Jak usunąć zduplikowane elementy z CSV lub dowolnego innego pliku w Javie?
Opublikowany: 2021-05-28
Znalezienie zduplikowanych wierszy z pliku nie jest trudnym problemem. Ale czasami podczas rozmowy kwalifikacyjnej ludzie czasami są bardzo zdezorientowani co do metody, której muszą użyć.
W tym samouczku omówimy kroki, jak usunąć duplikaty z pliku CSV i dowolnego innego pliku.
Zacznijmy:
Krok 1.
Utwórz plik CrunchifyFindDuplicateCSV .java
Krok 2.
- Umieść poniższy kod w pliku.
- Do odczytu plików używamy BufferedReader.
- Pojedynczo dodaj linie do HashSet.
- Klasa HashSet implementuje interfejs Set, wspierany przez tabelę skrótów (w rzeczywistości instancję HashMap). Nie daje żadnych gwarancji co do kolejności iteracji zestawu; w szczególności nie gwarantuje, że zamówienie pozostanie niezmienne w czasie. Ta klasa zezwala na element null.
- Użyj metody add(), aby sprawdzić, czy linia jest już obecna w Set, czy nie.
- Dodaje określony element do tego zestawu, jeśli nie jest jeszcze obecny. Bardziej formalnie, dodaje określony element e do tego zestawu, jeśli ten zestaw nie zawiera elementu e2 takiego, że Objects.equals(e, e2). Jeśli ten zestaw zawiera już element, wywołanie pozostawia zestaw bez zmian i
returns false.
- Dodaje określony element do tego zestawu, jeśli nie jest jeszcze obecny. Bardziej formalnie, dodaje określony element e do tego zestawu, jeśli ten zestaw nie zawiera elementu e2 takiego, że Objects.equals(e, e2). Jeśli ten zestaw zawiera już element, wywołanie pozostawia zestaw bez zmian i
- Po pominięciu wypiszemy tę linię jako pominiętą linię.
plik crunchify.csv
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
name city number age kedar kapan 9843875 23 sedai ktm 97798433 23 ayush kalopul 9856324 12 dipal ratopul 9842567 34 malla setiopul 1258496 33 ayush kalopul 9856324 12 babin karki hariyopul 32589 11 raju dhading 58432 44 sedai ktm 97798433 23 Crunchify , LLC PayPal . com Google . com Twitter . com FaceBook . com Crunchify , LLC Google . com Visa . com MasterCard . com Citi . com California Austin California |
CrunchifyFindDuplicateCSV.java
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
package crunchify . com . tutorial ; import java . io . BufferedReader ; import java . io . FileNotFoundException ; import java . io . FileReader ; import java . io . IOException ; import java . util . HashSet ; /** * @author Crunchify.com * How to Remove Duplicate Elements from CSV file in Java? */ public class CrunchifyFindDuplicateCSV { public static void main ( String [ ] argv ) { String crunchifyCSVFile = "/Users/Shared/crunchify.csv" ; // Reads text from a character-input stream, buffering characters so as to provide for the // efficient reading of characters, arrays, and lines. BufferedReader crunchifyBufferReader = null ; String crunchifyLine = "" ; // This class implements the Set interface, backed by a hash table (actually a HashMap instance). // It makes no guarantees as to the iteration order of the set; in particular, it does not guarantee that the order will // remain constant over time. This class permits the null element. HashSet < String > crunchifyAllLines = new HashSet < > ( ) ; try { crunchifyBufferReader = new BufferedReader ( new FileReader ( crunchifyCSVFile ) ) ; while ( ( crunchifyLine = crunchifyBufferReader . readLine ( ) ) ! = null ) { if ( crunchifyAllLines . add ( crunchifyLine ) ) { crunchifyLog ( "Processed line: " + crunchifyLine ) ; } else if ( ! crunchifyIsNullOrEmpty ( crunchifyLine ) ) { crunchifyLog ( "--------------- Skipped line: " + crunchifyLine ) ; } } } catch ( FileNotFoundException e ) { e . printStackTrace ( ) ; } catch ( IOException e ) { e . printStackTrace ( ) ; } finally { if ( crunchifyBufferReader ! = null ) { try { crunchifyBufferReader . close ( ) ; } catch ( IOException e ) { e . printStackTrace ( ) ; } } } } // Check if String with spaces is Empty or Null public static boolean crunchifyIsNullOrEmpty ( String crunchifyString ) { if ( crunchifyString ! = null && !crunchifyString.trim().isEmpty()) return false; return true ; } // Simple method for system outs private static void crunchifyLog ( String s ) { System . out . println ( s ) ; } } // Linux command to remove duplicate lines from file: // $ sort -u /Users/Shared/crunchify.csv |

Uruchommy program Java w IntelliJ IDE.
Oto wynik:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
Processed line : name city number age Processed line : kedar kapan 9843875 23 Processed line : sedai ktm 97798433 23 Processed line : ayush kalopul 9856324 12 Processed line : dipal ratopul 9842567 34 Processed line : malla setiopul 1258496 33 --------------- Skipped line : ayush kalopul 9856324 12 Processed line : babin karki hariyopul 32589 11 Processed line : raju dhading 58432 44 --------------- Skipped line : sedai ktm 97798433 23 Processed line : Processed line : Crunchify , LLC Processed line : PayPal . com Processed line : Google . com Processed line : Twitter . com Processed line : FaceBook . com --------------- Skipped line : Crunchify , LLC --------------- Skipped line : Google . com Processed line : Visa . com Processed line : MasterCard . com Processed line : Citi . com Processed line : California Processed line : Austin --------------- Skipped line : California Process finished with exit code 0 |
Mam nadzieję, że ten program Java będzie przydatny do wyszukiwania zduplikowanych wierszy w CSV lub dowolnym innym pliku.
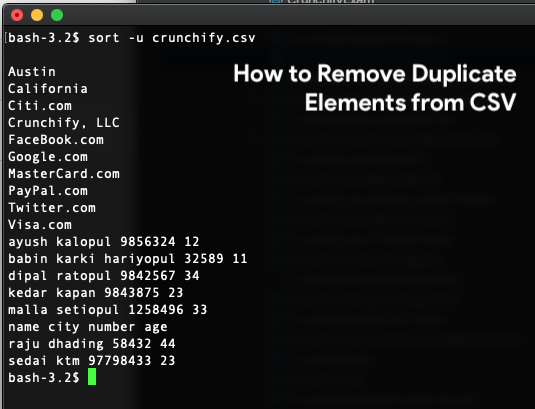
Jak znaleźć zduplikowane wiersze w CSV za pomocą polecenia Linux?
|
1 |
$ sort - u / Users / Shared / crunchify . csv |
Wynik: