されたコードの出力を表示するRコンソールです。 次はRスクリプトです。 これは、コードを入力する必要があるスペースです。 次はR環境です。 これは、外部要素の追加セットを示しています。 これには、データセット、関数、ベクトル、変数などが含まれます。 最後はグラフィカル出力です。 これらのグラフは、探索的データ分析の結果です。
基本的な計算
いくつかの簡単な計算から始めるのが最善です。 Rコンソールをインタラクティブな計算機として使用することもできます。 さまざまな計算を組み合わせて実験を実行し、それらの結果を一致させることができます。 先に進むと、以前の計算にアクセスすることもできます。
Rコンソールをクリックした後に上下の矢印を押すと、以前に実行されたコマンドをアクティブ化することにより、以前の計算に移動します。 ただし、計算が多すぎる場合は、変数を作成するだけで済みます。 ただし、これらの変数は英数字またはアルファベットのみである必要があり、数値ではないことに注意してください。
プログラミングエッセンシャル
プログラミング言語の構成要素と考えると、これを上手く習得すればするほど、デバッグで直面する問題は少なくなります。 Rのオブジェクトの5つのアトミッククラスまたは基本クラスは、文字、整数または整数、数値または実数、複素数および論理(trueまたはfalse)です。 これらのオブジェクトは、ディメンション、ディメンション、長さ、クラスの名前や名前など、さまざまな属性を持つことができます。

また読む: Rインタビューの質問と回答
データ型
Rのさまざまなデータ型には、ベクトル(整数、数値など)、データフレーム、リスト、および行列が含まれます。 ベクトルは、このプログラミング言語の最も基本的なオブジェクトです。 空のベクトルを作成するには、vector()を使用する必要があります。 ベクターは同じクラスのオブジェクトで構成されます。 異なるクラスのオブジェクトを混合してベクトルを作成することもできます。
その結果、さまざまなタイプのオブジェクトが1つのクラスに変換されます。 リストは、特殊なタイプのベクトルに使用される用語です。 このリストには、さまざまなデータ型の要素が含まれています。 マトリックスは、ディメンション属性を持つ、つまり行と列で導入されるベクトルの名前です。 データ型のファミリー。 ただし、データフレームが最も一般的に使用されます。 これは、表形式のデータを格納するためです。
制御構造
制御構造は、関数内に含まれるコマンドまたはコードのフローを監視するために使用されます。 関数は、反復的なコーディングタスクを自動化するために作成されたコマンドセットです。 学生はこのセクションを理解するのが難しいと感じることがよくあります。 幸い、Rには、これらの制御構造によって実行されるタスクを補完する多くのパッケージがあります。
便利なパッケージ
7800以上のパッケージの中には、他のパッケージよりも必要なものが確かにあります。 あなたがそれらを知っているとき、データサイエンスでの生活ははるかに簡単です。 データリーダーのインポートに使用できる多くのパッケージの中で、jsonlite、data.table、sqldf、およびRMySQLの方が便利です。 データの視覚化に関しては、 ggplot2は高度なグラフィックスに最適です。
Rは本当に素晴らしいデータ操作パッケージのコレクションを誇っており、例外的なもののいくつかはplyr、stringr、lubridate、dplyr 、 tidyrです。 これで、機械学習モデルを作成するために必要なすべてのものを、 caretが提供できるようになりました。 ただし、gbm、rpart、randomForestなどのアルゴリズムでパッケージをインストールすることもできます。
データ探索とデータ操作に精通する
これは、予測モデリングのさまざまな段階を深く掘り下げるセクションです。 ディープダイビングでは、このセクションを非常によく理解することに注意を払う必要があります。 優れた正確な実用的なモデルを構築する方法を学ぶ唯一の方法は、データを最初から最後まで探索することです。
データ探索に続くデータ操作の基盤を形成するのはこの段階です。 データ操作は、より高度なレベルでのデータ探索です。 このセクションでは、特徴エンジニアリング、ラベルエンコーディング、および1つのホットエンコーディングについて説明します。
また学ぶ:データサイエンスのためのPython対R
予測モデリングと機械学習を学ぶ
主に初心者向けに、機械学習はデータサイエンスを定義します。 ここでトピックを扱い、R、回帰、ランダムフォレストの決定木が含まれます。 この部分では、回帰に非常に深く対処する必要があるため、基本を明確にしてください。
線形回帰または重回帰、ロジスティック回帰、および関連する概念に出くわします。 デシジョンツリーは、ツリーのように配置された決定および結果モデルの用語です。 これは、ユーティリティ、イベントの結果、およびリソースコストを含む意思決定支援ツールです。 ランダムフォレストはランダムデシジョンフォレストとも呼ばれ、複数のデシジョンツリーによって作成されます。
構造化プロジェクトに進みます
これらの幅広いカテゴリに含まれる必要な知識を身に付けたら、構造化されたプロジェクトに進むことができます。 それはおそらく芸術を習得する唯一の方法です。 知識を応用すると、外出先で実際的な問題やデバイスの解決策に遭遇するにつれて、経験が広がります。 これは、現場での実務経験に関して将来の雇用主に提示できるポートフォリオを構築するのにも役立ちます。
次々とハードルに直面するときに、この段階でイライラすることは珍しくありません。 それはあなたが自分で準備している部分であり、これがあなたがこれまでにしたすべてよりも難しいように思われるとしても驚かないでください。 これは通常、候補者が自分の興奮をコントロールして課題に取り組み、多くの場合、独自のプロジェクトに飛び込むことができないために発生します。 正直なところ、この段階では、そのような準備ができていない可能性があります。慣れ親しんだ、より構造化されたプロジェクトに固執するのが最善です。
プロジェクトを構築し、学習を続ける
慣れ親しんだ領域に含まれるいくつかの構造化されたプロジェクトで作業した後、未知の領域に挑戦することができます。 専門知識は練習によってのみもたらされます。そして、あなたが快適な要素で練習したら、それは快適ゾーンを超えて移動する時であるという考えです。 それはあなたがどれだけ学んだかをテストする場所です。 この経験は、あなたがどこまで来たかを示すだけでなく、あなたの長所と短所も明らかにします。
興味深いデータサイエンスプロジェクトに取り組むと、まだ苦労していて、焦点を当てる必要のある分野がどれであるかがわかります。 ガイダンスのためにリソースを参照し、メンターやフィールドエキスパートの助けを求めることは、新しい方法、アプローチ、およびテクニックの知識を増やすだけです。 これは、実用的で理論的な知識を取得してから熟練したデータサイエンティストになるまでの道のりを通して、upGradの恩恵を受ける場所です。
したがって、行き詰まった場合、あなたがしなければならないのは手を差し伸べることだけです。 独自のデータサイエンスプロジェクトに取り組むと、まだ苦労していて、焦点を当てる必要のある分野がどれであるかがわかります。 ガイダンスのためにリソースを参照し、メンターやフィールドエキスパートの助けを求めることは、新しい方法、アプローチ、およびテクニックの知識を増やすだけです。
実践的および理論的な知識を取得してから熟練したデータサイエンティストになるまでの道のりをご覧いただけるため、upGradのメリットを享受できます。 したがって、行き詰まった場合、あなたがしなければならないのは手を差し伸べることだけです。
結論
通常、Rでは、新しいプロジェクトでの作業を学ぶことは、多くの場合、新しいパッケージの使用法を学ぶことを意味します。これは、ほとんどの場合、実行している種類の作業専用のパッケージがあるためです。 これはあなたが経験から得た知識であり、最終的にはあなたを専門家にします。 最初に解決を求められた好みに基づいて、作業したいプロジェクトを選択できます。
プログラミング言語で成功する秘訣は学習をやめることではないため、進歩するにつれて難易度を上げていきます。 話し言葉と同じように、流暢で快適な場所にたどり着くことができますが、それでも学ぶべきことがたくさんあります。
世界のトップ大学からデータサイエンスコースを学びましょう。 エグゼクティブPGプログラム、高度な証明書プログラム、または修士プログラムを取得して、キャリアを早急に進めましょう。
Rがデータサイエンスに適していると考えられるのはなぜですか?
Rは、利用可能な情報を分析、処理、変換、および視覚化するための環境をユーザーに提供するため、データサイエンスに非常に好まれるプログラミング言語です。 R言語は、統計モデリングの広範なサポートも提供します。
以前は、Rは学術目的でのみ使用されていましたが、生物学、天文学などのさまざまな形式の分野で役立つパッケージの海のために、業界でも広く使用されるようになりました。 それ以外に、Rは、画像処理用のさまざまなパッケージとともに、機械学習アルゴリズムと予測モデルの開発のための高度なデータ分析のオプションも豊富に提供しています。 これが、Rがデータサイエンティストによって好まれる選択であると考えられている理由です。
RとPythonの主な違いは何ですか?
RとPythonはどちらも、データサイエンスで非常に役立つと考えられています。 Pythonはデータサイエンスでより一般的なアプローチを提供しますが、Rは通常統計分析に使用されます。 一方では、Rの主な目的は統計とデータ分析ですが、Pythonの主な作業は本番環境とデプロイです。
Pythonは、そのライブラリと単純な構文のために非常にシンプルで習得が容易ですが、Rは最初は難しいでしょう。 Rプログラミング言語のユーザーは通常、R&Dの専門家や学者ですが、Pythonのユーザーは開発者やプログラマーです。
RとPythonのどちらが習得しやすいですか?
RとPythonはどちらも、プログラミング言語に関しては非常に簡単に習得できると考えられています。 JavaとC++の概念に精通している場合は、Pythonに簡単に適応できますが、数学と統計の側面に精通している場合は、Rの方が少し簡単に習得できます。
一般に、Pythonは構文が読みやすいため、習得と適応が少し簡単であると言えます。