
การประมวลผลข้อมูลล่วงหน้าในการเรียนรู้ของเครื่อง: 7 ขั้นตอนง่ายๆ ในการปฏิบัติตาม
เผยแพร่แล้ว: 2021-07-15การประมวลผลข้อมูลล่วงหน้าในการเรียนรู้ของเครื่องเป็นขั้นตอนสำคัญที่ช่วยปรับปรุงคุณภาพของข้อมูลเพื่อส่งเสริมการดึงข้อมูลเชิงลึกที่มีความหมายออกจากข้อมูล การประมวลผลข้อมูลล่วงหน้าในแมชชีนเลิร์นนิงหมายถึงเทคนิคในการเตรียม (ทำความสะอาดและจัดระเบียบ) ข้อมูลดิบเพื่อให้เหมาะสำหรับการสร้างและฝึกอบรมโมเดลแมชชีนเลิร์นนิง พูดง่ายๆ ก็คือ การประมวลผลข้อมูลล่วงหน้าใน Machine Learning เป็นเทคนิคการทำเหมืองข้อมูลที่แปลงข้อมูลดิบให้อยู่ในรูปแบบที่เข้าใจและอ่านได้
สารบัญ
ทำไมต้องประมวลผลข้อมูลล่วงหน้าในการเรียนรู้ของเครื่อง
เมื่อพูดถึงการสร้างโมเดล Machine Learning การประมวลผลข้อมูลล่วงหน้าเป็นขั้นตอนแรกที่บ่งบอกถึงการเริ่มต้นกระบวนการ โดยปกติ ข้อมูลในโลกแห่งความเป็นจริงจะไม่สมบูรณ์ ไม่สอดคล้องกัน ไม่ถูกต้อง (มีข้อผิดพลาดหรือค่าผิดปกติ) และมักขาดค่า/แนวโน้มของแอตทริบิวต์ที่เฉพาะเจาะจง นี่คือจุดที่การประมวลผลข้อมูลล่วงหน้าเข้าสู่สถานการณ์จำลอง ซึ่งช่วยในการล้าง จัดรูปแบบ และจัดระเบียบข้อมูลดิบ ซึ่งจะทำให้พร้อมใช้งานสำหรับโมเดล Machine Learning มาสำรวจขั้นตอนต่างๆ ของการประมวลผลข้อมูลล่วงหน้าในการเรียนรู้ของเครื่อง
เข้าร่วม หลักสูตรปัญญาประดิษฐ์ ออนไลน์จากมหาวิทยาลัยชั้นนำของโลก – ปริญญาโท โปรแกรม Executive Post Graduate และหลักสูตรประกาศนียบัตรขั้นสูงใน ML & AI เพื่อติดตามอาชีพของคุณอย่างรวดเร็ว
ขั้นตอนในการประมวลผลข้อมูลล่วงหน้าในการเรียนรู้ของเครื่อง
มีเจ็ดขั้นตอนที่สำคัญในการประมวลผลข้อมูลล่วงหน้าในการเรียนรู้ของเครื่อง:
1. รับชุดข้อมูล
การรับชุดข้อมูลเป็นขั้นตอนแรกในการประมวลผลข้อมูลล่วงหน้าในการเรียนรู้ของเครื่อง ในการสร้างและพัฒนาโมเดล Machine Learning คุณต้องได้รับชุดข้อมูลที่เกี่ยวข้องก่อน ชุดข้อมูลนี้จะประกอบด้วยข้อมูลที่รวบรวมจากแหล่งที่มาหลายแห่งและแตกต่างกัน ซึ่งรวมเข้าด้วยกันในรูปแบบที่เหมาะสมเพื่อสร้างชุดข้อมูล รูปแบบชุดข้อมูลแตกต่างกันไปตามกรณีการใช้งาน ตัวอย่างเช่น ชุดข้อมูลธุรกิจจะแตกต่างจากชุดข้อมูลทางการแพทย์อย่างสิ้นเชิง แม้ว่าชุดข้อมูลธุรกิจจะประกอบด้วยข้อมูลอุตสาหกรรมและธุรกิจที่เกี่ยวข้อง ชุดข้อมูลทางการแพทย์จะรวมข้อมูลที่เกี่ยวข้องกับการดูแลสุขภาพ
มีแหล่งข้อมูลออนไลน์หลายแห่งที่คุณสามารถดาวน์โหลดชุดข้อมูล เช่น https://www.kaggle.com/uciml/datasets และ https://archive.ics.uci.edu/ml/index.php คุณยังสร้างชุดข้อมูลได้โดยรวบรวมข้อมูลผ่าน Python API ต่างๆ เมื่อชุดข้อมูลพร้อมแล้ว คุณต้องใส่ไว้ในรูปแบบไฟล์ CSV หรือ HTML หรือ XLSX

2. นำเข้าห้องสมุดที่สำคัญทั้งหมด
เนื่องจาก Python เป็นไลบรารี่ที่มีการใช้งานอย่างกว้างขวางและเป็นที่ต้องการมากที่สุดโดย Data Scientists ทั่วโลก เราจะแสดงวิธีนำเข้าไลบรารี Python สำหรับการประมวลผลข้อมูลล่วงหน้าใน Machine Learning อ่านเพิ่มเติมเกี่ยวกับไลบรารี Python สำหรับ Data Science ที่นี่ ไลบรารี Python ที่กำหนดไว้ล่วงหน้าสามารถดำเนินการประมวลผลข้อมูลล่วงหน้าได้ การนำเข้าไลบรารีที่สำคัญทั้งหมดเป็นขั้นตอนที่สองในการประมวลผลข้อมูลล่วงหน้าในการเรียนรู้ของเครื่อง ไลบรารี Python หลักสามตัวที่ใช้สำหรับการประมวลผลข้อมูลล่วงหน้าใน Machine Learning ได้แก่:
- NumPy – NumPy เป็นแพ็คเกจพื้นฐานสำหรับการคำนวณทางวิทยาศาสตร์ใน Python ดังนั้นจึงใช้สำหรับการแทรกการดำเนินการทางคณิตศาสตร์ประเภทใดก็ได้ในโค้ด เมื่อใช้ NumPy คุณสามารถเพิ่มอาร์เรย์และเมทริกซ์หลายมิติขนาดใหญ่ในโค้ดของคุณได้
- Pandas – Pandas เป็นไลบรารี Python โอเพ่นซอร์สที่ยอดเยี่ยมสำหรับการจัดการและวิเคราะห์ข้อมูล มีการใช้อย่างกว้างขวางสำหรับการนำเข้าและจัดการชุดข้อมูล ประกอบด้วยโครงสร้างข้อมูลประสิทธิภาพสูง ใช้งานง่าย และเครื่องมือวิเคราะห์ข้อมูลสำหรับ Python
- Matplotlib – Matplotlib เป็นไลบรารีการพล็อต Python 2D ที่ใช้ในการพล็อตแผนภูมิประเภทใดก็ได้ใน Python มันสามารถส่งมอบตัวเลขคุณภาพสิ่งพิมพ์ในรูปแบบเอกสารจำนวนมากและสภาพแวดล้อมแบบโต้ตอบข้ามแพลตฟอร์ม (เชลล์ IPython, โน้ตบุ๊ก Jupyter, เว็บแอปพลิเคชันเซิร์ฟเวอร์ ฯลฯ)
อ่าน : แนวคิดโครงการการเรียนรู้ของเครื่องสำหรับผู้เริ่มต้น
3. นำเข้าชุดข้อมูล
ในขั้นตอนนี้ คุณต้องนำเข้าชุดข้อมูลที่คุณได้รวบรวมไว้สำหรับโครงการ ML ในมือ การนำเข้าชุดข้อมูลเป็นหนึ่งในขั้นตอนสำคัญในการประมวลผลข้อมูลล่วงหน้าในการเรียนรู้ของเครื่อง อย่างไรก็ตาม ก่อนที่คุณจะสามารถนำเข้าชุดข้อมูล คุณต้องตั้งค่าไดเร็กทอรีปัจจุบันเป็นไดเร็กทอรีการทำงาน คุณสามารถตั้งค่าไดเร็กทอรีการทำงานใน Spyder IDE ได้ในสามขั้นตอนง่ายๆ:
- บันทึกไฟล์ Python ของคุณในไดเร็กทอรีที่มีชุดข้อมูล
- ไปที่ตัวเลือก File Explorer ใน Spyder IDE และเลือกไดเร็กทอรีที่ต้องการ
- ตอนนี้ให้คลิกที่ปุ่ม F5 หรือตัวเลือก Run เพื่อรันไฟล์
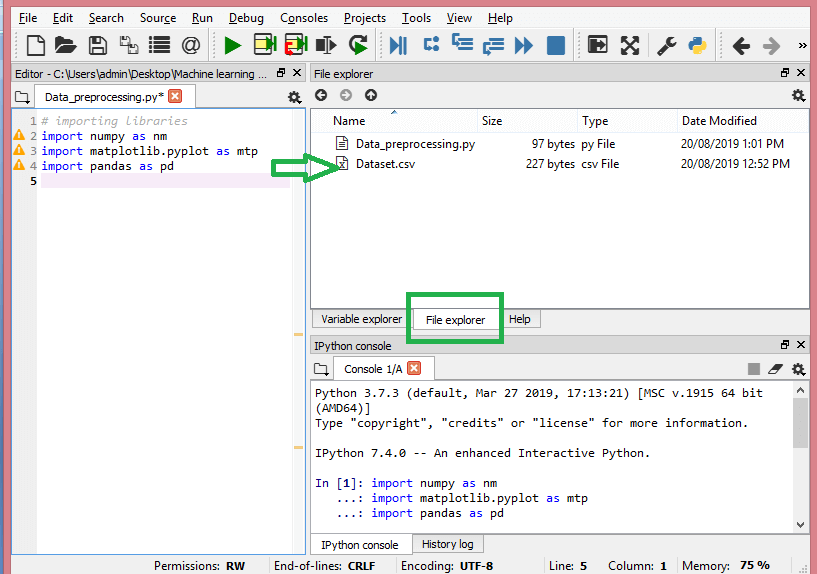
แหล่งที่มา
นี่คือลักษณะของไดเร็กทอรีการทำงาน
เมื่อคุณตั้งค่าไดเร็กทอรีการทำงานที่มีชุดข้อมูลที่เกี่ยวข้องแล้ว คุณสามารถนำเข้าชุดข้อมูลโดยใช้ฟังก์ชัน “read_csv()” ของไลบรารี Pandas ฟังก์ชันนี้สามารถอ่านไฟล์ CSV (ทั้งภายในเครื่องหรือผ่าน URL) และดำเนินการต่างๆ กับไฟล์ได้ read_csv() เขียนเป็น:
data_set= pd.read_csv('Dataset.csv')
ในโค้ดบรรทัดนี้ “data_set” หมายถึงชื่อของตัวแปรที่คุณจัดเก็บชุดข้อมูล ฟังก์ชันนี้มีชื่อของชุดข้อมูลด้วย เมื่อคุณรันโค้ดนี้ ชุดข้อมูลจะถูกนำเข้าสำเร็จ
ระหว่างกระบวนการนำเข้าชุดข้อมูล มีสิ่งสำคัญอีกอย่างที่คุณต้องทำ นั่นคือการแยกตัวแปรตามและตัวแปรอิสระ สำหรับทุกโมเดล Machine Learning จำเป็นต้องแยกตัวแปรอิสระ (เมทริกซ์ของคุณสมบัติ) และตัวแปรตามในชุดข้อมูล
พิจารณาชุดข้อมูลนี้:

แหล่งที่มา
ชุดข้อมูลนี้ประกอบด้วยตัวแปรอิสระสามตัว ได้แก่ ประเทศ อายุ และเงินเดือน และตัวแปรตามหนึ่งตัวแปรที่ซื้อ
จะแยกตัวแปรอิสระได้อย่างไร?
ในการแยกตัวแปรอิสระ คุณสามารถใช้ฟังก์ชัน “iloc[ ]” ของไลบรารี Pandas ฟังก์ชันนี้สามารถแยกแถวและคอลัมน์ที่เลือกจากชุดข้อมูล
x= data_set.iloc[:,:-1].values
ในบรรทัดของโค้ดด้านบน โคลอนแรก (:) จะพิจารณาแถวทั้งหมด และโคลอนที่สอง (:) จะพิจารณาทุกคอลัมน์ รหัสประกอบด้วย “:-1” เนื่องจากคุณต้องละเว้นคอลัมน์สุดท้ายที่มีตัวแปรตาม โดยการรันโค้ดนี้ คุณจะได้เมทริกซ์ของฟีเจอร์ต่างๆ แบบนี้ –
[['อินเดีย' 38.0 68000.0]
['ฝรั่งเศส' 43.0 45000.0]
['เยอรมนี' 30.0 54000.0]
['ฝรั่งเศส' 48.0 65000.0]
['เยอรมนี' 40.0 น่าน]
['อินเดีย' 35.0 58000.0]
['เยอรมนี' น่าน 53000.0]
['ฝรั่งเศส' 49.0 79000.0]
['อินเดีย' 50.0 88000.0]
['ฝรั่งเศส' 37.0 77000.0]]
จะแยกตัวแปรตามได้อย่างไร?
คุณสามารถใช้ฟังก์ชัน “iloc[ ]” เพื่อแยกตัวแปรตามเช่นกัน นี่คือวิธีที่คุณเขียน:
y= data_set.iloc[:,3].values
โค้ดบรรทัดนี้พิจารณาทุกแถวที่มีคอลัมน์สุดท้ายเท่านั้น เมื่อรันโค้ดข้างต้น คุณจะได้อาร์เรย์ของตัวแปรตาม เช่น –
array(['ไม่', 'ใช่', 'ไม่', 'ไม่', 'ใช่', 'ใช่', 'ไม่', 'ใช่', 'ไม่', 'ใช่'],
dtype=วัตถุ)
4. การระบุและการจัดการกับค่าที่หายไป
ในการประมวลผลข้อมูลล่วงหน้า การระบุและจัดการค่าที่ขาดหายไปอย่างถูกต้องเป็นสิ่งสำคัญ หากไม่สามารถทำได้ คุณอาจได้ข้อสรุปและการอนุมานที่ไม่ถูกต้องและผิดพลาดจากข้อมูล จำเป็นต้องพูด สิ่งนี้จะขัดขวางโครงการ ML ของคุณ
โดยทั่วไป มีสองวิธีในการจัดการข้อมูลที่ขาดหายไป:
- การลบแถวเฉพาะ – ในวิธีนี้ คุณจะลบแถวเฉพาะที่มีค่า Null สำหรับคุณลักษณะหรือคอลัมน์เฉพาะโดยที่ค่าหายไปมากกว่า 75% อย่างไรก็ตาม วิธีนี้ไม่ได้ผล 100% และขอแนะนำให้ใช้เมื่อชุดข้อมูลมีตัวอย่างเพียงพอเท่านั้น คุณต้องตรวจสอบให้แน่ใจว่าหลังจากลบข้อมูลแล้ว จะไม่มีอคติเพิ่มเติม
- การคำนวณค่าเฉลี่ย – วิธีนี้มีประโยชน์สำหรับสถานที่ที่มีข้อมูลตัวเลข เช่น อายุ เงินเดือน ปี ฯลฯ ที่นี่ คุณสามารถคำนวณค่าเฉลี่ย ค่ามัธยฐาน หรือโหมดของจุดสนใจหรือคอลัมน์หรือแถวเฉพาะที่มีค่าขาดหายไปและแทนที่ ผลลัพธ์สำหรับค่าที่หายไป วิธีนี้สามารถเพิ่มความแปรปรวนให้กับชุดข้อมูล และการสูญหายของข้อมูลสามารถลบล้างได้อย่างมีประสิทธิภาพ ดังนั้นจึงให้ผลลัพธ์ที่ดีกว่าเมื่อเปรียบเทียบกับวิธีแรก (ละเว้นแถว/คอลัมน์) อีกวิธีหนึ่งในการประมาณคือผ่านการเบี่ยงเบนของค่าที่อยู่ใกล้เคียง อย่างไรก็ตาม วิธีนี้จะได้ผลดีที่สุดสำหรับข้อมูลเชิงเส้น
อ่าน: แอปพลิเคชันของแอปพลิเคชันการเรียนรู้ของเครื่องโดยใช้ Cloud
5. การเข้ารหัสข้อมูลหมวดหมู่
ข้อมูลตามหมวดหมู่หมายถึงข้อมูลที่มีหมวดหมู่เฉพาะภายในชุดข้อมูล ในชุดข้อมูลที่อ้างถึงข้างต้น มีตัวแปรตามหมวดหมู่สองแบบคือ ประเทศ และที่ซื้อ
โมเดลแมชชีนเลิร์นนิงนั้นใช้สมการทางคณิตศาสตร์เป็นหลัก ดังนั้น คุณสามารถเข้าใจโดยสัญชาตญาณว่าการเก็บข้อมูลตามหมวดหมู่ไว้ในสมการจะทำให้เกิดปัญหาบางอย่าง เนื่องจากคุณต้องการแค่ตัวเลขในสมการเท่านั้น
จะเข้ารหัสตัวแปรประเทศได้อย่างไร?
ดังที่เห็นในตัวอย่างชุดข้อมูลของเรา คอลัมน์ประเทศจะทำให้เกิดปัญหา ดังนั้นคุณต้องแปลงเป็นค่าตัวเลข ในการดำเนินการดังกล่าว คุณสามารถใช้คลาส LabelEncoder() จากไลบรารี sci-kit learn รหัสจะเป็นดังนี้ -
#ข้อมูลหมวดหมู่
#สำหรับตัวแปรประเทศ
จาก sklearn.preprocessing นำเข้า LabelEncoder
label_encoder_x= LabelEncoder()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
และผลลัพธ์จะเป็น -
ออก[15]:
อาร์เรย์ ([[2, 38.0, 68000.0],
[0, 43.0, 45000.0],
[1, 30.0, 54000.0],
[0, 48.0, 65000.0],
[1, 40.0, 65222.22222222222],
[2, 35.0, 58000.0],
[1, 41.111111111111114, 53000.0],
[0, 49.0, 79000.0],
[2, 50.0, 88000.0],
[0, 37.0, 77000.0]], dtype=object)
ที่นี่เราจะเห็นว่าคลาส LabelEncoder ได้เข้ารหัสตัวแปรเป็นตัวเลขได้สำเร็จ อย่างไรก็ตาม มีตัวแปรประเทศที่เข้ารหัสเป็น 0, 1 และ 2 ในผลลัพธ์ที่แสดงด้านบน ดังนั้น โมเดล ML อาจถือว่ามีความสัมพันธ์กันระหว่างตัวแปรทั้งสาม ดังนั้นจึงสร้างเอาต์พุตที่ผิดพลาด เพื่อขจัดปัญหานี้ ตอนนี้เราจะใช้ Dummy Encoding
ตัวแปรจำลองคือตัวแปรที่ใช้ค่า 0 หรือ 1 เพื่อบ่งชี้ว่าไม่มีอยู่หรือมีเอฟเฟกต์หมวดหมู่เฉพาะที่สามารถเปลี่ยนแปลงผลลัพธ์ได้ ในกรณีนี้ ค่า 1 บ่งชี้การมีอยู่ของตัวแปรนั้นในคอลัมน์หนึ่งๆ ในขณะที่ตัวแปรอื่นๆ จะกลายเป็นค่า 0 ในการเข้ารหัสจำลอง จำนวนคอลัมน์จะเท่ากับจำนวนหมวดหมู่
เนื่องจากชุดข้อมูลของเรามีสามหมวดหมู่ มันจะสร้างคอลัมน์สามคอลัมน์ที่มีค่า 0 และ 1 สำหรับ Dummy Encoding เราจะใช้คลาส OneHotEncoder ของไลบรารี scikit-learn รหัสอินพุตจะเป็นดังนี้ -
#สำหรับตัวแปรประเทศ
จาก sklearn.preprocessing นำเข้า LabelEncoder, OneHotEncoder
label_encoder_x= LabelEncoder()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
#การเข้ารหัสสำหรับตัวแปรจำลอง
onehot_encoder= OneHotEncoder (หมวดหมู่_คุณสมบัติ= [0])
x= onehot_encoder.fit_transform(x).toarray()
ในการรันโค้ดนี้ คุณจะได้ผลลัพธ์ดังต่อไปนี้ –
อาร์เรย์ ([[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 3.800000000e+01,

6.800000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 4.30000000e+01,
4.50000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 3.00000000e+01,
5.40000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 4.800000000e+01,
6.50000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 4.00000000e+01,
6.52222222e+04],
[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 3.50000000e+01,
5.800000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 4.11111111e+01,
5.30000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 4.90000000e+01,
7.90000000e+04],
[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 5.00000000e+01,
8.800000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 3.700000000e+01,
7.70000000e+04]])
ในผลลัพธ์ที่แสดงด้านบน ตัวแปรทั้งหมดจะถูกแบ่งออกเป็นสามคอลัมน์และเข้ารหัสเป็นค่า 0 และ 1
จะเข้ารหัสตัวแปรที่ซื้อมาได้อย่างไร?
สำหรับตัวแปรตามหมวดหมู่ที่สอง นั่นคือ ซื้อ คุณสามารถใช้อ็อบเจ็กต์ "labelencoder" ของคลาส LableEncoder เราไม่ได้ใช้คลาส OneHotEncoder เนื่องจากตัวแปรที่ซื้อมามีเพียงสองหมวดหมู่ใช่หรือไม่ใช่ ซึ่งทั้งสองถูกเข้ารหัสเป็น 0 และ 1
รหัสอินพุตสำหรับตัวแปรนี้จะเป็น –
labelencoder_y= ตัวเข้ารหัสฉลาก ()
y= labelencoder_y.fit_transform(y)
ผลลัพธ์จะเป็น -
ออก [17]: อาร์เรย์ ([0, 1, 0, 0, 1, 1, 0, 1, 0, 1])
6. การแยกชุดข้อมูล
การแยกชุดข้อมูลเป็นขั้นตอนต่อไปในการประมวลผลข้อมูลล่วงหน้าในการเรียนรู้ของเครื่อง ชุดข้อมูลทุกชุดสำหรับโมเดล Machine Learning จะต้องแบ่งออกเป็นสองชุดแยกกัน – ชุดการฝึกและชุดทดสอบ
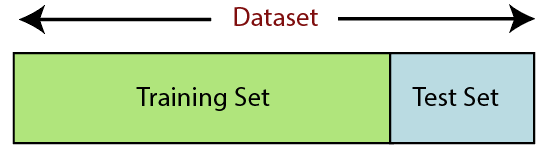
แหล่งที่มา
ชุดการฝึกหมายถึงชุดย่อยของชุดข้อมูลที่ใช้สำหรับการฝึกโมเดลการเรียนรู้ของเครื่อง ที่นี่คุณทราบถึงผลลัพธ์แล้ว ในทางกลับกัน ชุดทดสอบเป็นชุดย่อยของชุดข้อมูลที่ใช้สำหรับการทดสอบโมเดลการเรียนรู้ของเครื่อง โมเดล ML ใช้ชุดการทดสอบเพื่อคาดการณ์ผลลัพธ์
โดยปกติ ชุดข้อมูลจะแบ่งออกเป็นอัตราส่วน 70:30 หรืออัตราส่วน 80:20 ซึ่งหมายความว่าคุณใช้ข้อมูล 70% หรือ 80% สำหรับการฝึกโมเดล โดยไม่เหลืออีก 30% หรือ 20% กระบวนการแยกจะแตกต่างกันไปตามรูปร่างและขนาดของชุดข้อมูลที่เป็นปัญหา
ในการแบ่งชุดข้อมูล คุณต้องเขียนโค้ดบรรทัดต่อไปนี้ -
จาก sklearn.model_selection นำเข้า train_test_split
x_train, x_test, y_train, y_test= train_test_split(x, y, test_size= 0.2, random_state=0)
ที่นี่ บรรทัดแรกแยกอาร์เรย์ของชุดข้อมูลออกเป็นรถไฟสุ่มและชุดย่อยทดสอบ รหัสบรรทัดที่สองประกอบด้วยสี่ตัวแปร:
- x_train – คุณสมบัติสำหรับข้อมูลการฝึกอบรม
- x_test – คุณสมบัติสำหรับข้อมูลการทดสอบ
- y_train – ตัวแปรตามสำหรับข้อมูลการฝึก
- y_test – ตัวแปรอิสระสำหรับการทดสอบข้อมูล
ดังนั้น ฟังก์ชัน train_test_split() จึงรวมพารามิเตอร์สี่ตัว โดยสองพารามิเตอร์แรกเป็นอาร์เรย์ของข้อมูล ฟังก์ชัน test_size ระบุขนาดของชุดทดสอบ test_size อาจเป็น .5, .3 หรือ .2 – ระบุอัตราส่วนการหารระหว่างชุดการฝึกและชุดทดสอบ พารามิเตอร์สุดท้าย “random_state” จะตั้งค่าเมล็ดสำหรับตัวสร้างแบบสุ่มเพื่อให้ผลลัพธ์เหมือนกันเสมอ
7. การปรับขนาดคุณสมบัติ
การปรับขนาดคุณลักษณะเป็นจุดสิ้นสุดของการ ประมวลผลข้อมูลล่วงหน้าในการเรียนรู้ของเครื่อง เป็นวิธีการสร้างมาตรฐานตัวแปรอิสระของชุดข้อมูลภายในช่วงที่กำหนด กล่าวอีกนัยหนึ่ง การปรับขนาดคุณลักษณะจะจำกัดช่วงของตัวแปร เพื่อให้คุณสามารถเปรียบเทียบได้โดยใช้พื้นฐานทั่วไป
พิจารณาชุดข้อมูลนี้เช่น –

แหล่งที่มา
ในชุดข้อมูล คุณจะสังเกตได้ว่าคอลัมน์อายุและเงินเดือนไม่มีมาตราส่วนเท่ากัน ในสถานการณ์เช่นนี้ หากคุณคำนวณค่าสองค่าใดๆ จากคอลัมน์อายุและเงินเดือน ค่าเงินเดือนจะครอบงำค่าอายุและให้ผลลัพธ์ที่ไม่ถูกต้อง ดังนั้น คุณต้องลบปัญหานี้โดยทำการปรับขนาดคุณลักษณะสำหรับการเรียนรู้ของเครื่อง
โมเดล ML ส่วนใหญ่อิงตามระยะทางแบบยุคลิด ซึ่งแสดงเป็น:

แหล่งที่มา
คุณสามารถทำการปรับขนาดคุณสมบัติในการเรียนรู้ของเครื่องได้สองวิธี:
มาตรฐาน
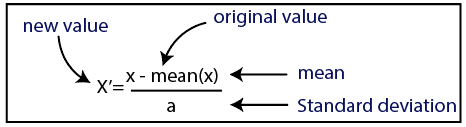
แหล่งที่มา
การทำให้เป็นมาตรฐาน
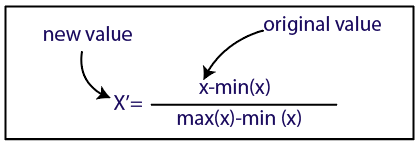
แหล่งที่มา
สำหรับชุดข้อมูลของเรา เราจะใช้วิธีการกำหนดมาตรฐาน ในการดำเนินการดังกล่าว เราจะนำเข้าคลาส StandardScaler ของไลบรารี sci-kit-learn โดยใช้โค้ดบรรทัดต่อไปนี้:
จาก sklearn.preprocessing นำเข้า StandardScaler
ขั้นตอนต่อไปคือการสร้างวัตถุของคลาส StandardScaler สำหรับตัวแปรอิสระ หลังจากนี้ คุณสามารถปรับและแปลงชุดข้อมูลการฝึกได้โดยใช้รหัสต่อไปนี้:
st_x= StandardScaler()
x_train= st_x.fit_transform(x_train)
สำหรับชุดข้อมูลทดสอบ คุณสามารถใช้ฟังก์ชัน transform() ได้โดยตรง (คุณไม่จำเป็นต้องใช้ฟังก์ชัน fit_transform() เพราะมันทำเสร็จแล้วในชุดการฝึก) รหัสจะเป็นดังนี้ -
x_test= st_x.transform(x_test)
ผลลัพธ์สำหรับชุดข้อมูลทดสอบจะแสดงค่าที่ปรับขนาดสำหรับ x_train และ x_test เป็น:
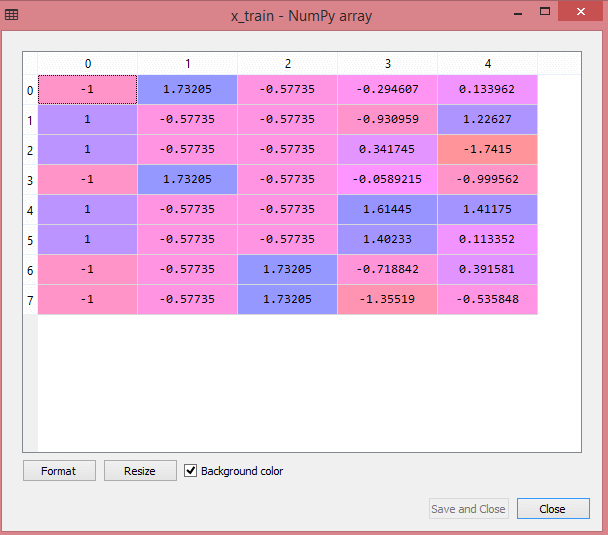
แหล่งที่มา
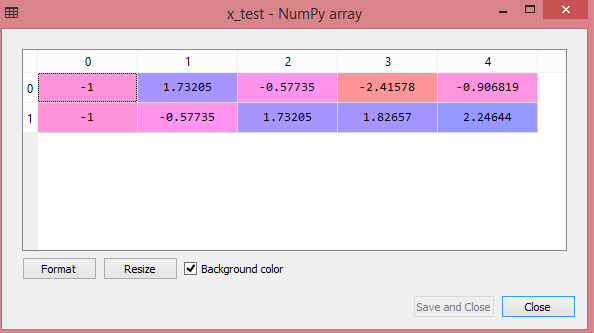
แหล่งที่มา
ตัวแปรทั้งหมดในเอาต์พุตจะถูกปรับขนาดระหว่างค่า -1 และ 1
ในการรวมขั้นตอนทั้งหมดที่เราได้ดำเนินการไปแล้ว คุณจะได้รับ:
#การนำเข้าห้องสมุด
นำเข้า numpy เป็น nm
นำเข้า matplotlib.pyplot เป็น mtp
นำเข้าแพนด้าเป็น pd
#การนำเข้าชุดข้อมูล
data_set= pd.read_csv('Dataset.csv')
#การแยกตัวแปรอิสระ
x= data_set.iloc[:, :-1].values
#การแยกตัวแปรตาม
y= data_set.iloc[:, 3].values
#การจัดการข้อมูลที่ขาดหายไป(การแทนที่ข้อมูลที่ขาดหายไปด้วยค่ากลาง)
จาก sklearn.preprocessing นำเข้า Imputer
imputer= Imputer(missing_values ='NaN', strategy='mean', axis = 0)
#การติดวัตถุอิมพีเตอร์เข้ากับตัวแปรอิสระ x
imputerimputer= imputer.fit(x[:, 1:3])
#การแทนที่ข้อมูลที่ขาดหายไปด้วยค่าเฉลี่ยที่คำนวณได้
x[:, 1:3]= imputer.transform(x[:, 1:3])
#สำหรับตัวแปรประเทศ
จาก sklearn.preprocessing นำเข้า LabelEncoder, OneHotEncoder
label_encoder_x= LabelEncoder()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
#การเข้ารหัสสำหรับตัวแปรจำลอง
onehot_encoder= OneHotEncoder (หมวดหมู่_คุณสมบัติ= [0])
x= onehot_encoder.fit_transform(x).toarray()
#encoding สำหรับตัวแปรที่ซื้อ
labelencoder_y= ตัวเข้ารหัสฉลาก ()
y= labelencoder_y.fit_transform(y)
# แยกชุดข้อมูลออกเป็นชุดฝึกและทดสอบ
จาก sklearn.model_selection นำเข้า train_test_split
x_train, x_test, y_train, y_test= train_test_split(x, y, test_size= 0.2, random_state=0)
#Feature Scaling ของชุดข้อมูล
จาก sklearn.preprocessing นำเข้า StandardScaler
st_x= StandardScaler()
x_train= st_x.fit_transform(x_train)
x_test= st_x.transform(x_test)
นั่นคือการประมวลผลข้อมูลในการเรียนรู้ของเครื่องโดยสังเขป!
คุณสามารถตรวจสอบ Executive PG Program ของ IIT Delhi ใน Machine Learning & AI ร่วมกับ upGrad IIT Delhi เป็นหนึ่งในสถาบันที่มีชื่อเสียงที่สุดในอินเดีย ด้วยคณาจารย์ภายในมากกว่า 500 คนซึ่งดีที่สุดในสาขาวิชา
การประมวลผลข้อมูลล่วงหน้ามีความสำคัญอย่างไร
เนื่องจากข้อผิดพลาด ความซ้ำซ้อน ค่าที่ขาดหายไป และความไม่สอดคล้องกันล้วนเป็นอันตรายต่อความสมบูรณ์ของชุดข้อมูล คุณจึงต้องจัดการทั้งหมดเพื่อให้ได้ผลลัพธ์ที่แม่นยำยิ่งขึ้น สมมติว่าคุณใช้ชุดข้อมูลที่มีข้อบกพร่องเพื่อฝึกระบบการเรียนรู้ของเครื่องเพื่อจัดการกับการซื้อของลูกค้า ระบบมีแนวโน้มที่จะสร้างอคติและการเบี่ยงเบน ส่งผลให้ผู้ใช้ได้รับประสบการณ์ที่ไม่ดี ดังนั้น ก่อนที่คุณจะใช้ข้อมูลนั้นตามวัตถุประสงค์ที่คุณตั้งใจไว้ ข้อมูลนั้นจะต้องมีการจัดระเบียบและ 'สะอาด' เท่าที่จะทำได้ ขึ้นอยู่กับประเภทของความยากที่คุณกำลังเผชิญ มีตัวเลือกมากมาย
การล้างข้อมูลคืออะไร?
เกือบจะมีข้อมูลที่ขาดหายไปและมีเสียงดังในชุดข้อมูลของคุณ เนื่องจากขั้นตอนการรวบรวมข้อมูลไม่เหมาะ คุณจึงมีข้อมูลจำนวนมากที่ไร้ประโยชน์และขาดหายไป การล้างข้อมูลเป็นวิธีที่คุณควรใช้เพื่อจัดการกับปัญหานี้ นี้สามารถแบ่งออกเป็นสองประเภท หัวข้อแรกกล่าวถึงวิธีจัดการกับข้อมูลที่ขาดหายไป คุณสามารถเลือกที่จะละเว้นค่าที่ขาดหายไปในส่วนนี้ของการรวบรวมข้อมูล (เรียกว่าทูเปิล) วิธีการล้างข้อมูลที่สองคือสำหรับข้อมูลที่มีสัญญาณรบกวน การกำจัดข้อมูลที่ไร้ประโยชน์ซึ่งระบบไม่สามารถอ่านได้เป็นสิ่งสำคัญ หากคุณต้องการให้กระบวนการทั้งหมดทำงานได้อย่างราบรื่น
คุณหมายถึงอะไรโดยการแปลงและการลดข้อมูล
การประมวลผลข้อมูลล่วงหน้าจะเข้าสู่ขั้นตอนการแปลงหลังจากจัดการกับข้อกังวล คุณใช้เพื่อแปลงข้อมูลเป็นรูปแบบที่เกี่ยวข้องสำหรับการวิเคราะห์ Normalization, Attribute Selection, Discretization และ Concept Hierarchy Generation เป็นแนวทางบางส่วนที่สามารถใช้เพื่อบรรลุเป้าหมายนี้ แม้แต่วิธีการอัตโนมัติ การกลั่นกรองชุดข้อมูลขนาดใหญ่อาจใช้เวลานาน นั่นคือเหตุผลที่ขั้นตอนการลดข้อมูลมีความสำคัญมาก: ลดขนาดของชุดข้อมูลโดยจำกัดให้เหลือเฉพาะข้อมูลที่สำคัญที่สุด เพิ่มประสิทธิภาพการจัดเก็บในขณะที่ลดค่าใช้จ่ายทางการเงินและเวลาในการทำงานร่วมกับพวกเขา