
Top 15 întrebări și răspunsuri la interviu Hadoop în 2022
Publicat: 2021-01-09Pe măsură ce analiza datelor câștigă avânt, a existat o creștere a cererii de oameni buni în manipularea Big Data. De la analiști de date la oameni de știință ai datelor, Big Data creează astăzi o serie de profiluri de locuri de muncă. Primul și cel mai important lucru cu care trebuie să fiți practic este Hadoop.
Indiferent de ce rol/profil, probabil că vei lucra la Hadoop într-un fel sau altul. Așadar, vă puteți aștepta invariabil ca intervievatorii să vă răspundă câteva întrebări Hadoop.
Pentru asta și mai mult, haideți să ne uităm la primele 15 întrebări de interviu Hadoop la care vă puteți aștepta în orice interviu la care participați.
Ce este Hadoop? Care sunt componentele principale Hadoop?
Hadoop este o infrastructură echipată cu instrumente și servicii relevante necesare procesării și stocării Big Data. Mai exact, Hadoop este „soluția” pentru toate provocările Big Data. În plus, cadrul Hadoop ajută organizațiile să analizeze Big Data și să ia decizii de afaceri mai bune.
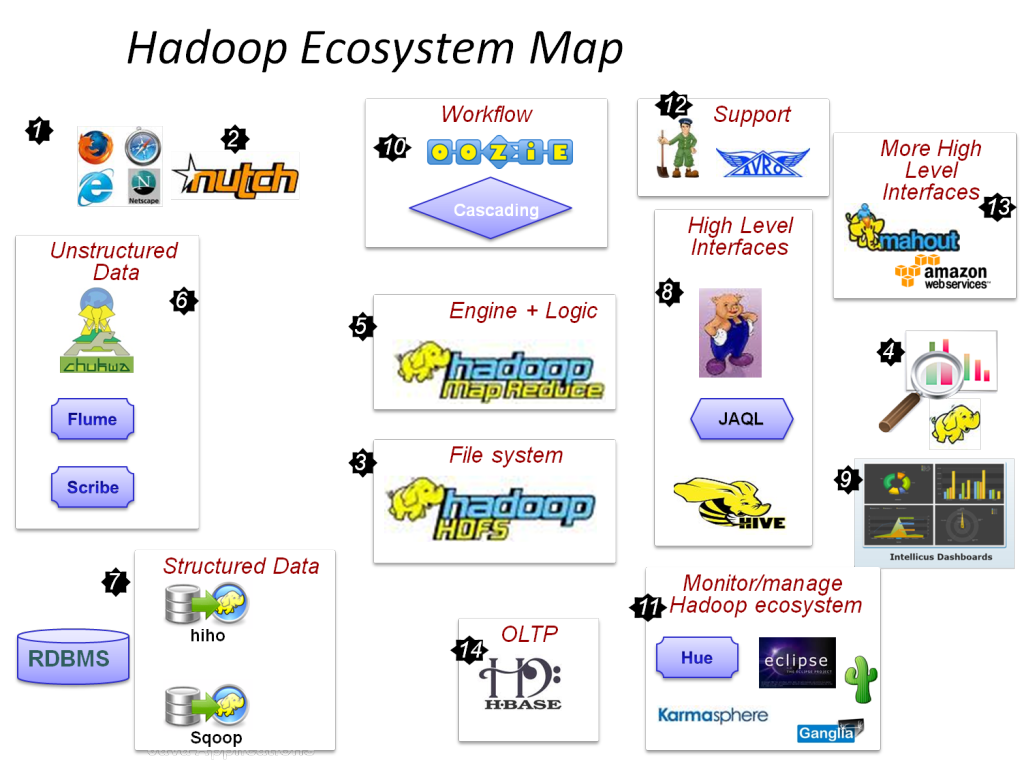
Componentele principale ale Hadoop sunt:
- HDFS
- Hadoop MapReduce
- Hadoop Common
- Fire
- PIG și HIVE – Componentele de acces la date.
- HBase – Pentru stocarea datelor
- Ambari, Oozie și ZooKeeper – Componenta de gestionare și monitorizare a datelor
- Thrift și Avro – Componente de serializare a datelor
- Apache Flume, Sqoop, Chukwa – Componentele de integrare a datelor
- Apache Mahout și Drill – Componente Data Intelligence
Care sunt conceptele de bază ale cadrului Hadoop?
Hadoop se bazează fundamental pe două concepte de bază. Sunt:
- HDFS: HDFS sau Hadoop Distributed File System este un sistem de fișiere de încredere bazat pe Java, utilizat pentru stocarea unor seturi de date vaste în format bloc. Arhitectura Stăpân-Sclav îl alimentează.
- MapReduce: MapReduce este o structură de programare care ajută la procesarea unor seturi mari de date. Această funcție este împărțită în două părți – în timp ce „map” segrega seturile de date în tupluri, „reduce” folosește tuplurile hărții și creează o combinație de bucăți mai mici de tupluri.
Numiți cele mai comune formate de intrare în Hadoop?
Există trei formate comune de intrare în Hadoop:
- Format de introducere text: Acesta este formatul de intrare implicit în Hadoop.
- Format de intrare a fișierului secvență: Acest format de intrare este utilizat pentru citirea fișierelor în secvență.
- Format de intrare a valorii cheie: Acesta este folosit pentru a citi fișiere text simplu.
Ce este YARN?
YARN este abrevierea lui Yet Another Resource Negotiator. Este cadrul de procesare a datelor Hadoop care gestionează resursele de date și creează un mediu pentru procesarea cu succes. 
Ce este „Rack Awareness”?
„Rack Awareness” este un algoritm pe care NameNode îl folosește pentru a determina modelul în care blocurile de date și replicile lor sunt stocate în clusterul Hadoop. Acest lucru se realizează cu ajutorul definițiilor de rack care reduc aglomerația dintre nodurile de date conținute în același rack.

Ce sunt NameNodes active și pasive?
Un sistem Hadoop de înaltă disponibilitate conține de obicei două NameNodes – Active NameNode și Passive NameNode.
NameNode care rulează cluster-ul Hadoop se numește Active NameNode, iar NameNode de așteptare care stochează datele Active NameNode este Passive NameNode.
Scopul de a avea două NameNodes este ca, dacă Active NameNode se blochează, NameNode pasiv poate prelua conducerea. Astfel, NameNode rulează întotdeauna în cluster, iar sistemul nu eșuează niciodată.
Care sunt diferitele programatoare din cadrul Hadoop?
Există trei programatoare diferite în cadrul Hadoop:
- COSHH – COSHH ajută la planificarea deciziilor prin revizuirea clusterului și a volumului de lucru combinat cu eterogenitatea.
- FIFO Scheduler – FIFO aliniază joburile într-o coadă în funcție de ora lor de sosire, fără a folosi eterogenitatea.
- Partajare echitabilă – Partajarea echitabilă creează un pool pentru utilizatorii individuali care conține mai multe hărți și reduce spațiile pe o resursă pe care o pot folosi pentru a executa anumite sarcini.
Ce este execuția speculativă?
Adesea, în cadrul Hadoop, unele noduri pot rula mai lent decât restul. Acest lucru tinde să constrângă întregul program. Pentru a depăși acest lucru, Hadoop detectează mai întâi sau „speculează” atunci când o sarcină rulează mai lent decât de obicei, apoi lansează o copie de rezervă echivalentă pentru acea sarcină. Deci, în acest proces, nodul principal execută ambele sarcini simultan, iar oricare dintre acestea este finalizată primul este acceptată în timp ce cealaltă este ucisă. Această funcție de rezervă a Hadoop este cunoscută sub numele de Execuție speculativă.

Numiți principalele componente ale Apache HBase?
Apache HBase este compus din trei componente:
- Server de regiune: După ce un tabel este împărțit în mai multe regiuni, clusterele acestor regiuni sunt redirecționate către clienți prin intermediul serverului de regiune.
- HMaster: Acesta este un instrument care ajută la gestionarea și coordonarea serverului Regiune.
- ZooKeeper: ZooKeeper este un coordonator în mediul distribuit HBase. Ajută la menținerea unei stări de server în interiorul clusterului prin comunicare în sesiuni.
Ce este „Checkpointing”? Care este beneficiul lui?
Punctul de verificare se referă la procedura prin care un FsImage și un jurnal de editare sunt combinate pentru a forma o nouă FsImage. Astfel, în loc să reda jurnalul de editare, NameNode poate încărca direct starea finală în memorie din FsImage. NameNode secundar este responsabil pentru acest proces.
Avantajul oferit de Checkpointing este că minimizează timpul de pornire a NameNode, făcând astfel întregul proces mai eficient.
Aplicații de date mari în cultura pop
Cum se depanează un cod Hadoop?
Pentru a depana un cod Hadoop, mai întâi, trebuie să verificați lista sarcinilor MapReduce care rulează în prezent. Apoi trebuie să verificați dacă sarcinile orfane rulează simultan sau nu. Dacă da, trebuie să găsiți locația jurnalelor de Resource Manager urmând acești pași simpli:
Rulați „ps –ef | grep –I ResourceManager” și în rezultatul afișat, încercați să găsiți dacă există o eroare legată de un anumit ID de job.
Acum, identificați nodul de lucru care a fost folosit pentru a executa sarcina. Conectați-vă la nod și rulați „ps –ef | grep –iNodeManager.”
În cele din urmă, examinați cu atenție jurnalul Node Manager. Majoritatea erorilor sunt generate din jurnalele la nivel de utilizator pentru fiecare job de reducere a hărții.
Care este scopul RecordReader în Hadoop?
Hadoop descompune datele în formate bloc. RecordReader ajută la integrarea acestor blocuri de date într-o singură înregistrare care poate fi citită. De exemplu, dacă datele de intrare sunt împărțite în două blocuri -
Rândul 1 – Bun venit la
Rândul 2 – UpGrad
RecordReader va citi acest lucru ca „Bine ați venit la UpG rad”.
Care sunt modurile în care poate rula Hadoop?
Modurile în care poate rula Hadoop sunt:
- Modul autonom – Acesta este un mod implicit al Hadoop care este utilizat în scopul depanării. Nu acceptă HDFS.
- Mod pseudo-distribuit – Acest mod a necesitat configurarea fișierelor mapred-site.xml, core-site.xml și hdfs-site.xml. Atât Nodul Master, cât și Nodul Slave sunt la fel aici.
- Modul complet distribuit – Modul complet distribuit este etapa de producție a Hadoop în care datele sunt distribuite pe diferite noduri dintr-un cluster Hadoop. Aici, nodurile Master și Slave sunt alocate separat.
Numiți câteva aplicații practice ale Hadoop.
Iată câteva exemple din viața reală în care Hadoop face diferența:
- Gestionarea traficului stradal
- Detectarea și prevenirea fraudei
- Analizați datele clienților în timp real pentru a îmbunătăți serviciile pentru clienți
- Accesarea datelor medicale nestructurate de la medici, HCP etc., pentru a îmbunătăți serviciile de asistență medicală.
Care sunt instrumentele vitale Hadoop care pot îmbunătăți performanța Big Data?
Instrumentele Hadoop care sporesc semnificativ performanța Big Data sunt

• Stup
• HDFS
• HBază
• SQL
• NoSQL
• Oozie
• Nori
• Avro
• Flume
• Ingrijitor zoo
Ingineri de date mari: mituri vs. realități
Concluzie
Aceste întrebări de interviu Hadoop ar trebui să vă fie de mare ajutor la următorul interviu. Deși uneori este tendința intervievatorilor de a răsuci unele întrebări de interviu Hadoop, nu ar trebui să fie o problemă pentru tine dacă ai rezolvat elementele de bază.
Dacă sunteți interesat să aflați mai multe despre Big Data, consultați programul nostru PG Diploma în Dezvoltare Software Specializare în Big Data, care este conceput pentru profesioniști care lucrează și oferă peste 7 studii de caz și proiecte, acoperă 14 limbaje și instrumente de programare, practică practică. ateliere de lucru, peste 400 de ore de învățare riguroasă și asistență pentru plasarea unui loc de muncă cu firme de top.