Architektura Kubernetes: wszystko, co musisz wiedzieć w 2022 roku
Opublikowany: 2021-01-05Spis treści
O Kubernetes
Kubernetes to platforma typu open source z funkcjami, takimi jak maksymalizacja zasobów, automatyczny proces wdrażania i aktualizacji, automatyczne skalowanie, samonaprawianie, automatyczne wycofywanie i wdrażanie oraz równoważenie obciążenia koordynatorów kontenerów, wykrywanie usług, automatyczne ponowne uruchamianie, automatyczne umieszczanie, i autoreplikacja itp. Kubernetes to nie tylko koordynator kontenerów; jest to również system operacyjny dla aplikacji opartych na chmurze.
Jest jak platforma do uruchamiania aplikacji podobnej do innych aplikacji działających w systemach Windows, MacOS lub Linux z większą elastycznością. Zmniejsza to obciążenie związane z orkiestracją i pozwala programistom całkowicie skoncentrować się na przepływach pracy zorientowanych na kontenery na potrzeby operacji samoobsługowych. Zaletą programistów jest automatyzacja na bardzo wysokim poziomie we wdrażaniu i zarządzaniu aplikacjami. Można go zintegrować z dowolnym środowiskiem w celu zwiększenia możliwości.
Przeczytaj: Wynagrodzenie Kubernetes w Indiach
Architektura Kubernetes
Architektura Kubernetes składa się z warstw: warstwy wyższej i niższej. W tej osobie fizyczne lub wirtualne maszyny są łączone w klaster. Do komunikacji między każdym serwerem używana jest wspólna sieć. Kubernetes ma (co najmniej) jeden master działający jako płaszczyzna kontrolna, rozproszony system pamięci masowej. Wiele węzłów klastra jest również znanych jako Kubelets.
- Mistrz Kubernetes, płaszczyzna kontroli, planuje wdrożenia, udostępnia interfejs API i zarządza całym klastrem Kubernetes.
- Węzeł klastra uruchamia środowisko wykonawcze kontenera, agenta do komunikacji z urządzeniem głównym oraz inne komponenty monitorowania, rejestrowania itp.
Architektura Kubernetes i komponenty Kubernetes są przedstawione na poniższym obrazku.
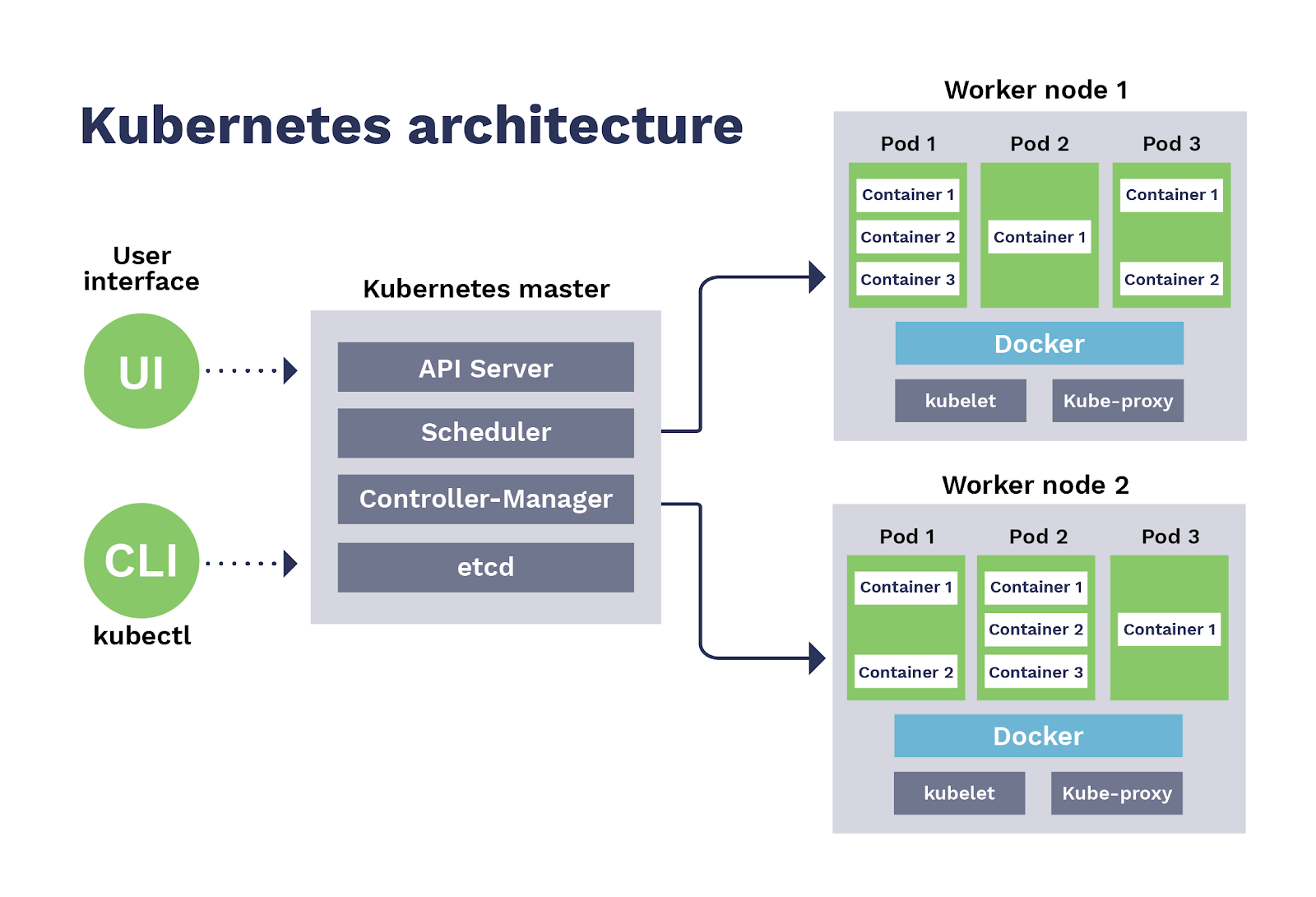
Źródło

Przyjrzyjmy się komponentom Kubernetes .
Komponenty Kubernetes
Mistrz: płaszczyzna kontroli Kubernetes
Master przechowuje dane każdego obiektu w Kubernetes. Ponieważ zarządza całym klastrem, stąd nazywa się go Master. Kontroluje stany obiektów, utrzymuje dopasowanie stanu rzeczywistego systemu do stanu wymaganego, reaguje na zmiany itp.
Zawiera następujące trzy ważne elementy:
- Serwer API Kube : Serwer API Kubernetes
- Kube- Scheduler: planowanie pod w węzłach roboczych
- Kube- Controller: zarządza replikacją pod
Jeśli istnieje wiele węzłów głównych, te komponenty są replikowane we wszystkich węzłach głównych.
Orkiestracja cyklu życia dla różnych aplikacji, które obejmują aktualizacje, skalowanie itp., jest wykonywana przez API Server. Działa jako brama dla klientów spoza klastra. Serwer API przeprowadza uwierzytelnianie. Działa również jako pośrednik do strąków i węzłów.
Administrator wykonuje następujące zadania:
- Uruchamianie podstawowych pętli sterowania
- Dokonywanie zmian statusu jazdy w kierunku wymaganego stanu.
- Oglądanie stanu klastra
Oferuje również routing, usługi przechowywania, równoważenie obciążenia, usługi sieciowe DNS, instancje maszyn wirtualnych poprzez integrację z chmurami publicznymi. Różne kontrolery, które sterują stanem autoskalowania, węzłów, usług i zasobników, przestrzeni nazw.
Planowanie kontenerów we wszystkich węzłach jest wykonywane przez Scheduler w klastrze; biorąc pod uwagę różne ograniczenia/gwarancje zasobów lub specyfikacje antypowinowactwa/powinowactwa.
Taksonomia płaszczyzny kontrolnej Kubernetes jest pokazana poniżej:
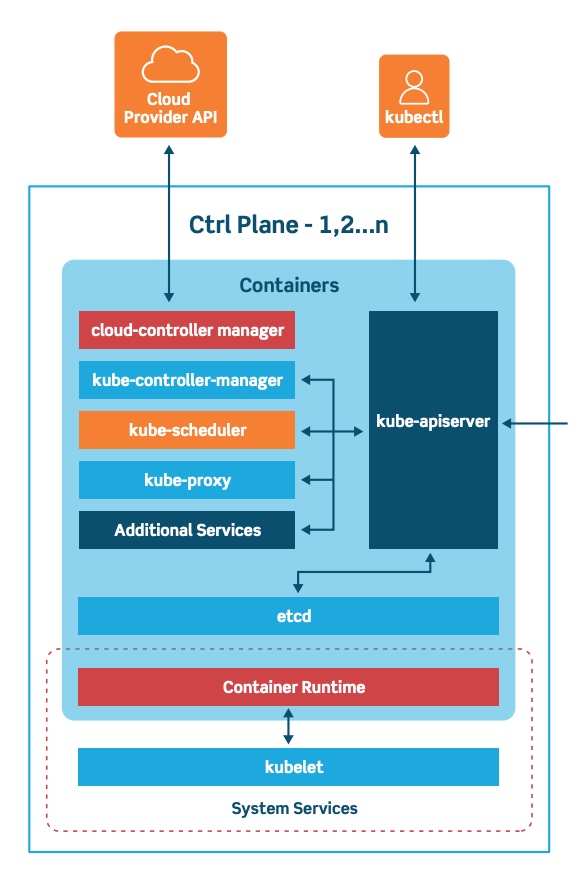
Źródło
Węzły klastra: Kubelets
Kubelety to różne maszyny, które są odpowiedzialne za uruchamianie kontenerów. Master zarządza węzłami klastra. Jest również nazywany Minionem. Węzły klastra są uważane za podstawowy kontroler Kubernetes. Napędza Dockera, warstwę wykonawczą kontenerów.
Zawiera następujące składniki:
- Pod: Grupa kontenerów
- Docker: technologia oparta na kontenerach, przestrzeń użytkownika systemu operacyjnego
- Kubelet: agenci kontenera odpowiedzialni za utrzymanie zestawu podów.
- Kube-proxy: kieruje ruch przychodzący do węzła z usługi.
Taksonomia węzłów klastra Kubernetes jest pokazana poniżej:
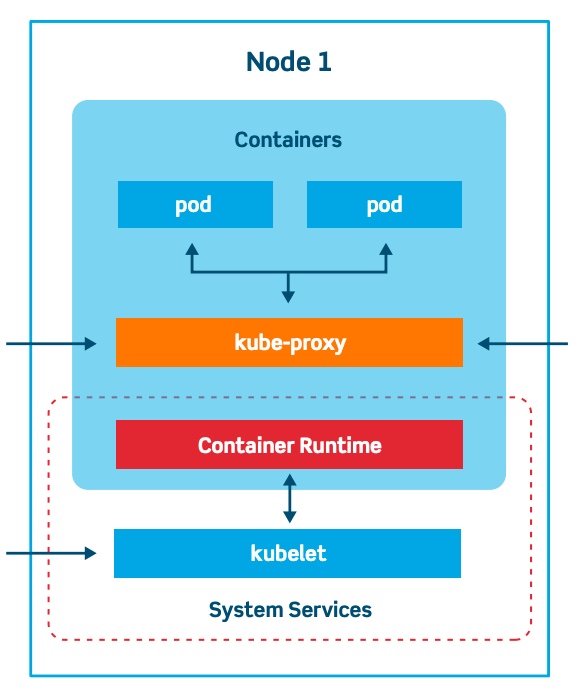
Źródło
Pody i usługi
Pody to ważna koncepcja w Kubernetes, z którą współpracują programiści. Reprezentuje działający proces. Może obsługiwać stosy aplikacji, które są zintegrowane pionowo, takie jak aplikacje WordPress LAMP. Poniżej podano różne typy strąków:
| Typ kapsuły | Funkcjonalność |
| Zestaw replik | Prosty typ kapsuły Zapewnia działanie stałych strąków |
| Zastosowanie | Deklaratywny sposób zarządzania pod za pomocą ReplicaSet Uwzględniono aktualizacje kroczące i mechanizmy wycofywania. |
| Zestaw stanowy | Zarządza podami, które powinny się utrzymywać |
| Zbiór demonów | Zapewnia, że każdy węzeł uruchamia instancję pod. Zarządza usługami klastrowymi, takimi jak przekazywanie logów i monitorowanie kondycji. |
| CronJob i Job | Wykonuje zadania, które są krótkotrwałe jako harmonogram |
Pod może składać się z wielu kontenerów i woluminów zewnętrznych. Taksonomia strąka jest pokazana na poniższym schemacie:
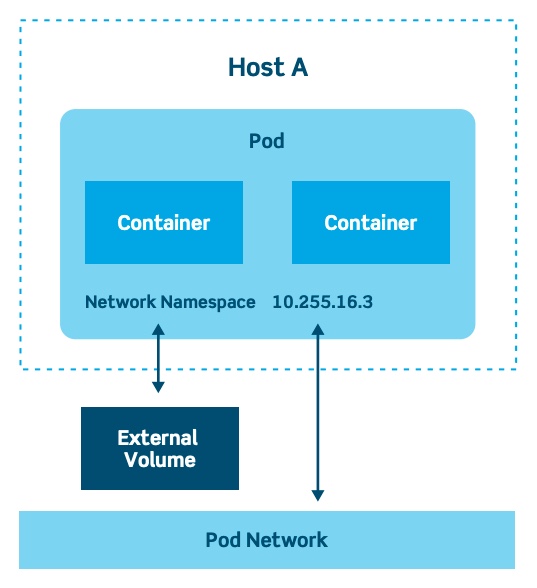
Źródło
Usługi śledzą pody. Do definiowania skojarzeń pod i usług zamiast przypisywania adresów IP używane są selektory lub etykiety. Upraszcza to dodawanie kapsuł do obsługi i wydawanie nowych wersji. Poniżej przedstawiono różne rodzaje usług:
| Rodzaj usługi | Funkcjonalność |
| IP klastra | Typ domyślny; Udostępnia usługę na wewnętrznym adresie IP i sprawia, że usługa jest osiągalna |
| NodePort | Umożliwia programistom skonfigurowanie własnych systemów równoważenia obciążenia |
| Load Balancer | Automatyzuje ich konfigurację |
| Nazwa zewnętrzna | Powszechnie używany do tworzenia usług w Kubernetes. |
Typowym wdrożeniem w chmurze jest typ LoadBalancer. Kubernetes obsługuje abstrakcję wysokiego poziomu Ingress w celu rozwiązywania złożoności. Użytkownicy mogą wyświetlać różne usługi w ramach tego samego adresu IP, korzystając z tych samych load balancerów.
Czytaj więcej: Openshift vs Kubernetes: różnica między Openshift a Kubernetes
Sieć Kubernetes
Przeważnie CNI (Container Network Interface) służy do zasłaniania podstawowej sieci. Można również użyć Calico, w pełni kierowanej opcji. W obu opcjach komunikacja odbywa się w sieci pod klastra i jest kontrolowana przez Calico lub Flannel (dostawca CNI). Kontenery mogą komunikować się w pod za pośrednictwem hosta lokalnego bez żadnych ograniczeń. Przenoszenie ze źródeł zewnętrznych do usług lub podów do usług odbywa się za pośrednictwem Kube-proxy.
Pamięć trwała
Katalog zawierający pewne dane jest określany jako Woluminy w Kubernetes. Katalogi są dostępne dla podów. W Kubernetes istnieje wiele typów pamięci. Kontenery w kapsułce mogą zajmować dowolne miejsce do przechowywania. Usługi chmury publicznej, takie jak NFS, Amazon Elastic Block Store, Iscsi, CephFS itp., są używane do montowania plików i blokowania pamięci masowej do kapsuły. PV (PersistentVolumes) to obiekty obejmujące cały klaster, które są powiązane z istniejącymi zasobami pamięci masowej.
W przestrzeni nazw żądanie użycia magazynu jest inicjowane przez PersistentVolumeClaim. Różne stany PV są dostępne, powiązane, zwolnione i nieudane. StorageClasses to warstwa abstrakcji. Rozróżnia podstawową jakość przechowywania i oddziela różne cechy. Pod może dynamicznie żądać nowego magazynu za pomocą StorageClasses i PersistentVolumeClaim.

Źródło
Usługi wyszukiwania i publikowania
W zależności od wersji klastra Kubernetes zależy od Kube-DNS lub CoreDNS do wykrywania usług. Te zintegrowane usługi DNS tworzą, aktualizują i usuwają rekordy DNS. Pomaga aplikacjom kierować inne pody i usługi za pomocą spójnego i prostego schematu nazewnictwa.
Przykład ( źródło )
W przypadku usługi Kubernetes rekord DNS może mieć postać service.namespace.svc.cluster.local
Rekord DNS, pod może mieć: 10.32.0.125.namespace.pod.cluster.local
Źródło
Przestrzenie nazw
Klaster fizyczny zawierający klastry wirtualne nosi nazwę Przestrzenie nazw. Zapewnia oddzielne środowisko wirtualne wielu użytkownikom wraz z odpowiednimi prawami dostępu do obiektów Kubernetes.
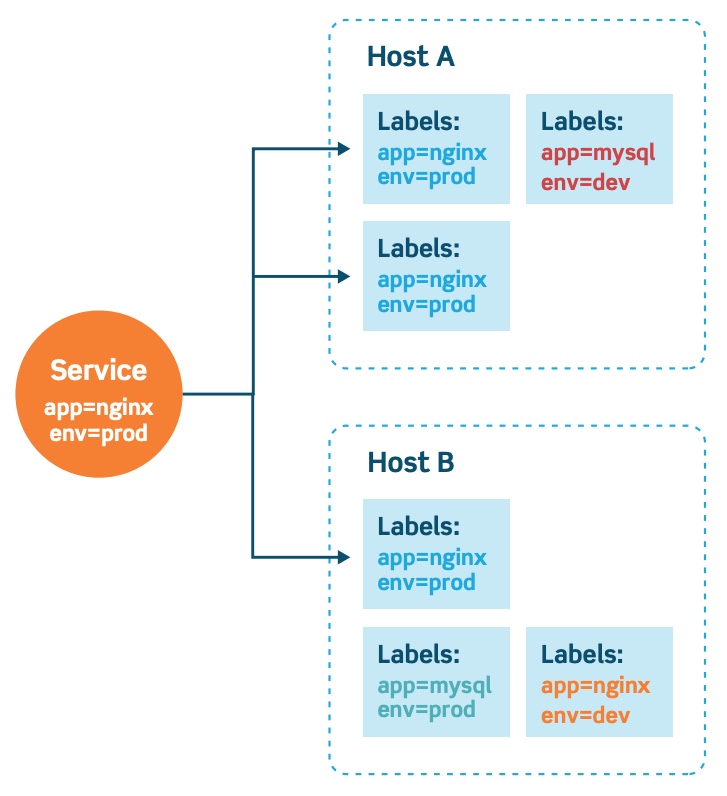
Etykiety
Etykiety służą do rozróżniania zasobów znajdujących się w pojedynczej przestrzeni nazw. Atrybuty są definiowane przez pary kluczy lub wartości. Etykiety służą do mapowania struktur organizacyjnych na obiekty Kubernetes. Może opisywać środowisko, stan wydania, warstwę aplikacji lub identyfikację klientów. Zapobiega twardemu łączeniu obiektów.
Adnotacje
Adnotacje służą do dodawania dowolnych niezidentyfikowanych bagaży lub metadanych do obiektów. Jest używany jako deklaratywne narzędzie konfiguracyjne.
Trzeba przeczytać: Kubernetes vs. Docker: podstawowe różnice, które powinieneś wiedzieć
Zdobądź stopnie inżynierii oprogramowania z najlepszych światowych uniwersytetów. Zdobywaj programy Executive PG, Advanced Certificate Programs lub Masters Programs, aby przyspieszyć swoją karierę.
Wniosek
Technologia Kubernetes szybko się rozwija i jest opłacalnym rozwiązaniem na przyszłość. Zapewnia dużą stabilność aplikacji.
Wszystkie podstawowe koncepcje architektury Kubernetes i komponentów Kubernetes są wyjaśnione w tym artykule.
Jeśli chcesz dowiedzieć się więcej o Kubernetes, big data, zapoznaj się z programem Executive PG UpGrad i IIIT-B w zakresie tworzenia pełnego stosu oprogramowania , który jest przeznaczony dla pracujących profesjonalistów i oferuje ponad 500 godzin rygorystycznych szkoleń, ponad 9 projektów i zadania, status absolwentów IIIT-B, praktyczne praktyczne projekty zwieńczenia i pomoc w pracy z najlepszymi firmami.