
Estratégias para projetos sem cabeça com sistemas de gerenciamento de conteúdo estruturado
Publicados: 2022-03-10Este é o guia que eu gostaria de ter nos últimos dois anos ao executar projetos com sistemas de gerenciamento de conteúdo (CMSs) headless. Fui desenvolvedor, consultor de experiência do usuário e tecnologia, gerente de projetos, arquiteto de informações e autor. Os diferentes chapéus me fizeram perceber que, mesmo que tenhamos os chamados CMSs “sem cabeça” por um tempo, ainda há uma maneira de pensar em como usá-los melhor.
Estamos agora em um lugar onde muitos de nós confiam em estruturas JavaScript para trabalho de front-end, usando sistemas de design feitos de componentes e composições, em vez de apenas implementar layouts de página plana. Há muita tração em relação aos JAMstacks e aplicativos isomórficos/universais que são executados no servidor e no cliente. A peça final do quebra-cabeça é como gerenciamos todo o conteúdo.
Os CMSs tradicionais estão adicionando APIs para fornecer conteúdo por meio de solicitações de rede e o formato JSON. Além disso, CMSs “sem cabeça” surgiram para fornecer conteúdo exclusivamente por meio de APIs. Meu argumento neste artigo, porém, é que devemos gastar menos tempo falando sobre “headless” e mais sobre “conteúdo estruturado” . Porque essa é a qualidade essencial desses sistemas. Há muitas implicações para nosso ofício implícitas nesses sistemas, e ainda temos um caminho a percorrer em termos de descobrir os bons padrões de como devemos lidar com essas tecnologias.
Vindo para a consultoria de tecnologia com formação em humanidades, aprendi muito sobre como organizar e trabalhar com projetos da Web que adotam uma abordagem centrada no conteúdo - tanto com os mais recentes baseados em API quanto com os CMSs tradicionais. Passei a apreciar como começar cedo com conteúdo ao vivo real de um CMS; fazê-lo em um ambiente interdisciplinar não apenas tornou possível descobrir as complexidades em um estágio inicial, mas também dá agência a todos os envolvidos e oferece oportunidades para refletir sobre os desafios e possibilidades da tecnologia e do design em seu sentido mais amplo.
WordPress sem cabeça
Todo mundo sabe que se um site for lento, os usuários irão abandoná-lo. Vamos dar uma olhada no básico da criação de um WordPress desacoplado. Leia um artigo relacionado →
Neste artigo, vou sugerir algumas estratégias abrangentes, com alguns exemplos concretos do mundo real sobre como pensar em trabalhar com conteúdo estruturado. No momento em que escrevo, acabei de começar a trabalhar para uma empresa de SaaS que fornece esse serviço de gerenciamento de conteúdo, para hospedagem de conteúdo entregue por APIs. Farei referências a ele, tanto por causa da minha experiência anterior com ele em projetos em que estive envolvido como consultor, mas também porque acho que ilustra bem os pontos que quero fazer. Portanto, considere isso uma espécie de isenção de responsabilidade.
Dito isto, tenho pensado em escrever este artigo há alguns anos e me esforcei para torná-lo aplicável a qualquer plataforma que você escolher. Então, sem mais delongas, vamos voltar vinte anos no tempo para entender um pouco mais onde estamos hoje.
Primeiros passos com os padrões da Web
No início dos anos 2000, o movimento Web Standards inspirou um campo a mudar sua forma de trabalhar. A partir de uma abordagem “layout-first”, eles direcionaram nossa atenção para como o conteúdo de uma página deve ser marcado semanticamente usando HTML: O menu de um site não é um <table> , é um <nav> ; Um título não é um <b> , é um <h1> . Foi um passo significativo para pensar sobre os diferentes papéis que o conteúdo da web desempenha para ajudar os usuários a encontrá-lo, identificá-lo e absorvê-lo.
O movimento Web Standards introduziu o argumento de que a marcação semântica melhorou a acessibilidade, o que também melhorou sua classificação nos resultados de pesquisa do Google. Também marcou uma mudança na forma como pensamos sobre o conteúdo da web . Seu site não era mais o único lugar onde seu conteúdo era representado. Você também teve que pensar em como suas páginas da web eram apresentadas em outros contextos visuais, como em resultados de pesquisa ou leitores de tela. Mais tarde, isso foi alimentado pelas mídias sociais e visualizações incorporadas de links compartilhados. A mentalidade mudou de como o conteúdo deveria parecer , para o que deveria significar . Isso também é a chave para trabalhar com conteúdo estruturado.
Com a adoção de dispositivos de bolso conectados à Internet, a web de repente se tornou um concorrente sério em aplicativos. A competição, no entanto, foi principalmente para os olhos do usuário final. Muitas organizações ainda precisavam distribuir informações sobre seus produtos e serviços em seus aplicativos e em suas diferentes presenças na web. Ao mesmo tempo, a web amadureceu e JavaScript e AJAX tornaram mais fácil conectar diferentes fontes de conteúdo por meio de APIs. Hoje, temos GraphQL e ferramentas que simplificam a busca de conteúdo e o gerenciamento de estado. E assim as peças do quebra-cabeça tecnológico começam a se encaixar.
“Crie uma vez, publique em qualquer lugar”
Embora seja descrito principalmente como uma “mudança tecnológica”, a incorporação de conteúdo em cargas JSON (viajando ao longo de tubos HTTP) tem um impacto descomunal em como pensamos sobre o conteúdo digital e os fluxos de trabalho ao redor. De certa forma, já tem. Quase dez anos atrás, o convidado Daniel Jacobson da National Public Radio (NPR) escreveu em um blog programmableweb.com sobre sua abordagem, resumida na sigla COPE, que significa “Create Once, Publish Everywhere”. No artigo, ele apresenta um sistema de gerenciamento de conteúdo que fornece conteúdo para várias interfaces digitais por meio de uma API – não por meio de uma máquina de renderização HTML – como a maioria dos CMSs da época (e provavelmente agora).
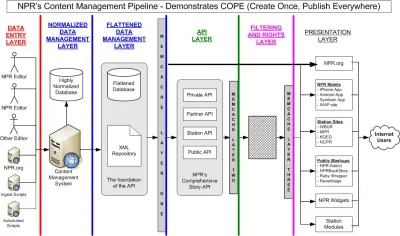
A “camada de gerenciamento de dados” COPE da NPR é o que se tornaria a noção de “um CMS sem cabeça”. Nos primórdios do COPE, isso era alcançado estruturando o conteúdo em XML. Hoje, o JSON se tornou o formato de dados dominante para transferência de dados por APIs, incluindo dispositivos de internet das coisas e outros sistemas fora da web. Se você deseja trocar conteúdo com chatbots, interfaces de voz e até software para prototipagem visual, muitas vezes você fala HTTP com sotaque JSON.
“Descunhando” o termo “CMS sem cabeça”
De acordo com o Google Trends, as buscas por “CMS headless” ganharam popularidade em 2015, ou seja, seis anos após o artigo COPE da NPR. O termo “headless” (pelo menos em relação à tecnologia digital e não à aristocracia francesa do final do século 18), tem sido usado por um bom tempo para falar sobre sistemas que rodam sem uma interface gráfica de usuário.
Nota : Pode-se argumentar que uma interface de linha de comando é realmente “gráfica”, como software em servidores ou ambientes de teste (mas vamos guardar isso para outro artigo).
Eu sou de duas mentes chamando esses novos CMSs "sem cabeça". Poderíamos também chamá-los de “policefálicos” – aquilo que tem muitas cabeças. São as Hidras e Cerbeuses dos CMSs. “Headless” também está definindo esses sistemas pela capacidade que lhes falta (ou seja, um mecanismo de template para renderização de páginas da web), em vez de defini-los por sua verdadeira força: tornar possível estruturar conteúdo sem as restrições da web. Dito isto, a partir de hoje, muitas das soluções nesta categoria também podem ser chamadas de “Nick Quase Sem Cabeça”. Porque a interface de edição ainda está fortemente acoplada ao sistema. Sua “falta de cabeça” surge da falta de um mecanismo de modelagem, ou seja, o maquinário que produz marcação a partir do conteúdo.
Nota : Eu quase definitivamente usaria um CMS chamado “Mimsy-Porpington” (conhecido do universo Harry Potter).
Em vez disso, eles disponibilizam o conteúdo por meio de uma API, oferecendo mais flexibilidade para como, o que e onde você deseja exibir e usar esse conteúdo. Isso os torna companheiros perfeitos para estruturas de front-end JavaScript populares, como React, Angular e Vue. E apesar da alegação de poder entregar conteúdo para “sites, aplicativos e dispositivos”, a maioria deles ainda é limitada pela forma como o conteúdo da web funciona. Isso é mais perceptível na maneira como a maioria lida com rich text – armazenando-o como HTML ou Markdown.
Os CMSs tradicionais também começaram a adicionar APIs um tanto genéricas além de seus sistemas de renderização de modelos e chamam isso de “desacoplado” como uma forma de se distinguir de seus novos concorrentes. “Tudo isso e APIs também!”* é a afirmação. Alguns desses CMSs também são bastante agnósticos quando se trata de modelagem de conteúdo. Por exemplo, o Craft CMS quase não faz suposições sobre seu modelo de conteúdo quando você o instala pela primeira vez. O Wordpress também está adotando APIs para entrega de conteúdo. Suspeito que a diferença entre os jogadores antigos no campo de CMS e os novos ficará mais estreita à medida que avançamos.
No entanto, colocar o gerenciamento de conteúdo por trás de APIs (em vez de um renderizador HTML) é um passo importante para formas mais sofisticadas de trabalhar em uma era em que o texto, as imagens, os vídeos e a mídia de uma organização são digitalizados e expostos a usuários e clientes internos e externos. É hora, porém, de deixar de definir a falta de recursos de renderização de front-end para o que eles realmente podem fazer por nós: nos dar uma maneira de trabalhar com conteúdo estruturado . Então, devemos chamá-los de “Sistemas de Gerenciamento de Conteúdo Estruturado”? Como em “Não Bob, este não é o seu CMS usual. Este é um SCMS, confie em mim, vai ser uma coisa. ”
Não é sobre as cabeças, é sobre conteúdo estruturado
A mudança mais radical que os Sistemas de Gerenciamento de Conteúdo Estruturado (SCMS) impõe é deixar de organizar o conteúdo de acordo com uma hierarquia de páginas para onde você está livre para estruturar o conteúdo para qualquer finalidade que achar melhor. Evitar conteúdo duplicado é uma vantagem clara porque aumenta a confiabilidade e diminui a carga administrativa (você não precisa lidar com conteúdo duplicado em vários canais). Em outras palavras: Crie uma vez, publique em todos os lugares . Se você precisar atualizar a descrição do seu produto apenas uma vez – em um sistema – e ela for atualizada onde quer que seu produto seja exposto ao usuário, isso é claramente uma vantagem.
Embora os fornecedores de SCMS frequentemente usem “seu site e um aplicativo” para justificar o pensamento diferente na estrutura da página, você não precisa atravessar o rio para obter benefícios de uma estrutura de conteúdo estruturada. Com a popularidade dos frameworks JavaScript, é cada vez mais comum construir sites como uma composição de componentes individuais, que podem ser “preenchidos” com conteúdo diferente dependendo do estado e do contexto. Você pode ter um cartão de produto que aparece em muitos contextos diferentes em todo o seu aplicativo da web. Estamos vendo que o desenvolvimento web moderno deixa de definir documentos e páginas para compor componentes de acordo com uma mistura de entrada do usuário, algoritmos e personalização.
Essas tendências de como os sistemas de design são feitos e como somos incentivados a trabalhar em equipe por meio de processos de teste, aprendizado e iteração tornam o campo do gerenciamento de conteúdo maduro para algumas novas maneiras de pensar. Alguns padrões surgiram, mas ainda temos muitos caminhos a percorrer. Portanto, com base na minha experiência de trabalhar em equipes e projetos que colocaram o conteúdo na frente e no centro, e agora como parte de uma equipe que constrói um serviço para isso (e peço que você esteja ciente de qualquer viés aqui), quero apresentar algumas estratégias que acredito que possam ser úteis e criar pontos para discussão posterior.
1. Abordagem do Conteúdo em Equipes Multidisciplinares
Acredito que é coisa do passado que um designer gráfico possa entregar páginas obsoletas e com pixels perfeitos para um desenvolvedor frontend cuja responsabilidade era “implementar” o design. Agora fazemos sistemas de design que consistem em componentes menores, dispostos em composições que vêm com vários estados possíveis prontos para uso. Na maioria das vezes, esses componentes precisam ser resilientes à entrada gerada pelo usuário, o que significa que quanto mais cedo você introduzir conteúdo ao vivo no processo, melhor. A responsabilidade de um desenvolvedor frontend não é reproduzir a visão de um designer gráfico ; é manipular um campo complexo de como os navegadores renderizam HTML, CSS e JavaScript, certificando-se de que as interfaces do usuário sejam responsivas, acessíveis e de alto desempenho.
Ao trabalhar como consultor de tecnologia na Netlife (consultoria especializada em experiência do usuário), vi grandes passos sendo dados para a colaboração entre desenvolvedores, designers e pesquisadores de usuários. Embora nossos editores de conteúdo sempre estivessem envolvidos no projeto desde o início, suas contribuições não entraram no fluxo de trabalho do design principalmente por causa de atritos técnicos.
O gargalo era muitas vezes um CMS legado que não podíamos tocar, ou que levava tempo para construir a estrutura de conteúdo porque dependia do layout do design. Isso geralmente resultava em duplicação do trabalho: criamos um protótipo HTML, geralmente baseado em conteúdo analisado de arquivos Markdown, que precisava ser reimplementado na pilha de CMS quando o teste do usuário era feito, e todos ficaram felizes em pixels . Este era muitas vezes um processo caro, pois as limitações no CMS foram descobertas no final do processo. Também cria pressão em todas as partes para “acertar na primeira vez” e deixa menos espaço para o tipo de experimentação que você deseja em um projeto de design.
O trabalho multidisciplinar requer sistemas ágeis
Mudar para um SCMS em que levava minutos para codificar um modelo de conteúdo (onde os campos e a API estavam prontos instantaneamente) virou nosso processo de cabeça para baixo — e para melhor. Lembro-me de sentar com o editor de conteúdo do novo u4.no nos primeiros dias do projeto. Falando sobre como eles trabalharam e gostariam de trabalhar com seu conteúdo. Muito rapidamente, traduzimos nossas conclusões em objetos JavaScript simples que foram instantaneamente transformados em um ambiente de edição no navegador. Descobrir títulos e descrições úteis para os títulos. Conversamos sobre como eles queriam trechos de texto que pudessem reutilizar em diferentes páginas e contextos, que eles chamavam internamente de “nuggets”, que então criamos ali mesmo.
Permitir esse tipo de exploração no início do desenvolvimento do projeto - um editor de conteúdo e um desenvolvedor conversando enquanto a interface estava sendo feita na nossa frente - parecia poderoso. Sabendo que poderíamos continuar projetando o frontend em React enquanto ela e seus colegas começavam a trabalhar com o conteúdo. E sem nos preocuparmos em nos pintar em um canto, como muitas vezes fazíamos com CMSs em que a estrutura estava fortemente acoplada com a forma como você tinha que codificar a parte do frontend.
Um sistema de conteúdo deve permitir experimentação e iteração
Projetos de redesenho criativos à parte, um sistema para conteúdo estruturado também deve permitir que você continue melhorando, testando e iterando seu conteúdo como parte de todo o seu sistema de design. Os designers de UX devem ser capazes de prototipar rapidamente com conteúdo real usando ferramentas como Sketch ou Framer X. Você deve ser capaz de aumentar o gerenciamento de conteúdo com medidas quantitativas, sejam escalas de legibilidade ou como o conteúdo é executado onde é usado.
Nota : Eu usei o termo “UX designers” acima apesar de ter a opinião de que todos nós devemos – de alguma forma – nos relacionar com o processo de criar boas experiências de usuário. Somos todos designers de UX em nossas diferentes vertentes de design.
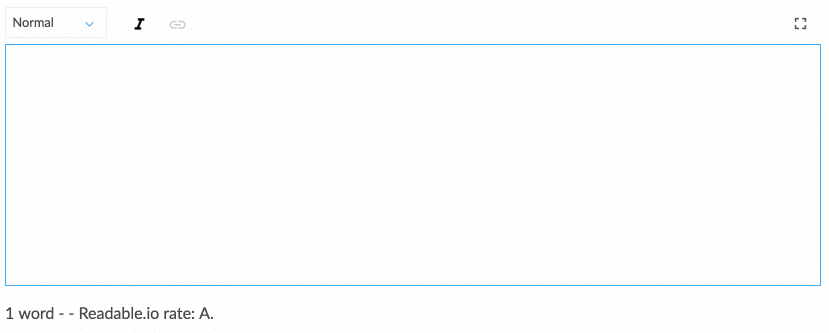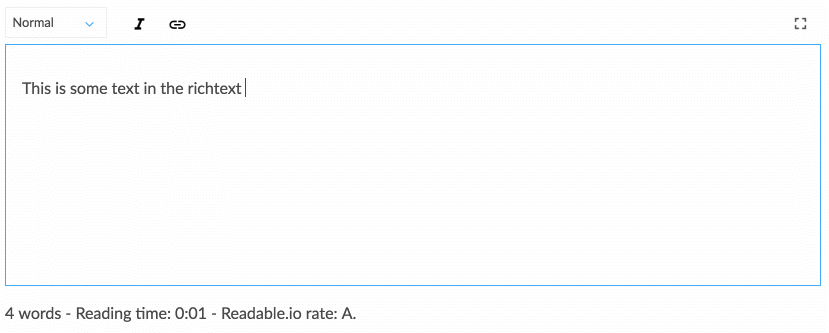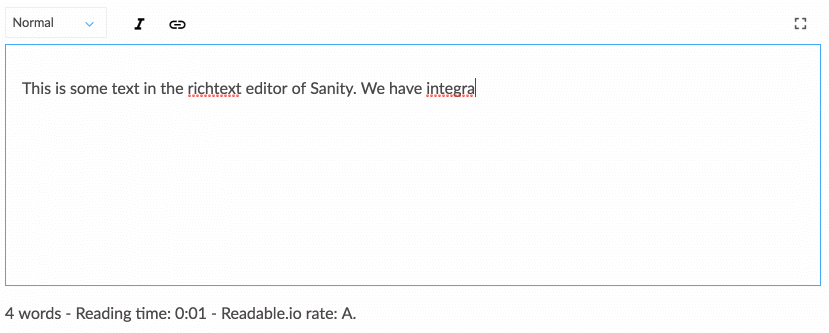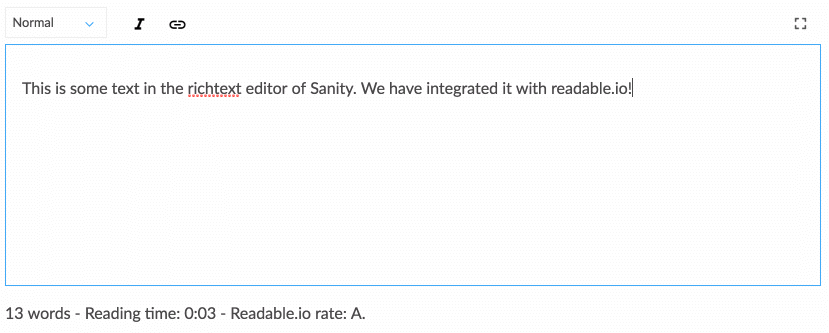
Trabalhar com conteúdo estruturado requer um pouco de se acostumar se você estiver acostumado apenas com conteúdo WYSIWYG diretamente em seu layout de página da web. No entanto, ele se presta a uma conversa que está mais alinhada com a forma como o campo do design digital está se movendo. O conteúdo estruturado permite que uma equipe de designers, desenvolvedores, editores de conteúdo, pesquisadores de usuários e gerentes de projeto pensem coletivamente sobre como um sistema deve funcionar para atender às necessidades e objetivos estratégicos dos usuários. Isso também exige que você pense de forma diferente sobre como o conteúdo se estrutura, o que nos leva à próxima estratégia.
2. Você pode não precisar de uma hierarquia
Uma das mudanças mais notáveis para muitos é que os sistemas de conteúdo estruturado são voltados para coleções e listas de documentos e não para hierarquias semelhantes a pastas que refletem as estruturas de navegação do site. Essas estruturas deixam de fazer sentido assim que parte do conteúdo é usada em outros contextos – sejam chatbots, mídia impressa ou outros sites. Os CMSs tradicionais tentaram mitigar isso permitindo blocos de conteúdo reutilizáveis, mas eles ainda precisam ser colocados em layouts de página e complicados de raciocinar por meio de APIs.

Cada página na sua
Conforme estabelecido em The Core Model, quando um de seus principais referenciadores é o Google ou o compartilhamento nas mídias sociais, você deve considerar cada página uma página de destino. E se você observar a distribuição das visualizações de página, notará que algumas de suas páginas são muito mais populares do que outras. A menos que você seja um site de notícias, essas tendem a não ser as notícias, mas aquelas que permitem ao usuário alcançar o que eles esperavam alcançar em seu site. Eles são onde os negócios estão realmente acontecendo.
Seu conteúdo digital deve estar a serviço da interseção de seus próprios objetivos estratégicos e objetivos individuais de seus usuários. Quando a agência digital Bengler (antecessora do sanity.io) fez o novo site para oma.eu, eles não estruturou o conteúdo após uma elaborada hierarquia de páginas. Eles fizeram tipos de conteúdo que refletiam a realidade cotidiana organizacional, ou seja, depois de projetos , pessoas e publicações . Na verdade, o site do OMA é quase completamente plano em termos de hierarquia de conteúdo, e a primeira página é gerada a partir de uma mistura de regras algorítmicas e editoriais.

Então, como proceder? Acredito que uma mistura de pensar em seu conteúdo como um reflexo de como o modelo mental de sua organização e o que ele precisa ser para ser útil para o que seus usuários precisarem.
Aqui está um exemplo básico: Ao criar uma página de funcionários, você provavelmente deve começar com um tipo de conteúdo chamado pessoa . Uma pessoa pode ter um nome, informações de contato, uma imagem, diferentes funções organizacionais e uma pequena biografia. Um documento pessoal pode ser reutilizado em listas de contatos, assinaturas de autores de artigos, interfaces de suporte de bate-papo e crachás de acesso à construção. Talvez você já tenha um sistema interno que saiba quem são essas pessoas e que vem com uma API? Ótimo, então sincronize com isso.
Não se perca em uma toca de coelho ontológica
É útil retornar ao modo como o Google indexa páginas da web e como eles estão tentando indexar as informações do mundo. É por isso que eles estão gastando tempo e esforço em dados vinculados (RDFa, microformato, JSON-LD). Se você anotar suas páginas da web com elementos JSON-LD, aparecerá com mais destaque nos resultados de pesquisa. Também é relevante quando suas informações devem ser faladas por assistentes de voz e exibidas em uma interface do usuário do assistente. Se o seu conteúdo já estiver estruturado e facilmente disponível em uma API, será relativamente fácil para você implementá-lo nesses microformatos.
Não tenho certeza se recomendaria entrar nas ontologias do schema.org e vários recursos de dados vinculados, pelo menos não para fins de editor. Você pode rapidamente se perder em uma toca de coelho tentando fazer estruturas platônicas perfeitas onde tudo se encaixa.
Newsflash : Nunca será, porque o mundo é um lugar confuso e porque as pessoas pensam sobre as coisas de maneira diferente.
É mais importante estruturar seu conteúdo em um sistema que faça sentido intuitivo e se adapte conforme as necessidades mudam. É por isso que é importante começar com a modelagem de conteúdo logo no início do processo de design e desenvolvimento — você precisa aprender sobre como ela precisa ser usada.
Resumo da realidade, não das convenções do CMS
Pode ser tentador apenas seguir as convenções com as quais seu CMS vem. Lembre-se de como o Wordpress lhe dará “Posts” e “Páginas”, e de repente tudo precisa ser encaixado nessas caixas? Um campo de rich text WYSIWYG é flexível, pois permite que você insira qualquer coisa, mas o conteúdo não será estruturado e facilmente adaptável - é flexível apenas uma vez. Mas você precisa de um lugar para começar o mapeamento de um modelo de conteúdo. Minha sugestão é começar conversando com as pessoas, ou seja, os autores e os leitores.
Como as pessoas falam sobre o conteúdo internamente? O que as pessoas chamam de coisas diferentes? Você pode fazer um exercício de listagem livre, um método usado por etnógrafos para mapear taxonomias populares. Por exemplo, você pode perguntar:
“Nomeie os diferentes tipos de conteúdo em nossa organização.”
Ou, em um nível mais específico:
“Você pode citar os diferentes tipos de relatórios que temos nesta organização?”
O objetivo desta pesquisa é trazer à tona as taxonomias internalizadas que as pessoas carregam, e não suas opiniões ou sentimentos sobre as coisas (algo que muitas vezes tende a inviabilizar os processos de design). Você não precisa perguntar a muitos antes de ter uma lista bastante exaustiva com a qual possa trabalhar. Você provavelmente descobrirá que partes de sua lista vêm de convenções em seu CMS atual (é bom saber se você precisa fazer alguma remodelação). Agora você deve conversar com seu editor e tentar definir o que eles precisam que o conteúdo faça .
Algumas perguntas que você pode fazer podem ser as seguintes:
- Você precisa usar este conteúdo em mais de um lugar? Onde?
- Quais são as diferentes relações entre os tipos de conteúdo?
- Onde precisamos que o conteúdo seja exibido hoje e amanhã?
- De que maneiras precisamos que o conteúdo seja classificado? A ordenação pode ser feita algoritmicamente, pelo usuário, ou tem que ser manualmente?
- Existem sistemas ou bancos de dados em outros sistemas com os quais podemos sincronizar para evitar duplicação?
- Onde queremos que o conteúdo canônico viva? O SCMS deve ser a fonte para isso, ou apenas aumentar o conteúdo existente, por exemplo, cópia de marketing para produtos que vivem em um sistema de gerenciamento de produtos?
Isso não significa que você tem que jogar fora a arquitetura de informação tradicional com a agora morna água do banho. Ainda faz sentido ter artigos como um tipo de conteúdo, se os artigos fizerem parte da realidade de conteúdo da sua organização. Mas talvez você realmente não precise da convenção abstrata de categorias , porque esses artigos têm referências ao tipo de serviços ou produtos neles. E essa relação permite consultar esses artigos em circunstâncias em que faz sentido, sem exigir que alguém tenha “gerenciamento de categorias de artigos” como parte de sua descrição de trabalho.
O artigo também é o que torna difícil desacoplar completamente o conteúdo da camada de apresentação. Estamos tão acostumados a pensar no layout e no estilo do artigo, mas em uma época em que se espera que você hospede seu próprio conteúdo em seu próprio domínio e depois o distribua para plataformas como medium.com, você já desistiu controle sobre a apresentação visual. Isso nos leva para a próxima estratégia.
3. Contextos de apresentação também são tipos de conteúdo
Esteja pronto para o redesenho
Você também quer ser capaz de se adaptar e alterar rapidamente a estrutura de navegação do seu site, sem ter que reconstruir toda a sua arquitetura de conteúdo ou lutar contra uma interface rígida do tipo pasta. Você também quer ser capaz de ter alguma hierarquia de conteúdo, porque às vezes faz sentido e às vezes fica mais profundo do que dois níveis, onde a maioria das interfaces no departamento de CMSs API-first não fornecem muita ajuda.
Curiosamente, os sistemas de gerenciamento de conteúdo para chatbots tendem a usar estruturas hierárquicas semelhantes para organizar árvores de intenção e fluxos de diálogo. Isso quer dizer que as hierarquias de conteúdo desempenham papéis diferentes em diferentes canais, mas geralmente fornecem maneiras de navegar pelo conteúdo. Uma maneira de abordar isso é criar tipos para navegação, onde você pode organizar o conteúdo por referências e criar rotas para páginas da Web, menus ou caminhos para interfaces de conversação.
Conselho de relacionamento
Referências (ou relacionamentos) é o que torna possível um sistema de conteúdo estruturado, e é realmente o núcleo de tudo com o que estamos lidando quando se trata de conteúdo na web (é a razão pela qual é metaforicamente chamado de web em primeiro lugar). Ser capaz de fazer referências entre bits de conteúdo é algo muito poderoso, mas também pode ser caro em termos de como os back-ends são capazes de gravar e recuperar esses dados. Portanto, você pode ter que pensar de maneira diferente se tiver muitos documentos, pois a escala raramente é gratuita.
Também vale a pena considerar que você nem sempre precisa de uma referência explícita para unir dados; na maioria das vezes isso pode ser feito por critérios que têm a ver com o conteúdo, por exemplo, “dê-me todas as pessoas e todos os edifícios dentro desta geolocalização”. O edifício e as pessoas não precisam ter uma referência explícita entre si, desde que isso esteja implícito em um campo de localização em ambos os tipos de conteúdo.
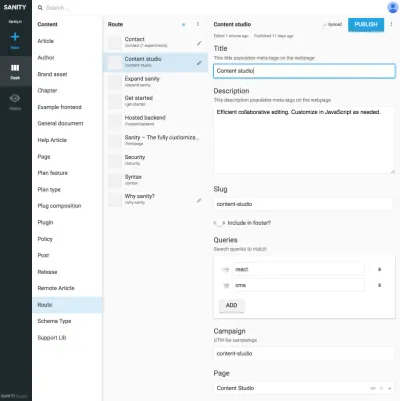
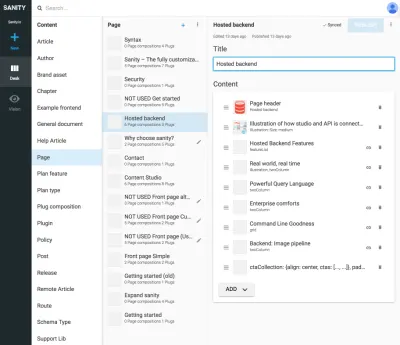
As referências entre tipos de apresentação e outros tipos de conteúdo são úteis quando você não pode deixar que um algoritmo na camada de apresentação junte dados. Pode parecer um pouco complicado desenhar explicitamente esses tipos de apresentação e fazer composições de conteúdo referido, mas é uma solução para um problema que você costuma encontrar com SCMSs: é difícil saber onde o conteúdo está sendo usado. Ao incluir tipos de navegação, você vinculará explicitamente o conteúdo à apresentação, mas não apenas a uma. Isso torna possível raciocinar para trabalhar com estruturas de navegação independentemente do conteúdo ao qual elas levam.
Por exemplo, nas capturas de tela, vinculamos o Google Experiments ao tipo de rotas , permitindo adicionar várias páginas compostas por referências ao conteúdo, o que significa que podemos executar testes A/B com quase nenhuma duplicação de conteúdo. Como também recebemos um aviso se tentarmos excluir o conteúdo referenciado por outros documentos, essa forma de estruturar nos impedirá de excluir algo que não deveríamos.
Os relacionamentos entre os tipos de conteúdo são uma faca de dois gumes. Aumenta a sustentabilidade e é fundamental para evitar a duplicação. Por outro lado, você pode se cortar facilmente porque cria dependências entre o conteúdo, o que (se não for transparente) pode levar a alterações não intencionais nos canais em que seus dados são exibidos. Seria, por exemplo, ruim se pudéssemos remover uma “página” usada por uma “rota” sem aviso prévio.
Isso nos leva à próxima estratégia, que (com certeza!) está parcialmente além do poder do usuário normal a partir de hoje, uma vez que tem a ver com a forma como os diferentes sistemas são arquitetados. Ainda assim, vale a pena pensar.
4. Não coloque rich text em um canto
Rich Text é mais do que HTML
Posso entender por que o HTML tem tanta prevalência no conteúdo digital, mas sei que também vem de alguma coisa; é um subconjunto de SGML, uma forma generalizada de estruturar documentos legíveis por máquina. Como Claire L. Evans aponta no maravilhoso livro “Broad Band: The Untold Story of the Women who made the Internet” (2018), já havia uma comunidade vibrante de pessoas pensando em documentos vinculados quando o HTML foi introduzido. A proposta de Tim Berners-Lee era muito mais simples do que muitos outros sistemas da época, mas provavelmente foi por isso que ela pegou e tornou a web aberta e gratuita possível.
Quando você está em um navegador na world wide web, o HTML é ótimo. Se você é um escritor que deseja publicar algo que acaba em HTML simples, o Markdown é ótimo. Se você deseja que seu conteúdo de rich text seja facilmente integrado a algo que não seja um navegador ou um framework JavaScript popular que permita aumentar HTML com JavaScript em componentes complexos (sim, estamos falando de React e Vue.js) , ter HTML em suas respostas de API começa a ser um pouco incômodo, especialmente se você precisar analisá-lo.
Quase todo mundo faz isso, mesmo os novatos do quarteirão: passei por todos os fornecedores no headlesscms.org e naveguei pela documentação, e também me inscrevi para aqueles que não mencionaram. Com duas exceções, todos eles armazenavam rich text como HTML ou Markdown. Tudo bem se tudo que você faz é usar Jekyll para renderizar um site, ou se você gosta de usar perigosamente SetInnerHTML no React. Mas e se você quiser reutilizar seu conteúdo em interfaces que não estão na web? Ou se você quiser mais controle e funcionalidade em seu editor de rich text? Ou apenas quer que seja mais fácil renderizar seu rich text em uma das estruturas de front-end populares e fazer com que seus componentes cuidem de diferentes partes do seu conteúdo de rich text? Bem, você terá que encontrar uma maneira inteligente de analisar esse markdown ou HTML para o que você precisa ou, mais convenientemente, apenas armazená-lo de forma mais sensata em primeiro lugar.
Por exemplo, e se você quiser enviar seu rich text para uma interface de voz? Sabemos que os assistentes de voz estão aumentando em popularidade. As plataformas mais populares para esses assistentes têm a capacidade de obter o texto do conteúdo falado por meio de APIs. Então você quer tirar proveito de algo como Speech Synthesis Markup Language. Um sistema para texto portátil tem uma abordagem mais agnóstica para rich text, que permite adaptar o mesmo conteúdo para diferentes tipos de interfaces.
Leitura recomendada : Experimentando a interface SpeechSynthesis
Texto portátil como um modelo de Rich Text agnóstico
O texto portátil também é útil quando você está principalmente fazendo conteúdo para a web. E se você quiser ter a possibilidade de aninhar e aumentar seu texto com estruturas de dados, como uma nota de rodapé em rich text ou um comentário editorial embutido? Ou uma frase ou redação alternativa para casos de teste A/B? Markdown e HTML rapidamente ficam aquém, e você terá que confiar na adição de algo como tags de código de acesso especiais, assim como o Wordpress resolveu isso. With portable text, you have an agnostic representation of content structures, without having to marry a certain implementation. Your content ends up being more sustainable and flexible for new redesigns and implementations.
There are also other advantages to portable text, especially if you want to be able to edit content collaboratively and in real time (as you do in Google Docs); you need to store rich text in another structure than HTML. If you do, you'll also be able to take advantage of microservices and bots, such as spaCy, in order to annotate and augment your content without locking the document.
As for now, portable text isn't widely adopted, but we're seeing movements towards it. The specification isn't very complex and can be explored at portabletext.org.
5. Make Sure Your SCMS Is In Service For Your Editors, And Not The Other Way Around
Digital content isn't just used for your organization's online web page leaflets anymore. For most of us, it encapsulates and defines how your organization is understood by the world, both from those within it and those outside: From product copy, micro texts to blog posts, chatbot responses, and strategy documents. We are millions of people that have to log into some CMS every day and navigate interfaces that were imagined twenty years ago with the assumptions of people who have never made much effort to user test or challenge their interfaces. Countless hours have been wasted away trying to fit a modern frontend experience into a page layout machine. Fortunately, this is soon a thing of the past.
As a technology consultant, I had to read through pages of technical specification whenever someone thought it was time to acquire a new CMS for themselves. There were demands from which server architecture it should run on (Windows servers, of course) to their ability to render “carousels” and “being able to edit web pages in place”, despite also requesting a “modular redesign”. When editors had been allowed to contribute to these specifications, they were also often dated to the what the editors had begotten used to. They seemed not aware that they could demand better user experiences, because enterprise software has to be big, lumpy and boring.
This is partly the fault of us making these systems. We tend to communicate technology features and specifications, and less what the everyday situation working with these systems look like. Sure, for a frontend designer, something supporting GraphQL is shorthand for how conveniently she is able to work against the backend, but on a higher level, it's about the systems ability to accommodate for emerging workflows, where a content model could survive visual redesigns and design systems should be resilient to changes of its content.
Questions To Ask Of Your (S)CMS
If we are to embrace design processes, we can't know prior to solving the problem whether the user tasks are best solved by making carousels ( newsflash: most probably not ), or whether A/B-testing makes sense for your case, even though it sounds cool.
Instead, ask questions like this:
- Is it possible, and how exactly will multi-disciplinary teams work with this system?
- How easy is it to change and migrate the content model?
- How does it deal with file and image assets?
- Has the editorial interface been user tested?
- To what extent can the system be configured and customized to special workflows and needs of the editorial team?
- How easy is it to export the content in a moveable format?
- How does the system accommodate for collaboration?
- Can content models be version controlled?
- How easy is it to integrate the system with a larger ecosystem of flowing information?
The goal of these questions is to explore to what degree a content management system allows for a cross-disciplinary team to work effortlessly together, without too many bottle-necks or long deployment cycles. They also push the focus to be more about the content should be doing, and less about how things should look in a given context. Leave that for the design processes, where user testing probably will challenge assumptions one may have when looking into getting a new content system.
There are, of course, many factors in addition to this that probably have to be taken into consideration. The easiest thing to assess is the fiscal cost of software licenses and API-related costs if you are on a hosted service. The invisible cost (in time and attention spent by the team working with the system), is harder to estimate. From my experience, many of the SCMSs in combination with one of the popular frontend frameworks can significantly cut development time and allow for an agile ( there's my coin for the swear jar ) design process. With the caveat that your team is prepared to solve some of the problems that come out of the box with traditional CMSs.
Towards Structured Content
The ways we work with digital content has changed dramatically since the World Wide Web made working with interconnected documents mainstream. Organizations, businesses, and corporations have amassed gigabytes of this content, which now is stuck in rigid page hierarchies, HTML markup, and clunky user interfaces.
Using a Structured Content Management System can be a great way to free your content from a paradigm that begins to feel its age. But it isn't a trivial exercise, and success comes from being able to work multi-disciplinary and put your content model to the test. You need to get rid of some conventions you have grown used to by dealing with CMSs designed to output hierarchical websites. That means that you need to think differently about ordering content, make presentations types in order to make it easier to orchestrate content across multiple channels and to consider how you structure rich text so that it can be used outside of HTML contexts.
This article deals with some of the high-level concerns working with SCMSs. There are, of course, loads of exciting challenges when you start working with this in your team. You have to rethink stuff we've taken for granted for many years, but that's probably a good thing. Because we are forced to evaluate our content, not only from its place on a digital page but from its role in a larger system that works for whatever goals your organization and your users may have.
I believe that we can achieve content models that are more meaningful and easier to sustain in the long run, and that means saving time and expenses. It means more flexibility in terms of inventing new outputs and services, and less tie in with software vendors. Because a well-made Structured Content Management System will make it easy for you to take your content and go elsewhere. And that makes for some interesting competition. Hopefully, all in favor of the users.