
Keras를 사용한 딥 러닝: Keras를 사용한 신경망 훈련 [코드 포함]
게시 됨: 2020-12-24Keras는 신경망 및 딥 러닝 프레임워크와 함께 작동하는 API를 제공하는 Python 라이브러리입니다. 케라스는 파이썬에서 다양한 딥 러닝 애플리케이션을 다룰 때 매우 편리한 함수와 모듈을 제공합니다.
이 튜토리얼을 마치면 다음에 대한 지식을 갖게 될 것입니다.
- 케라스란?
- 케라스 API
- Keras에서 신경망 훈련
목차
케라스란?
딥러닝을 하기 위해 초기에 가장 많이 사용한 라이브러리는 초보자가 다루기 힘든 Tensorflow 1.x였습니다. 기본적인 1계층 네트워크를 만들기 위해서는 많은 코딩이 필요했습니다. 그러나 Keras를 사용하면 신경망의 구조를 만든 다음 훈련 및 추적하는 전체 프로세스가 매우 쉬워졌습니다.
Keras는 Tensorflow, Theano 및 CNTK 백엔드에서 실행할 수 있는 고급 API입니다. 사용자 친화적인 고급 API를 사용하여 신경망을 사용하여 실험을 실행할 수 있는 기능을 제공합니다. 또한 CPU 및 GPU에서 실행할 수 있습니다.
케라스 API
Keras에는 신경망 모델링 및 교육을 처리하기 위한 10가지 API 모듈이 있습니다. Keras가 제공하는 모든 것을 이해하기 위해 각각을 살펴보겠습니다.
모델
Models API는 레이어를 추가/제거하여 복잡한 신경망을 구축하는 기능을 제공합니다. 모델은 Sequential일 수 있습니다. 즉, 레이어가 단일 입력 및 출력으로 순차적으로 쌓입니다. 모델은 완전히 사용자 정의 가능한 모델로 기능적일 수도 있습니다. 이것은 업계에서 주로 사용하는 것입니다.

API에는 옵티마이저 및 손실 함수와 함께 모델을 컴파일하는 방법, 모델에 맞는 방법, 새 데이터를 평가하고 예측하는 방법을 제공하는 교육 모듈도 있습니다. 또한 배치 데이터에 대한 교육, 테스트 및 예측 방법도 있습니다. Models API에는 모델의 저장 및 직렬화 기능도 있습니다.
레이어
레이어는 모든 신경망의 빌딩 블록입니다. Layers API는 신경망 아키텍처를 구축하기 위한 완전한 방법 세트를 제공합니다. Layers API에는 사용자 정의 가중치 및 이니셜라이저를 사용하여 사용자 정의 레이어를 구축하는 데 필요한 메서드가 포함된 기본 레이어 클래스가 있습니다.
여기에는 ReLU, Sigmoid, Tanh, Softmax 등과 같은 다양한 활성화 함수로 구성된 Layer Activations 클래스가 포함되어 있습니다. Layer Weight Initializers 클래스는 다양한 방법을 사용하여 가중치를 초기화하는 메서드를 제공합니다.
또한 Dense layer, Activation Layer, Embedding layer 등과 같은 core layer를 추가하는데 필요한 클래스로 구성된 Core Layers 클래스로 구성되어 있습니다. Convolution Layer 클래스는 Convolution layer의 종류를 추가하기 위한 다양한 방법을 제공합니다. Pooling Layers 클래스에는 Max Pooling, Average Pooling, Global Max Pooling 및 Global Average Pooling과 같은 다양한 유형의 pooling에 필요한 메소드가 포함되어 있습니다.
콜백
콜백은 모델의 학습 프로세스를 추적하는 방법입니다. 콜백이 활성화되면 에포크 또는 배치가 끝나기 전이나 후에 다양한 작업을 수행할 수 있습니다. 콜백으로 다음을 수행할 수 있습니다.
- TensorFlow Board에 메트릭을 기록하여 교육 메트릭 모니터링
- 주기적으로 모델을 디스크에 저장
- 특정 epoch 후에도 손실이 크게 감소하지 않는 경우 조기 중지
- 훈련 중 모델의 내부 상태 및 통계 보기
데이터세트 전처리
데이터는 일반적으로 원시 형식이고 정렬된 디렉토리에 있으며 피팅을 위해 모델에 공급하기 전에 사전 처리해야 합니다. 이미지 데이터 전처리 클래스에는 이러한 전용 기능이 많이 있습니다. 예를 들어 이미지 데이터는 img_to_array 함수를 사용할 수 있는 숫자 배열에 있어야 합니다. 또는 이미지가 디렉토리 및 하위 폴더 내에 있는 경우 image_dataset_from_directory 함수를 사용할 수 있습니다.
데이터 전처리 API에는 시계열 데이터 및 텍스트 데이터에 대한 클래스도 있습니다.
옵티마이저
옵티마이저는 모든 신경망의 중추입니다. 모든 신경망은 예측에 가장 적합한 가중치를 찾기 위해 손실 함수를 최적화하는 작업을 합니다. 최적의 가중치를 찾기 위해 약간 다른 기술을 따르는 여러 종류의 옵티마이저가 있습니다. 이러한 모든 옵티마이저는 Optimizers API(SGD, RMSProp, Adam, Adadelta, Adagrad, Adamax, Nadal, FTRL)에서 사용할 수 있습니다.
사상자 수
모델을 컴파일할 때 손실 함수를 지정해야 합니다. 이 손실 함수는 컴파일 메서드에서 매개변수로도 전달된 최적화 프로그램에 의해 최적화됩니다. 세 가지 주요 손실 클래스는 확률적 손실, 회귀 손실, 힌지 손실입니다.
측정항목
메트릭은 테스트 데이터에 대한 성능을 수량화하기 위해 모든 ML 모델에서 사용됩니다. 메트릭은 테스트 데이터에 사용된다는 점을 제외하면 손실 함수와 유사합니다. Accuracy, Binary Accuracy, Categorical Accuracy 등과 같은 많은 Accuracy 메트릭이 있습니다. 여기에는 Binary Cross Entropy, Categorical Cross Entropy 등과 같은 확률적 메트릭도 포함됩니다. AUC, 정밀도, 재현율 등
이러한 분류 메트릭 외에도 Mean Squared Error, Root Mean Squared Error, Mean Absolute Error 등과 같은 회귀 메트릭도 있습니다.
더 읽어보기: Keras와 TensorFlow의 기능
케라스 애플리케이션
Keras 애플리케이션 클래스는 사전 훈련된 가중치와 함께 사전 구축된 일부 모델로 구성됩니다. 이러한 사전 훈련된 모델은 Transfer Learning 프로세스에 사용됩니다. 이러한 사전 학습된 모델은 아키텍처, 레이어 수, 학습 가능한 가중치 등에 따라 다릅니다. 그 중 일부는 Xception, VGG16, Resnet50, MobileNet 등입니다.
Keras로 신경망 훈련하기
Keras의 데이터 세트 클래스에서 사용할 수 있는 MNIST와 같은 간단한 데이터 세트를 고려해 보겠습니다. 0-9까지의 손글씨 이미지를 분류하기 위한 간단한 순차 컨볼루션 신경망을 만들어 보겠습니다.

| #데이터세트 불러오기 keras.datasets 에서 가져오기 mnist (x_train, y_train), (x_test, y_test) = mnist.load_data() |
각 픽셀을 255로 나누어 데이터 세트를 정규화합니다. 또한 CNN 모델에 공급하기 전에 이미지를 4차원으로 변환해야 합니다.
| x_train = x_train.astype( 'float32' ) x_test = x_test.astype( 'float32' ) x_train /= 255 x_test /= 255 x_train = X_train.reshape(X_train.shape[ 0 ], 28 , 28 , 1 ) x_test = X_test.reshape(X_test.shape[ 0 ], 28 , 28 , 1 ) |
클래스를 모델에 공급하기 전에 레이블 인코딩이 필요합니다. Keras의 Utils 클래스를 사용하여 이를 수행합니다.
| keras.utils 에서 _categorical로 가져오기
|
이제 Sequential API를 사용하여 모델 생성을 시작할 수 있습니다.
| keras.models 에서 가져오기 순차 keras.layers 에서 가져오기 Conv2D, MaxPool2D, Dense, Flatten, Dropout model = Sequential() model.add(Conv2D(filters= 32 , kernel_size=( 5 , 5 ), activation= 'relu' , input_shape=x_train.shape[ 1 :))) model.add(MaxPool2D(pool_size=( 2 , 2 ))) model.add(탈락(비율= 0.25 )) model.add(Conv2D(filters= 64 , kernel_size=( 3 , 3 ), activation= 'relu' )) model.add(MaxPool2D(pool_size=( 2 , 2 ))) model.add(탈락(비율= 0.25 )) model.add(평탄화()) model.add(밀도( 256 , 활성화= 'relu' )) model.add(탈락(비율= 0.5 )) model.add(Dense( 10 , 활성화= 'softmax' )) |
위의 코드에서는 순차 모델을 선언한 다음 여기에 여러 레이어를 추가합니다. Convolutional layer, Max Pooling layer, regularization을 위한 dropout layer가 뒤따릅니다. 나중에 Flatten 레이어를 사용하여 출력을 Flatten하고 마지막 레이어는 10개의 노드가 있는 완전히 연결된 조밀한 레이어입니다.
다음으로 손실 함수, 옵티마이저 및 메트릭을 전달하여 컴파일해야 합니다.
| 모델.컴파일( 손실= 'categorical_crossentropy' , 옵티마이저 = '아담' , 측정항목=[ '정확도' ] ) |
이제 모델의 훈련 세트와 정확도를 높이기 위해 원본 이미지에서 증강 이미지를 추가해야 합니다. ImageDataGenerator 함수를 사용하여 이를 수행합니다.
| keras.preprocessing.image 에서 ImageDataGenerator 가져오기 datagen = ImageDataGenerator( 회전 범위= 10 , 확대/축소 범위= 0.1 , width_shift_range= 0.1 , height_shift_range= 0.1 ) |
이제 모델이 컴파일되고 이미지가 보강되었으므로 훈련 프로세스를 시작할 수 있습니다. 위에서 이미지 데이터 생성기를 사용했으므로 그냥 맞춤이 아닌 fit_generator 메서드를 사용합니다.
| 에포크 = 3 배치 크기 = 32 히스토리 = model.fit_generator( datagen.flow(x_train, y_train, batch_size=batch_size), epochs=epochs, validation_data=(x_test, y_test), steps_per_epoch=x_train.shape[ 0 ]//batch_size ) |
교육 과정의 결과는 다음과 같습니다.
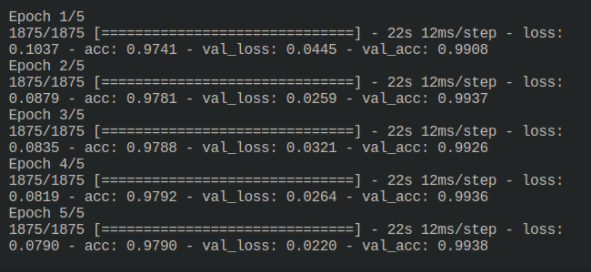
3이제 모델이 학습되었으며 보이지 않는 테스트 데이터에서 실행하여 평가할 수 있습니다.
관련 읽기: Keras를 사용한 딥 러닝 및 신경망
가기 전에
이 튜토리얼에서 우리는 Keras가 얼마나 잘 구조화되어 있고 복잡한 신경망을 쉽게 구축할 수 있는지 보았습니다. Keras는 이제 Tensorflow 2.x로 래핑되어 더 많은 기능을 제공합니다. 더 많은 예제를 시도하고 Keras의 기능과 특징을 살펴보십시오.
기계 학습에 대해 자세히 알아보려면 IIIT-B 및 upGrad의 기계 학습 및 AI PG 디플로마를 확인하세요. 이 PG 디플로마는 일하는 전문가를 위해 설계되었으며 450시간 이상의 엄격한 교육, 30개 이상의 사례 연구 및 과제, IIIT- B 동문 자격, 5개 이상의 실용적인 실습 캡스톤 프로젝트 및 최고의 기업과의 취업 지원.