
HTTP/3 : Améliorations des performances (Partie 2)
Publié: 2022-03-10Bienvenue à nouveau dans cette série sur le nouveau protocole HTTP/3. Dans la partie 1, nous avons examiné pourquoi nous avons exactement besoin de HTTP/3 et du protocole QUIC sous-jacent, et quelles sont leurs principales nouvelles fonctionnalités.
Dans cette deuxième partie, nous allons zoomer sur les améliorations de performances que QUIC et HTTP/3 apportent au tableau pour le chargement des pages web. Cependant, nous serons également quelque peu sceptiques quant à l'impact que nous pouvons attendre de ces nouvelles fonctionnalités dans la pratique.
Comme nous le verrons, QUIC et HTTP/3 ont en effet un grand potentiel de performances web, mais principalement pour les utilisateurs sur des réseaux lents . Si votre visiteur moyen est sur un réseau câblé ou cellulaire rapide, il ne bénéficiera probablement pas beaucoup des nouveaux protocoles. Cependant, notez que même dans les pays et les régions où les liaisons montantes sont généralement rapides, les 1 % à 10 % les plus lents de votre audience (les soi-disant 99e ou 90e centiles ) ont encore beaucoup à gagner. En effet, HTTP/3 et QUIC aident principalement à résoudre les problèmes quelque peu rares mais potentiellement à fort impact qui peuvent survenir sur Internet d'aujourd'hui.
Cette partie est un peu plus technique que la première, bien qu'elle décharge la plupart des éléments vraiment profonds vers des sources extérieures, en se concentrant sur l'explication de l'importance de ces éléments pour le développeur Web moyen.
- Partie 1 : Historique HTTP/3 et concepts de base
Cet article s'adresse aux personnes qui découvrent HTTP/3 et les protocoles en général, et il aborde principalement les bases. - Partie 2 : Fonctionnalités de performances HTTP/3
Celui-ci est plus approfondi et technique. Les personnes qui connaissent déjà les bases peuvent commencer ici. - Partie 3 : Options pratiques de déploiement HTTP/3
Ce troisième article de la série explique les défis liés au déploiement et au test de HTTP/3 vous-même. Il détaille comment et si vous devez également modifier vos pages Web et vos ressources.
Une introduction à la vitesse
Discuter des performances et de la « vitesse » peut rapidement devenir complexe, car de nombreux aspects sous-jacents contribuent au chargement « lent » d'une page Web. Comme nous traitons ici de protocoles réseau, nous nous intéresserons principalement aux aspects réseau, dont deux sont les plus importants : la latence et la bande passante.
La latence peut être grossièrement définie comme le temps nécessaire pour envoyer un paquet du point A (par exemple, le client) au point B (le serveur) . Elle est physiquement limitée par la vitesse de la lumière ou, pratiquement, la vitesse à laquelle les signaux peuvent se déplacer dans les fils ou à l'air libre. Cela signifie que la latence dépend souvent de la distance physique réelle entre A et B.
Sur terre, cela signifie que les latences typiques sont conceptuellement faibles, entre environ 10 et 200 millisecondes. Cependant, ce n'est qu'un moyen : les réponses aux paquets doivent également revenir. La latence bidirectionnelle est souvent appelée temps d'aller-retour (RTT) .
En raison de fonctionnalités telles que le contrôle de la congestion (voir ci-dessous), nous aurons souvent besoin de plusieurs allers-retours pour charger même un seul fichier. Ainsi, même de faibles latences inférieures à 50 millisecondes peuvent entraîner des retards considérables. C'est l'une des principales raisons pour lesquelles les réseaux de diffusion de contenu (CDN) existent : ils placent les serveurs physiquement plus près de l'utilisateur final afin de réduire au maximum la latence, et donc les retards.
La bande passante peut alors être considérée comme le nombre de paquets qui peuvent être envoyés en même temps . C'est un peu plus difficile à expliquer, car cela dépend des propriétés physiques du support (par exemple, la fréquence des ondes radio utilisées), du nombre d'utilisateurs sur le réseau, et aussi des appareils qui interconnectent différents sous-réseaux (car ils ne peut généralement traiter qu'un certain nombre de paquets par seconde).
Une métaphore souvent utilisée est celle d'un tuyau utilisé pour transporter l'eau. La longueur du tuyau est la latence, tandis que la largeur du tuyau est la bande passante. Sur Internet, cependant, nous avons généralement une longue série de canaux connectés , dont certains peuvent être plus larges que d'autres (conduisant à ce que l'on appelle des goulots d'étranglement au niveau des liens les plus étroits). Ainsi, la bande passante de bout en bout entre les points A et B est souvent limitée par les sous-sections les plus lentes.
Bien qu'une parfaite compréhension de ces concepts ne soit pas nécessaire pour la suite de cet article, il serait bon d'avoir une définition commune de haut niveau. Pour plus d'informations, je vous recommande de consulter l'excellent chapitre d'Ilya Grigorik sur la latence et la bande passante dans son livre High Performance Browser Networking .
Contrôle de la congestion
Un aspect des performances concerne l' efficacité avec laquelle un protocole de transport peut utiliser la totalité de la bande passante (physique) d'un réseau (c'est-à-dire, en gros, combien de paquets par seconde peuvent être envoyés ou reçus). Cela affecte à son tour la vitesse à laquelle les ressources d'une page peuvent être téléchargées. Certains prétendent que QUIC fait cela bien mieux que TCP, mais ce n'est pas vrai.
Savais-tu?
Une connexion TCP, par exemple, ne se contente pas de commencer à envoyer des données à pleine bande passante, car cela pourrait finir par surcharger (ou congestionner) le réseau. En effet, comme nous l'avons dit, chaque lien réseau ne dispose que d'une certaine quantité de données qu'il peut (physiquement) traiter chaque seconde. Donnez-lui plus et il n'y a pas d'autre choix que de supprimer les paquets excessifs, entraînant une perte de paquets .
Comme indiqué dans la partie 1, pour un protocole fiable comme TCP, le seul moyen de récupérer d'une perte de paquets est de retransmettre une nouvelle copie des données, ce qui prend un aller-retour. Surtout sur les réseaux à latence élevée (par exemple, avec un RTT de plus de 50 millisecondes), la perte de paquets peut sérieusement affecter les performances.
Un autre problème est que nous ne savons pas à l'avance combien sera la bande passante maximale . Cela dépend souvent d'un goulot d'étranglement quelque part dans la connexion de bout en bout, mais nous ne pouvons pas prédire ou savoir où cela se trouvera. Internet ne dispose pas non plus (encore) de mécanismes pour signaler les capacités de liaison aux terminaux.
De plus, même si nous connaissions la bande passante physique disponible, cela ne signifierait pas que nous pourrions tout utiliser nous-mêmes. Plusieurs utilisateurs sont généralement actifs simultanément sur un réseau, chacun d'entre eux ayant besoin d'une part équitable de la bande passante disponible.
En tant que telle, une connexion ne connaît pas la quantité de bande passante qu'elle peut utiliser en toute sécurité ou équitablement à l'avance, et cette bande passante peut changer à mesure que les utilisateurs rejoignent, quittent et utilisent le réseau. Pour résoudre ce problème, TCP essaiera constamment de découvrir la bande passante disponible au fil du temps en utilisant un mécanisme appelé contrôle de congestion .
Au début de la connexion, il n'émet que quelques paquets (en pratique, compris entre 10 et 100 paquets, soit environ 14 et 140 Ko de données) et attend un aller-retour jusqu'à ce que le récepteur renvoie des acquittements de ces paquets. S'ils sont tous reconnus, cela signifie que le réseau peut gérer ce débit d'envoi, et nous pouvons essayer de répéter le processus mais avec plus de données (en pratique, le débit d'envoi double généralement à chaque itération).
De cette façon, le débit d'envoi continue d'augmenter jusqu'à ce que certains paquets ne soient pas reconnus (ce qui indique une perte de paquets et une congestion du réseau). Cette première phase est généralement appelée « démarrage lent ». Lors de la détection d'une perte de paquets, TCP réduit le débit d'envoi et (après un certain temps) recommence à augmenter le débit d'envoi, bien que par incréments (beaucoup) plus petits. Cette logique de réduction puis d'augmentation est répétée pour chaque perte de paquet par la suite. Finalement, cela signifie que TCP essaiera constamment d'atteindre son partage de bande passante idéal et équitable. Ce mécanisme est illustré à la figure 1.
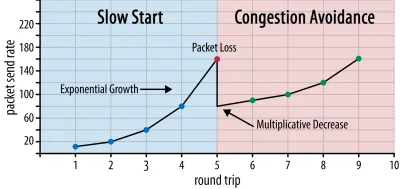
Il s'agit d'une explication extrêmement simplifiée du contrôle de la congestion. En pratique, de nombreux autres facteurs entrent en jeu, tels que le bufferbloat, la fluctuation des RTT due à la congestion et le fait que plusieurs expéditeurs simultanés doivent obtenir leur juste part de la bande passante. En tant que tels, de nombreux algorithmes de contrôle de la congestion différents existent, et beaucoup sont encore inventés aujourd'hui, aucun ne fonctionnant de manière optimale dans toutes les situations.
Bien que le contrôle de la congestion de TCP le rende robuste, cela signifie également qu'il faut un certain temps pour atteindre des débits d'envoi optimaux , en fonction du RTT et de la bande passante disponible réelle. Pour le chargement des pages Web, cette approche de démarrage lent peut également affecter des mesures telles que la première peinture de contenu, car seule une petite quantité de données (des dizaines à quelques centaines de Ko) peut être transférée au cours des premiers allers-retours. (Vous avez peut-être entendu la recommandation de conserver vos données critiques à moins de 14 Ko.)
Le choix d'une approche plus agressive pourrait donc conduire à de meilleurs résultats sur les réseaux à bande passante élevée et à latence élevée, surtout si vous ne vous souciez pas de la perte de paquets occasionnelle. C'est là que j'ai encore vu de nombreuses interprétations erronées sur le fonctionnement de QUIC.
Comme indiqué dans la partie 1, QUIC, en théorie, souffre moins de la perte de paquets (et du blocage de tête de ligne (HOL) associé) car il traite indépendamment la perte de paquets sur le flux d'octets de chaque ressource. De plus, QUIC s'exécute sur le protocole UDP ( User Datagram Protocol ), qui, contrairement à TCP, n'a pas de fonction de contrôle de congestion intégrée ; il vous permet d'essayer d'envoyer à n'importe quel débit et ne retransmet pas les données perdues.
Cela a conduit à de nombreux articles affirmant que QUIC n'utilise pas non plus le contrôle de la congestion, que QUIC peut plutôt commencer à envoyer des données à un débit beaucoup plus élevé via UDP (en s'appuyant sur la suppression du blocage HOL pour faire face à la perte de paquets), c'est pourquoi QUIC est beaucoup plus rapide que TCP.
En réalité, rien ne pourrait être plus éloigné de la vérité : QUIC utilise en fait des techniques de gestion de la bande passante très similaires à celles de TCP . Il commence également avec un taux d'envoi inférieur et augmente avec le temps, en utilisant les accusés de réception comme mécanisme clé pour mesurer la capacité du réseau. C'est (entre autres raisons) parce que QUIC doit être fiable pour être utile pour quelque chose comme HTTP, parce qu'il doit être juste pour les autres connexions QUIC (et TCP !), et parce que sa suppression du blocage HOL ne le fait pas. aide réellement contre la perte de paquets (comme nous le verrons ci-dessous).
Cependant, cela ne signifie pas que QUIC ne peut pas être (un peu) plus intelligent sur la façon dont il gère la bande passante que TCP. Cela est principalement dû au fait que QUIC est plus flexible et plus facile à faire évoluer que TCP . Comme nous l'avons dit, les algorithmes de contrôle de la congestion évoluent encore fortement aujourd'hui, et nous devrons probablement, par exemple, ajuster les choses pour tirer le meilleur parti de la 5G.
Cependant, TCP est généralement implémenté dans le noyau du système d'exploitation (OS), un environnement sécurisé et plus restreint, qui pour la plupart des systèmes d'exploitation n'est même pas open source. En tant que tel, le réglage de la logique de congestion n'est généralement effectué que par quelques développeurs sélectionnés, et l'évolution est lente.
En revanche, la plupart des implémentations QUIC sont actuellement effectuées dans «l'espace utilisateur» (où nous exécutons généralement des applications natives) et sont rendues open source, explicitement pour encourager l'expérimentation par un groupe beaucoup plus large de développeurs (comme déjà montré, par exemple, par Facebook ).
Un autre exemple concret est la proposition d'extension de fréquence d'accusé de réception différé pour QUIC. Alors que, par défaut, QUIC envoie un accusé de réception tous les 2 paquets reçus, cette extension permet aux terminaux d'accuser réception, par exemple, tous les 10 paquets à la place. Il a été démontré que cela offre des avantages de vitesse importants sur les réseaux satellites et à très large bande passante, car le surcoût de transmission des paquets d'accusé de réception est réduit. L'ajout d'une telle extension pour TCP prendrait beaucoup de temps à être adopté, alors que pour QUIC, il est beaucoup plus facile à déployer.
En tant que tel, nous pouvons nous attendre à ce que la flexibilité de QUIC conduise à plus d'expérimentation et à de meilleurs algorithmes de contrôle de la congestion au fil du temps, qui pourraient à leur tour également être rétroportés vers TCP pour l'améliorer également.
Savais-tu?
La RFC 9002 officielle de QUIC Recovery spécifie l'utilisation de l'algorithme de contrôle de congestion NewReno. Bien que cette approche soit robuste, elle est également quelque peu obsolète et n'est plus largement utilisée dans la pratique. Alors, pourquoi est-ce dans le QUIC RFC ? La première raison est que lorsque QUIC a été lancé, NewReno était le plus récent algorithme de contrôle de congestion lui-même standardisé. Des algorithmes plus avancés, tels que BBR et CUBIC, ne sont toujours pas normalisés ou ne sont devenus que récemment des RFC.
La deuxième raison est que NewReno est une configuration relativement simple. Étant donné que les algorithmes nécessitent quelques ajustements pour gérer les différences entre QUIC et TCP, il est plus facile d'expliquer ces changements sur un algorithme plus simple. En tant que telle, la RFC 9002 devrait être lue plus comme "comment adapter un algorithme de contrôle de congestion à QUIC", plutôt que "c'est la chose que vous devriez utiliser pour QUIC". En effet, la plupart des implémentations QUIC au niveau de la production ont fait des implémentations personnalisées de Cubic et BBR.
Il convient de répéter que les algorithmes de contrôle de congestion ne sont pas spécifiques à TCP ou QUIC ; ils peuvent être utilisés par l'un ou l'autre des protocoles, et l'espoir est que les progrès de QUIC finiront par se retrouver également dans les piles TCP.
Savais-tu?
Notez qu'à côté du contrôle de la congestion se trouve un concept connexe appelé contrôle de flux. Ces deux fonctionnalités sont souvent confondues dans TCP, car on dit qu'elles utilisent toutes deux la "fenêtre TCP" , bien qu'il y ait en fait deux fenêtres : la fenêtre de congestion et la fenêtre de réception TCP. Le contrôle de flux, cependant, entre beaucoup moins en jeu pour le cas d'utilisation du chargement de pages Web qui nous intéresse, nous allons donc l'ignorer ici. Des informations plus détaillées sont disponibles.
Qu'est-ce que tout cela veut dire?
QUIC est toujours lié par les lois de la physique et la nécessité d'être gentil avec les autres expéditeurs sur Internet. Cela signifie qu'il ne téléchargera pas comme par magie les ressources de votre site Web beaucoup plus rapidement que TCP. Cependant, la flexibilité de QUIC signifie que l'expérimentation de nouveaux algorithmes de contrôle de la congestion deviendra plus facile, ce qui devrait améliorer les choses à l'avenir pour TCP et QUIC.
Configuration de la connexion 0-RTT
Un deuxième aspect des performances concerne le nombre d'allers-retours nécessaires avant de pouvoir envoyer des données HTTP utiles (par exemple, des ressources de page) sur une nouvelle connexion. Certains prétendent que QUIC est deux voire trois allers-retours plus rapides que TCP + TLS, mais nous verrons que ce n'en est vraiment qu'un.
Savais-tu?
Comme nous l'avons dit dans la partie 1, une connexion effectue généralement une (TCP) ou deux (TCP + TLS) poignées de main avant que les requêtes et les réponses HTTP puissent être échangées. Ces poignées de main échangent des paramètres initiaux que le client et le serveur doivent connaître pour, par exemple, chiffrer les données.
Comme vous pouvez le voir dans la figure 2 ci-dessous, chaque poignée de main individuelle prend au moins un aller-retour pour être complétée (TCP + TLS 1.3, (b)) et parfois deux (TLS 1.2 et antérieur (a)). Ceci est inefficace, car nous avons besoin d' au moins deux allers-retours de temps d'attente de poignée de main (overhead) avant de pouvoir envoyer notre première requête HTTP, ce qui signifie attendre au moins trois allers-retours pour que les premières données de réponse HTTP (la flèche rouge de retour) arrivent Dans les réseaux lents, cela peut signifier une surcharge de 100 à 200 millisecondes.
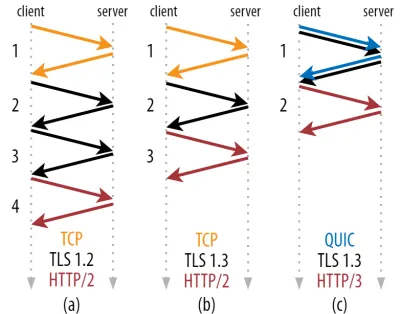
Vous vous demandez peut-être pourquoi la poignée de main TCP + TLS ne peut pas simplement être combinée, effectuée dans le même aller-retour. Bien que cela soit conceptuellement possible (QUIC fait exactement cela), les choses n'ont pas été conçues comme ça au départ, car nous devons pouvoir utiliser TCP avec et sans TLS en plus. En d'autres termes, TCP ne prend tout simplement pas en charge l'envoi d'éléments non TCP pendant la poignée de main. Il y a eu des efforts pour ajouter cela avec l'extension TCP Fast Open ; Cependant, comme indiqué dans la partie 1, cela s'est avéré difficile à déployer à grande échelle.
Heureusement, QUIC a été conçu avec TLS à l'esprit dès le départ et, en tant que tel, combine à la fois les poignées de main de transport et de chiffrement dans un seul mécanisme. Cela signifie que la poignée de main QUIC ne prendra qu'un seul aller-retour au total, soit un aller-retour de moins que TCP + TLS 1.3 (voir figure 2c ci-dessus).
Vous pourriez être confus, car vous avez probablement lu que QUIC est deux ou même trois allers-retours plus rapides que TCP, pas seulement un. En effet, la plupart des articles ne considèrent que le pire des cas (TCP + TLS 1.2, (a)), sans mentionner que le TCP + TLS 1.3 moderne ne prend également « que » deux allers-retours ((b) est rarement montré). Bien qu'un gain de vitesse d'un aller-retour soit agréable, ce n'est guère étonnant. Surtout sur les réseaux rapides (par exemple, moins d'un RTT de 50 millisecondes), cela sera à peine perceptible , bien que les réseaux lents et les connexions à des serveurs distants en profiteraient un peu plus.
Ensuite, vous vous demandez peut-être pourquoi nous devons attendre la ou les poignées de main. Pourquoi ne pouvons-nous pas envoyer de requête HTTP lors du premier aller-retour ? C'est principalement parce que, si nous le faisions, alors cette première demande serait envoyée non cryptée , lisible par n'importe quel espion sur le fil, ce qui n'est évidemment pas idéal pour la confidentialité et la sécurité. En tant que tel, nous devons attendre la fin de la poignée de main cryptographique avant d'envoyer la première requête HTTP. Ou faisons-nous?
C'est là qu'une astuce astucieuse est utilisée dans la pratique. Nous savons que les utilisateurs revisitent souvent les pages Web peu de temps après leur première visite. En tant que tel, nous pouvons utiliser la connexion chiffrée initiale pour amorcer une deuxième connexion à l'avenir. En termes simples, au cours de sa durée de vie, la première connexion est utilisée pour communiquer en toute sécurité de nouveaux paramètres cryptographiques entre le client et le serveur. Ces paramètres peuvent ensuite être utilisés pour chiffrer la deuxième connexion dès le début, sans avoir à attendre la fin de la poignée de main TLS complète. Cette approche est appelée « reprise de session » .
Cela permet une optimisation puissante : nous pouvons désormais envoyer en toute sécurité notre première requête HTTP avec la poignée de main QUIC/TLS, ce qui nous évite un autre aller-retour ! Comme pour TLS 1.3, cela supprime efficacement le temps d'attente de la poignée de main TLS. Cette méthode est souvent appelée 0-RTT (bien que, bien sûr, il faille encore un aller-retour pour que les données de réponse HTTP commencent à arriver).
La reprise de session et le 0-RTT sont, encore une fois, des choses que j'ai souvent vues à tort expliquées comme étant des fonctionnalités spécifiques à QUIC. En réalité, il s'agit en fait de fonctionnalités TLS qui étaient déjà présentes sous une forme ou une autre dans TLS 1.2 et qui sont désormais pleinement intégrées dans TLS 1.3.
En d'autres termes, comme vous pouvez le voir dans la figure 3 ci-dessous, nous pouvons également bénéficier des avantages en termes de performances de ces fonctionnalités sur TCP (et donc aussi HTTP/2 et même HTTP/1.1) ! Nous voyons que même avec 0-RTT, QUIC n'est encore qu'un aller-retour plus rapide qu'une pile TCP + TLS 1.3 fonctionnant de manière optimale. L'affirmation selon laquelle QUIC est trois allers-retours plus rapide vient de la comparaison de la figure 2 (a) avec la figure 3 (f), ce qui, comme nous l'avons vu, n'est pas vraiment juste.

Le pire, c'est que lors de l'utilisation de 0-RTT, QUIC ne peut même pas vraiment utiliser cet aller-retour gagné en raison de la sécurité. Pour comprendre cela, nous devons comprendre l'une des raisons pour lesquelles la poignée de main TCP existe. Premièrement, cela permet au client de s'assurer que le serveur est réellement disponible à l'adresse IP donnée avant de lui envoyer des données de couche supérieure.
Deuxièmement, et surtout ici, cela permet au serveur de s'assurer que le client qui ouvre la connexion est bien qui et où il dit être avant de lui envoyer des données. Si vous vous rappelez comment nous avons défini une connexion avec le 4-uplet dans la partie 1, vous saurez que le client est principalement identifié par son adresse IP. Et c'est bien là le problème : les adresses IP peuvent être usurpées !
Supposons qu'un attaquant demande un fichier très volumineux via HTTP via QUIC 0-RTT. Cependant, ils usurpent leur adresse IP, donnant l'impression que la demande 0-RTT provient de l'ordinateur de leur victime. Ceci est illustré dans la figure 4 ci-dessous. Le serveur QUIC n'a aucun moyen de détecter si l'adresse IP a été usurpée, car il s'agit du tout premier paquet qu'il voit de ce client.

Si le serveur commence alors simplement à renvoyer le fichier volumineux à l'adresse IP usurpée, cela pourrait finir par surcharger la bande passante du réseau de la victime (surtout si l'attaquant faisait plusieurs de ces fausses requêtes en parallèle). Notez que la réponse QUIC serait abandonnée par la victime, car elle n'attend pas de données entrantes, mais cela n'a pas d'importance : leur réseau doit encore traiter les paquets !
C'est ce qu'on appelle une attaque par réflexion ou amplification , et c'est un moyen important pour les pirates d'exécuter des attaques par déni de service distribué (DDoS). Notez que cela ne se produit pas lorsque 0-RTT sur TCP + TLS est utilisé, précisément parce que la poignée de main TCP doit d'abord se terminer avant que la demande 0-RTT ne soit même envoyée avec la poignée de main TLS.
En tant que tel, QUIC doit être prudent dans sa réponse aux requêtes 0-RTT, en limitant la quantité de données qu'il envoie en réponse jusqu'à ce que le client ait été vérifié comme étant un vrai client et non une victime. Pour QUIC, cette quantité de données a été fixée à trois fois la quantité reçue du client.
En d'autres termes, QUIC a un « facteur d'amplification » maximal de trois, ce qui a été déterminé comme étant un compromis acceptable entre l'utilité des performances et le risque de sécurité (en particulier par rapport à certains incidents qui avaient un facteur d'amplification de plus de 51 000 fois). Étant donné que le client envoie généralement d'abord un à deux paquets, la réponse 0-RTT du serveur QUIC sera plafonnée à seulement 4 à 6 Ko (y compris les autres frais généraux QUIC et TLS !), Ce qui est un peu moins qu'impressionnant.
De plus, d'autres problèmes de sécurité peuvent conduire, par exemple, à des "attaques par rejeu", qui limitent le type de requête HTTP que vous pouvez faire. Par exemple, Cloudflare n'autorise que les requêtes HTTP GET sans paramètres de requête dans 0-RTT. Ceux-ci limitent encore plus l'utilité du 0-RTT.
Heureusement, QUIC a des options pour améliorer un peu cela. Par exemple, le serveur peut vérifier si le 0-RTT provient d'une adresse IP avec laquelle il a eu une connexion valide auparavant. Cependant, cela ne fonctionne que si le client reste sur le même réseau (ce qui limite quelque peu la fonctionnalité de migration de connexion de QUIC). Et même si cela fonctionne, la réponse de QUIC est toujours limitée par la logique de démarrage lent du contrôleur de congestion dont nous avons discuté ci-dessus ; ainsi, il n'y a pas d'augmentation de vitesse massive supplémentaire en plus du seul aller-retour enregistré.
Savais-tu?
Il est intéressant de noter que la limite d'amplification multipliée par trois de QUIC compte également pour son processus normal de prise de contact non-0-RTT dans la figure 2c. Cela peut être un problème si, par exemple, le certificat TLS du serveur est trop volumineux pour tenir dans 4 à 6 Ko. Dans ce cas, il devrait être divisé, le deuxième bloc devant attendre l'envoi du deuxième aller-retour (après l'arrivée des accusés de réception des premiers paquets, indiquant que l'adresse IP du client n'a pas été usurpée). Dans ce cas, la poignée de main de QUIC pourrait encore finir par prendre deux allers-retours , égaux à TCP + TLS ! C'est pourquoi pour QUIC, des techniques telles que la compression de certificats seront très importantes.
Savais-tu?
Il se peut que certaines configurations avancées soient capables d'atténuer suffisamment ces problèmes pour rendre le 0-RTT plus utile. Par exemple, le serveur pouvait se souvenir de la quantité de bande passante disponible pour un client la dernière fois qu'il a été vu, ce qui le rendait moins limité par le démarrage lent du contrôle de congestion pour la reconnexion des clients (non usurpés). Cela a été étudié dans le milieu universitaire, et il y a même une extension proposée dans QUIC pour le faire. Plusieurs entreprises font déjà ce genre de choses pour accélérer TCP également.
Une autre option consisterait à faire en sorte que les clients envoient plus d'un ou deux paquets (par exemple, envoyer 7 paquets supplémentaires avec remplissage), de sorte que la limite de trois fois se traduit par une réponse plus intéressante de 12 à 14 Ko, même après la migration de la connexion. J'ai écrit à ce sujet dans un de mes articles.
Enfin, les serveurs QUIC (qui se comportent mal) pourraient également augmenter intentionnellement la limite de trois fois s'ils estiment qu'il est en quelque sorte sûr de le faire ou s'ils ne se soucient pas des problèmes de sécurité potentiels (après tout, aucune police de protocole n'empêche cela).
Qu'est-ce que tout cela veut dire?
La configuration de connexion plus rapide de QUIC avec 0-RTT est vraiment plus une micro-optimisation qu'une nouvelle fonctionnalité révolutionnaire. Par rapport à une configuration TCP + TLS 1.3 de pointe, cela permettrait d'économiser au maximum un aller-retour. La quantité de données qui peut réellement être envoyée lors du premier aller-retour est en outre limitée par un certain nombre de considérations de sécurité.
En tant que telle, cette fonctionnalité brillera principalement si vos utilisateurs sont sur des réseaux avec une latence très élevée (par exemple, des réseaux satellites avec des RTT de plus de 200 millisecondes) ou si vous n'envoyez généralement pas beaucoup de données. Certains exemples de ces derniers sont des sites Web fortement mis en cache, ainsi que des applications d'une seule page qui récupèrent périodiquement de petites mises à jour via des API et d'autres protocoles tels que DNS-over-QUIC. L'une des raisons pour lesquelles Google a vu de très bons résultats 0-RTT pour QUIC est qu'il l'a testé sur sa page de recherche déjà fortement optimisée, où les réponses aux requêtes sont assez petites.
Dans les autres cas, vous ne gagnerez au mieux que quelques dizaines de millisecondes , encore moins si vous utilisez déjà un CDN (ce que vous devriez faire si vous vous souciez des performances !).
Migration de connexion
Une troisième caractéristique de performance rend QUIC plus rapide lors du transfert entre les réseaux, en gardant les connexions existantes intactes . Bien que cela fonctionne effectivement, ce type de changement de réseau ne se produit pas très souvent et les connexions doivent toujours réinitialiser leurs taux d'envoi.
Comme indiqué dans la partie 1, les identifiants de connexion (CID) de QUIC lui permettent d'effectuer une migration de connexion lors du changement de réseau . Nous avons illustré cela avec un client passant d'un réseau Wi-Fi à la 4G tout en effectuant un téléchargement de fichier volumineux. Sur TCP, ce téléchargement peut devoir être interrompu, tandis que pour QUIC, il peut continuer.
Cependant, considérez d'abord la fréquence à laquelle ce type de scénario se produit réellement. Vous pourriez penser que cela se produit également lorsque vous vous déplacez entre des points d'accès Wi-Fi dans un bâtiment ou entre des tours cellulaires sur la route. Dans ces configurations, cependant (si elles sont faites correctement), votre appareil gardera généralement son adresse IP intacte, car la transition entre les stations de base sans fil se fait à une couche de protocole inférieure. En tant que tel, cela ne se produit que lorsque vous vous déplacez entre des réseaux complètement différents , ce qui, je dirais, n'arrive pas très souvent.
Deuxièmement, nous pouvons nous demander si cela fonctionne également pour d'autres cas d'utilisation en plus des téléchargements de fichiers volumineux, des vidéoconférences en direct et du streaming. Si vous chargez une page Web au moment exact où vous changez de réseau, vous devrez peut-être redemander certaines des ressources (plus tardives).
Cependant, le chargement d'une page prend généralement de l'ordre de quelques secondes, de sorte que la coïncidence avec un changement de réseau ne sera pas non plus très courante. De plus, pour les cas d'utilisation où il s'agit d'une préoccupation urgente, d'autres mesures d'atténuation sont généralement déjà en place . Par exemple, les serveurs proposant des téléchargements de fichiers volumineux peuvent prendre en charge les requêtes de plage HTTP pour permettre des téléchargements pouvant être repris.
Étant donné qu'il y a généralement un certain temps de chevauchement entre le réseau 1 et la mise à disposition du réseau 2, les applications vidéo peuvent ouvrir plusieurs connexions (1 par réseau), en les synchronisant avant que l'ancien réseau ne disparaisse complètement. L'utilisateur remarquera toujours le commutateur, mais il ne supprimera pas complètement le flux vidéo.
Troisièmement, rien ne garantit que le nouveau réseau aura autant de bande passante disponible que l'ancien. En tant que tel, même si la connexion conceptuelle est conservée intacte, le serveur QUIC ne peut pas simplement continuer à envoyer des données à des vitesses élevées. Au lieu de cela, pour éviter de surcharger le nouveau réseau, il doit réinitialiser (ou au moins baisser) le débit d'envoi et recommencer dans la phase de démarrage lent du contrôleur de congestion.
Étant donné que ce taux d'envoi initial est généralement trop faible pour prendre en charge des éléments tels que le streaming vidéo, vous constaterez une perte de qualité ou des problèmes, même sur QUIC. D'une certaine manière, la migration de connexion consiste davantage à empêcher l'attrition du contexte de connexion et la surcharge sur le serveur qu'à améliorer les performances.
Savais-tu?
Notez que, comme indiqué ci-dessus pour 0-RTT, nous pouvons concevoir des techniques avancées pour améliorer la migration de connexion. Par exemple, nous pouvons, encore une fois, essayer de nous souvenir de la quantité de bande passante disponible sur un réseau donné la dernière fois et tenter de monter plus rapidement à ce niveau pour une nouvelle migration. De plus, nous pourrions envisager de ne pas simplement basculer entre les réseaux, mais d'utiliser les deux en même temps. Ce concept est appelé multipath , et nous en discutons plus en détail ci-dessous.
Jusqu'à présent, nous avons principalement parlé de migration de connexion active, où les utilisateurs se déplacent entre différents réseaux. Il existe cependant également des cas de migration de connexion passive, où un certain réseau lui-même change de paramètres. Un bon exemple de ceci est la liaison de traduction d'adresses réseau (NAT). Bien qu'une discussion complète sur NAT sorte du cadre de cet article, cela signifie principalement que les numéros de port de la connexion peuvent changer à tout moment, sans avertissement. Cela se produit également beaucoup plus souvent pour UDP que TCP dans la plupart des routeurs.
Si cela se produit, le QUIC CID ne changera pas et la plupart des implémentations supposeront que l'utilisateur est toujours sur le même réseau physique et ne réinitialiseront donc pas la fenêtre de congestion ou d'autres paramètres. QUIC inclut également certaines fonctionnalités telles que les PING et les indicateurs de délai d'attente pour éviter que cela ne se produise, car cela se produit généralement pour les connexions inactives depuis longtemps.
Nous avons expliqué dans la partie 1 que QUIC n'utilise pas qu'un seul CID pour des raisons de sécurité. Au lieu de cela, il modifie les CID lors de l'exécution d'une migration active. En pratique, c'est encore plus compliqué, car le client et le serveur ont des listes de CID distinctes (appelées CID source et destination dans le QUIC RFC). Ceci est illustré dans la figure 5 ci-dessous.
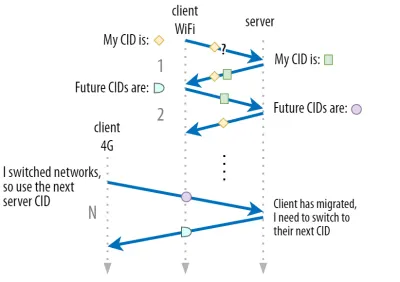
Ceci est fait pour permettre à chaque point de terminaison de choisir son propre format et contenu CID , ce qui est à son tour crucial pour permettre un routage avancé et une logique d'équilibrage de charge. Avec la migration de connexion, les équilibreurs de charge ne peuvent plus simplement regarder le 4-uplet pour identifier une connexion et l'envoyer au bon serveur principal. Cependant, si toutes les connexions QUIC devaient utiliser des CID aléatoires, cela augmenterait considérablement les besoins en mémoire au niveau de l'équilibreur de charge, car il faudrait stocker les mappages des CID sur les serveurs principaux. De plus, cela ne fonctionnerait toujours pas avec la migration de connexion, car les CID passent à de nouvelles valeurs aléatoires.

En tant que tel, il est important que les serveurs principaux QUIC déployés derrière un équilibreur de charge aient un format prévisible de leurs CID, afin que l'équilibreur de charge puisse dériver le serveur principal correct à partir du CID, même après la migration. Certaines options pour ce faire sont décrites dans le document proposé par l'IETF. Pour que tout cela soit possible, les serveurs doivent pouvoir choisir leur propre CID, ce qui ne serait pas possible si l'initiateur de la connexion (qui, pour QUIC, est toujours le client) choisissait le CID. C'est pourquoi il y a une séparation entre les CID client et serveur dans QUIC.
Qu'est-ce que tout cela veut dire?
Ainsi, la migration de connexion est une caractéristique situationnelle. Les premiers tests de Google, par exemple, montrent de faibles pourcentages d'améliorations pour ses cas d'utilisation. De nombreuses implémentations QUIC n'implémentent pas encore cette fonctionnalité. Même ceux qui le font le limiteront généralement aux clients et applications mobiles et non à leurs équivalents de bureau. Certaines personnes sont même d'avis que la fonctionnalité n'est pas nécessaire, car l'ouverture d'une nouvelle connexion avec 0-RTT devrait avoir des propriétés de performances similaires dans la plupart des cas.
Néanmoins, selon votre cas d'utilisation ou votre profil d'utilisateur, cela pourrait avoir un impact important. Si votre site Web ou votre application est le plus souvent utilisé lors de vos déplacements (par exemple, quelque chose comme Uber ou Google Maps), vous en bénéficierez probablement plus que si vos utilisateurs étaient généralement assis derrière un bureau. Similarly, if you're focusing on constant interaction (be it video chat, collaborative editing, or gaming), then your worst-case scenarios should improve more than if you have a news website.
Head-of-Line Blocking Removal
The fourth performance feature is intended to make QUIC faster on networks with a high amount of packet loss by mitigating the head-of-line (HoL) blocking problem. While this is true in theory, we will see that in practice this will probably only provide minor benefits for web-page loading performance.
To understand this, though, we first need to take a detour and talk about stream prioritization and multiplexing.
Stream Prioritization
As discussed in part 1, a single TCP packet loss can delay data for multiple in-transit resources because TCP's bytestream abstraction considers all data to be part of a single file. QUIC, on the other hand, is intimately aware that there are multiple concurrent bytestreams and can handle loss on a per-stream basis. However, as we've also seen, these streams are not truly transmitting data in parallel: Rather, the stream data is multiplexed onto a single connection. This multiplexing can happen in many different ways.
For example, for streams A, B, and C, we might see a packet sequence of ABCABCABCABCABCABCABCABC , where we change the active stream in each packet (let's call this round-robin). However, we might also see the opposite pattern of AAAAAAAABBBBBBBBCCCCCCCC , where each stream is completed in full before starting the next one (let's call this sequential). Of course, many other options are possible in between these extremes ( AAAABBCAAAAABBC… , AABBCCAABBCC… , ABABABCCCC… , etc.). The multiplexing scheme is dynamic and driven by an HTTP-level feature called stream prioritization (discussed later in this article).
As it turns out, which multiplexing scheme you choose can have a huge impact on website loading performance. You can see this in the video below, courtesy of Cloudflare, as every browser uses a different multiplexer. The reasons why are quite complex, and I've written several academic papers on the topic, as well as talked about it in a conference. Patrick Meenan, of Webpagetest fame, even has a three-hour tutorial on just this topic.

Luckily, we can explain the basics relatively easily. As you may know, some resources can be render blocking. This is the case for CSS files and for some JavaScript in the HTML head element. While these files are loading, the browser cannot paint the page (or, for example, execute new JavaScript).
What's more, CSS and JavaScript files need to be downloaded in full in order to be used (although they can often be incrementally parsed and compiled). As such, these resources need to be loaded as soon as possible, with the highest priority. Let's contemplate what would happen if A, B, and C were all render-blocking resources.
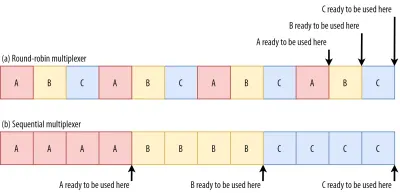
If we use a round-robin multiplexer (the top row in figure 6), we would actually delay each resource's total completion time, because they all need to share bandwidth with the others. Since we can only use them after they are fully loaded, this incurs a significant delay. However, if we multiplex them sequentially (the bottom row in figure 6), we would see that A and B complete much earlier (and can be used by the browser), while not actually delaying C's completion time.
However, that doesn't mean that sequential multiplexing is always the best, because some (mostly non-render-blocking) resources (such as HTML and progressive JPEGs) can actually be processed and used incrementally . In those (and some other) cases, it makes sense to use the first option (or at least something in between).
Still, for most web-page resources, it turns out that sequential multiplexing performs best . This is, for example, what Google Chrome is doing in the video above, while Internet Explorer is using the worst-case round-robin multiplexer.
Packet Loss Resilience
Now that we know that all streams aren't always active at the same time and that they can be multiplexed in different ways, we can consider what happens if we have packet loss. As explained in part 1, if one QUIC stream experiences packet loss, then other active streams can still be used (whereas, in TCP, all would be paused).
However, as we've just seen, having many concurrent active streams is typically not optimal for web performance, because it can delay some critical (render-blocking) resources, even without packet loss! We'd rather have just one or two active at the same time, using a sequential multiplexer. However, this reduces the impact of QUIC's HoL blocking removal.
Imagine, for example, that the sender could transmit 12 packets at a given time (see figure 7 below) — remember that this is limited by the congestion controller). If we fill all 12 of those packets with data for stream A (because it's high priority and render-blocking — think main.js ), then we would have only one active stream in that 12-packet window.
If one of those packets were to be lost, then QUIC would still end up fully HoL blocked because there would simply be no other streams it could process besides A : All of the data is for A , and so everything would still have to wait (we don't have B or C data to process), similar to TCP.

We see that we have a kind of contradiction: Sequential multiplexing ( AAAABBBBCCCC ) is typically better for web performance, but it doesn't allow us to take much advantage of QUIC's HoL blocking removal. Round-robin multiplexing ( ABCABCABCABC ) would be better against HoL blocking, but worse for web performance. As such, one best practice or optimization can end up undoing another .
And it gets worse. Up until now, we've sort of assumed that individual packets get lost one at a time. However, this isn't always true, because packet loss on the Internet is often “bursty”, meaning that multiple packets often get lost at the same time .
As discussed above, an important reason for packet loss is that a network is overloaded with too much data, having to drop excess packets. This is why the congestion controller starts sending slowly. However, it then keeps growing its send rate until… there is packet loss!
Put differently, the mechanism that's intended to prevent overloading the network actually overloads the network (albeit in a controlled fashion). On most networks, that occurs after quite a while, when the send rate has increased to hundreds of packets per round trip. When those reach the limit of the network, several of them are typically dropped together, leading to the bursty loss patterns.
Did You Know?
This is one of the reasons why we wanted to move to using a single (TCP) connection with HTTP/2, rather than the 6 to 30 connections with HTTP/1.1. Because each individual connection ramps up its send rate in pretty much the same way, HTTP/1.1 could get a good speed-up at the start, but the connections could actually start causing massive packet loss for each other as they caused the network to become overloaded.
At the time, Chromium developers speculated that this behaviour caused most of the packet loss seen on the Internet. This is also one of the reasons why BBR has become an often used congestion-control algorithm, because it uses fluctuations in observed RTTs, rather than packet loss, to assess available bandwidth.
Did You Know?
Other causes of packet loss can lead to fewer or individual packets becoming lost (or unusable), especially on wireless networks. There, however, the losses are often detected at lower protocol layers and solved between two local entities (say, the smartphone and the 4G cellular tower), rather than by retransmissions between the client and the server. These usually don't lead to real end-to-end packet loss, but rather show up as variations in packet latency (or “jitter”) and reordered packet arrivals.
So, let's say we are using a per-packet round-robin multiplexer ( ABCABCABCABCABCABCABCABC… ) to get the most out of HoL blocking removal, and we get a bursty loss of just 4 packets. We see that this will always impact all 3 streams (see figure 8, middle row)! In this case, QUIC's HoL blocking removal provides no benefits, because all streams have to wait for their own retransmissions .
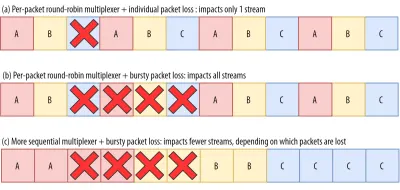
To lower the risk of multiple streams being affected by a lossy burst, we need to concatenate more data for each stream. For example, AABBCCAABBCCAABBCCAABBCC… is a small improvement, and AAAABBBBCCCCAAAABBBBCCCC… (see bottom row in figure 8 above) is even better. You can again see that a more sequential approach is better, even though that reduces the chances that we have multiple concurrent active streams.
In the end, predicting the actual impact of QUIC's HoL blocking removal is difficult, because it depends on the number of streams, the size and frequency of the loss bursts, how the stream data is actually used, etc. However, most results at this time indicate it will not help much for the use case of web-page loading, because there we typically want fewer concurrent streams.
If you want even more detail on this topic or just some concrete examples, please check out my in-depth article on HTTP HoL blocking.
Did You Know?
As with the previous sections, some advanced techniques can help us here. For example, modern congestion controllers use packet pacing. This means that they don't send, for example, 100 packets in a single burst, but rather spread them out over an entire RTT. This conceptually lowers the chances of overloading the network, and the QUIC Recovery RFC strongly recommends using it. Complementarily, some congestion-control algorithms such as BBR don't keep increasing their send rate until they cause packet loss, but rather back off before that (by looking at, for example, RTT fluctuations, because RTTs also rise when a network is becoming overloaded).
While these approaches lower the overall chances of packet loss, they don't necessarily lower its burstiness.
Qu'est-ce que tout cela veut dire?
While QUIC's HoL blocking removal means, in theory, that it (and HTTP/3) should perform better on lossy networks, in practice this depends on a lot of factors. Because the use case of web-page loading typically favours a more sequential multiplexing set-up, and because packet loss is unpredictable, this feature would, again, likely affect mainly the slowest 1% of users . However, this is still a very active area of research, and only time will tell.
Still, there are situations that might see more improvements. These are mostly outside of the typical use case of the first full page load — for example, when resources are not render blocking, when they can be processed incrementally, when streams are completely independent, or when less data is sent at the same time.
Examples include repeat visits on well-cached pages and background downloads and API calls in single-page apps. For example, Facebook has seen some benefits from HoL blocking removal when using HTTP/3 to load data in its native app.
Performances UDP et TLS
Un cinquième aspect des performances de QUIC et HTTP/3 concerne l'efficacité et les performances avec lesquelles ils peuvent réellement créer et envoyer des paquets sur le réseau. Nous verrons que l'utilisation par QUIC de l'UDP et du cryptage lourd peut le rendre un peu plus lent que TCP (mais les choses s'améliorent).
Tout d'abord, nous avons déjà expliqué que l'utilisation d'UDP par QUIC concernait davantage la flexibilité et la capacité de déploiement que les performances. Ceci est encore plus mis en évidence par le fait que, jusqu'à récemment, l'envoi de paquets QUIC via UDP était généralement beaucoup plus lent que l'envoi de paquets TCP. Cela s'explique en partie par l'endroit et la manière dont ces protocoles sont généralement mis en œuvre (voir la figure 9 ci-dessous).

Comme indiqué ci-dessus, TCP et UDP sont généralement implémentés directement dans le noyau rapide du système d'exploitation. En revanche, les implémentations TLS et QUIC sont principalement dans un espace utilisateur plus lent (notez que ce n'est pas vraiment nécessaire pour QUIC - c'est principalement fait parce que c'est beaucoup plus flexible). Cela rend QUIC déjà un peu plus lent que TCP.
De plus, lors de l'envoi de données depuis notre logiciel d'espace utilisateur (par exemple, les navigateurs et les serveurs Web), nous devons transmettre ces données au noyau du système d'exploitation , qui utilise ensuite TCP ou UDP pour les mettre sur le réseau. La transmission de ces données se fait à l'aide des API du noyau (appels système), ce qui implique une certaine surcharge par appel d'API. Pour TCP, ces frais généraux étaient beaucoup plus faibles que pour UDP.
C'est principalement parce que, historiquement, TCP a été beaucoup plus utilisé qu'UDP. Ainsi, au fil du temps, de nombreuses optimisations ont été ajoutées aux implémentations TCP et aux API du noyau pour réduire au minimum les frais généraux d'envoi et de réception de paquets. De nombreux contrôleurs d'interface réseau (NIC) ont même des fonctionnalités de déchargement matériel intégrées pour TCP. UDP, cependant, n'a pas eu autant de chance, car son utilisation plus limitée ne justifiait pas l'investissement dans des optimisations supplémentaires. Au cours des cinq dernières années, cela a heureusement changé et la plupart des systèmes d'exploitation ont également ajouté des options optimisées pour UDP .
Deuxièmement, QUIC a beaucoup de temps système car il chiffre chaque paquet individuellement . C'est plus lent que d'utiliser TLS sur TCP, car vous pouvez chiffrer les paquets par morceaux (jusqu'à environ 16 Ko ou 11 paquets à la fois), ce qui est plus efficace. Il s'agissait d'un compromis conscient fait dans QUIC, car le chiffrement en masse peut conduire à ses propres formes de blocage HoL.
Contrairement au premier point, où nous pourrions ajouter des API supplémentaires pour rendre UDP (et donc QUIC) plus rapide, ici, QUIC aura toujours un inconvénient inhérent à TCP + TLS. Cependant, cela est également tout à fait gérable en pratique avec, par exemple, des bibliothèques de chiffrement optimisées et des méthodes intelligentes qui permettent de chiffrer en masse les en-têtes de paquets QUIC.
En conséquence, alors que les premières versions QUIC de Google étaient encore deux fois plus lentes que TCP + TLS, les choses se sont certainement améliorées depuis. Par exemple, lors de tests récents, la pile QUIC fortement optimisée de Microsoft a pu obtenir 7,85 Gbit/s, contre 11,85 Gbit/s pour TCP + TLS sur le même système (donc ici, QUIC est environ 66 % plus rapide que TCP + TLS).
C'est avec les récentes mises à jour de Windows, qui ont rendu UDP plus rapide (pour une comparaison complète, le débit UDP sur ce système était de 19,5 Gbps). La version la plus optimisée de la pile QUIC de Google est actuellement environ 20 % plus lente que TCP + TLS. Des tests antérieurs de Fastly sur un système moins avancé et avec quelques astuces revendiquent même des performances égales (environ 450 Mbps), montrant que selon les cas d'utilisation, QUIC peut définitivement concurrencer TCP.
Cependant, même si QUIC était deux fois plus lent que TCP + TLS, ce n'est pas si mal. Premièrement, le traitement QUIC et TCP + TLS n'est généralement pas la chose la plus lourde qui se passe sur un serveur, car une autre logique (par exemple, HTTP, mise en cache, proxy, etc.) doit également s'exécuter. En tant que tel, vous n'aurez en fait pas besoin de deux fois plus de serveurs pour exécuter QUIC (cependant, l'impact qu'il aura dans un vrai centre de données n'est pas clair, car aucune des grandes entreprises n'a publié de données à ce sujet).
Deuxièmement, il existe encore de nombreuses possibilités d'optimiser les implémentations QUIC à l'avenir. Par exemple, au fil du temps, certaines implémentations QUIC passeront (partiellement) au noyau du système d'exploitation (un peu comme TCP) ou le contourneront (certaines le font déjà, comme MsQuic et Quant). Nous pouvons également nous attendre à ce que du matériel spécifique à QUIC soit disponible.
Pourtant, il y aura probablement des cas d'utilisation pour lesquels TCP + TLS restera l'option préférée. Par exemple, Netflix a indiqué qu'il ne passera probablement pas à QUIC de sitôt, ayant fortement investi dans des configurations FreeBSD personnalisées pour diffuser ses vidéos via TCP + TLS.
De même, Facebook a déclaré que QUIC sera probablement principalement utilisé entre les utilisateurs finaux et la périphérie du CDN , mais pas entre les centres de données ou entre les nœuds périphériques et les serveurs d'origine, en raison de sa surcharge plus importante. De manière générale, les scénarios à très haut débit continueront probablement de favoriser TCP + TLS, surtout dans les prochaines années.
Savais-tu?
L'optimisation des piles réseau est un trou de lapin profond et technique dont ce qui précède ne fait qu'effleurer la surface (et manque beaucoup de nuances). Si vous êtes assez courageux ou si vous voulez savoir ce que signifient des termes commeGRO/GSO,SO_TXTIME, contournement du noyau etsendmmsg()etrecvmmsg(), je peux également vous recommander d'excellents articles sur l'optimisation de QUIC par Cloudflare et Fastly sous la forme d'une présentation approfondie du code par Microsoft et d'un exposé approfondi de Cisco. Enfin, un ingénieur de Google a donné un discours très intéressant sur l'optimisation de leur implémentation QUIC au fil du temps.
Qu'est-ce que tout cela veut dire?
L'utilisation particulière par QUIC des protocoles UDP et TLS l'a historiquement rendu beaucoup plus lent que TCP + TLS. Cependant, au fil du temps, plusieurs améliorations ont été apportées (et continueront d'être mises en œuvre) qui ont quelque peu comblé l'écart. Cependant, vous ne remarquerez probablement pas ces écarts dans les cas d'utilisation typiques du chargement de pages Web, mais ils pourraient vous donner des maux de tête si vous maintenez de grandes batteries de serveurs.
Fonctionnalités HTTP/3
Jusqu'à présent, nous avons principalement parlé des nouvelles fonctionnalités de performance de QUIC par rapport à TCP. Cependant, qu'en est-il de HTTP/3 par rapport à HTTP/2 ? Comme indiqué dans la partie 1, HTTP/3 est vraiment HTTP/2-over-QUIC , et en tant que tel, aucune nouvelle fonctionnalité réelle et importante n'a été introduite dans la nouvelle version. Ceci est différent du passage de HTTP/1.1 à HTTP/2, qui était beaucoup plus vaste et introduisait de nouvelles fonctionnalités telles que la compression d'en-tête, la hiérarchisation des flux et la poussée du serveur. Ces fonctionnalités sont toutes encore en HTTP/3, mais il existe des différences importantes dans la façon dont elles sont implémentées sous le capot.
Cela est principalement dû au fonctionnement de la suppression du blocage HoL par QUIC. Comme nous en avons discuté, une perte sur le flux B n'implique plus que les flux A et C devront attendre les retransmissions de B, comme ils l'ont fait sur TCP. Ainsi, si A, B et C envoyaient chacun un paquet QUIC dans cet ordre, leurs données pourraient bien être livrées (et traitées par) le navigateur comme A, C, B ! En d'autres termes, contrairement à TCP, QUIC n'est plus entièrement ordonné sur différents flux !
C'est un problème pour HTTP/2, qui s'est vraiment appuyé sur l'ordre strict de TCP dans la conception de bon nombre de ses fonctionnalités, qui utilisent des messages de contrôle spéciaux entrecoupés de blocs de données. Dans QUIC, ces messages de contrôle peuvent arriver (et être appliqués) dans n'importe quel ordre, pouvant même faire en sorte que les fonctionnalités fassent le contraire de ce qui était prévu ! Les détails techniques sont, encore une fois, inutiles pour cet article, mais la première moitié de cet article devrait vous donner une idée de la complexité stupide que cela peut devenir.
En tant que tels, les mécanismes internes et les implémentations des fonctionnalités ont dû changer pour HTTP/3. Un exemple concret est la compression d'en-tête HTTP , qui réduit la surcharge des en-têtes HTTP volumineux répétés (par exemple, les cookies et les chaînes d'agent utilisateur). Dans HTTP/2, cela a été fait en utilisant la configuration HPACK, tandis que pour HTTP/3, cela a été retravaillé pour le QPACK plus complexe. Les deux systèmes offrent la même fonctionnalité (c'est-à-dire la compression d'en-tête) mais de manière assez différente. D'excellentes discussions techniques approfondies et des diagrammes sur ce sujet peuvent être trouvés sur le blog Litespeed.
Quelque chose de similaire est vrai pour la fonction de priorisation qui pilote la logique de multiplexage de flux et dont nous avons brièvement discuté ci-dessus. Dans HTTP/2, cela a été implémenté à l'aide d'une configuration complexe "d'arbre de dépendances", qui tentait explicitement de modéliser toutes les ressources de page et leurs interrelations (plus d'informations dans la conférence "Le guide ultime de la hiérarchisation des ressources HTTP"). L'utilisation de ce système directement sur QUIC conduirait à des dispositions d'arborescence potentiellement très erronées, car l'ajout de chaque ressource à l'arborescence constituerait un message de contrôle séparé.
De plus, cette approche s'est avérée inutilement complexe, entraînant de nombreux bogues et inefficacités de mise en œuvre et des performances inférieures à la moyenne sur de nombreux serveurs. Ces deux problèmes ont conduit à repenser le système de priorisation pour HTTP/3 de manière beaucoup plus simple. Cette configuration plus simple rend certains scénarios avancés difficiles ou impossibles à appliquer (par exemple, le trafic proxy de plusieurs clients sur une seule connexion), mais permet toujours un large éventail d'options pour l'optimisation du chargement des pages Web.
Bien que, encore une fois, les deux approches offrent la même fonctionnalité de base (guidant le multiplexage de flux), l'espoir est que la configuration plus facile de HTTP/3 réduira le nombre de bogues d'implémentation.
Enfin, il y a le serveur push . Cette fonctionnalité permet au serveur d'envoyer des réponses HTTP sans attendre au préalable une demande explicite. En théorie, cela pourrait offrir d'excellents gains de performances. En pratique, cependant, il s'est avéré difficile à utiliser correctement et mis en œuvre de manière incohérente. En conséquence, il va probablement même être supprimé de Google Chrome.
Malgré tout cela, il est toujours défini comme une fonctionnalité dans HTTP/3 (bien que peu d'implémentations le prennent en charge). Bien que son fonctionnement interne n'ait pas autant changé que les deux fonctionnalités précédentes, il a également été adapté pour contourner l'ordre non déterministe de QUIC. Malheureusement, cela ne fera pas grand-chose pour résoudre certains de ses problèmes de longue date.
Qu'est-ce que tout cela veut dire?
Comme nous l'avons déjà dit, la majeure partie du potentiel de HTTP/3 provient du QUIC sous-jacent, et non de HTTP/3 lui-même. Bien que l'implémentation interne du protocole soit très différente de celle de HTTP/2, ses fonctionnalités de performances de haut niveau et la manière dont elles peuvent et doivent être utilisées sont restées les mêmes.
Développements futurs à surveiller
Dans cette série, j'ai régulièrement souligné qu'une évolution plus rapide et une plus grande flexibilité sont des aspects essentiels de QUIC (et, par extension, de HTTP/3). En tant que tel, il ne devrait pas être surprenant que des personnes travaillent déjà sur de nouvelles extensions et applications des protocoles. Vous trouverez ci-dessous les principaux que vous rencontrerez probablement quelque part sur la ligne :
Correction d'erreur directe
Le but de cette technique est, encore une fois, d' améliorer la résilience de QUIC à la perte de paquets . Pour ce faire, il envoie des copies redondantes des données (bien qu'intelligemment codées et compressées afin qu'elles ne soient pas aussi volumineuses). Ensuite, si un paquet est perdu mais que les données redondantes arrivent, une retransmission n'est plus nécessaire.
Cela faisait à l'origine partie de Google QUIC (et l'une des raisons pour lesquelles les gens disent que QUIC est bon contre la perte de paquets), mais il n'est pas inclus dans la version 1 standardisée de QUIC car son impact sur les performances n'a pas encore été prouvé. Cependant, les chercheurs effectuent maintenant des expériences actives avec lui, et vous pouvez les aider en utilisant l'application PQUIC-FEC Download Experiments.QUIC par trajets multiples
Nous avons déjà discuté de la migration de connexion et de la manière dont elle peut aider lors du passage, par exemple, du Wi-Fi au cellulaire. Cependant, cela n'implique-t-il pas également que nous pourrions utiliser à la fois le Wi-Fi et le cellulaire ? L'utilisation simultanée des deux réseaux nous donnerait plus de bande passante disponible et une robustesse accrue ! C'est le concept principal derrière multipath.
C'est, encore une fois, quelque chose que Google a expérimenté mais qui n'a pas été intégré à la version 1 de QUIC en raison de sa complexité inhérente. Cependant, les chercheurs ont depuis montré son potentiel élevé, et il pourrait être intégré à la version 2 de QUIC. Notez que le multichemin TCP existe également, mais qu'il a fallu près d'une décennie pour devenir pratiquement utilisable.Données non fiables sur QUIC et HTTP/3
Comme nous l'avons vu, QUIC est un protocole entièrement fiable. Cependant, comme il fonctionne sur UDP, qui n'est pas fiable, nous pouvons ajouter une fonctionnalité à QUIC pour envoyer également des données non fiables. Ceci est décrit dans l'extension de datagramme proposée. Bien sûr, vous ne voudriez pas l'utiliser pour envoyer des ressources de page Web, mais cela pourrait être pratique pour des choses telles que les jeux et le streaming vidéo en direct. De cette façon, les utilisateurs bénéficieraient de tous les avantages d'UDP, mais avec un cryptage de niveau QUIC et un contrôle de congestion (facultatif).WebTransport
Les navigateurs n'exposent pas TCP ou UDP directement à JavaScript, principalement pour des raisons de sécurité. Au lieu de cela, nous devons nous appuyer sur des API de niveau HTTP telles que Fetch et les protocoles WebSocket et WebRTC un peu plus flexibles. La plus récente de cette série d'options s'appelle WebTransport, qui vous permet principalement d'utiliser HTTP/3 (et, par extension, QUIC) de manière plus basique (bien qu'il puisse également revenir à TCP et HTTP/2 si nécessaire ).
Surtout, cela inclura la possibilité d'utiliser des données non fiables sur HTTP/3 (voir le point précédent), ce qui devrait faciliter un peu la mise en œuvre de choses telles que les jeux dans le navigateur. Pour les appels d'API normaux (JSON), vous utiliserez bien sûr toujours Fetch, qui utilisera également automatiquement HTTP/3 lorsque cela sera possible. WebTransport fait encore l'objet de vives discussions en ce moment, il n'est donc pas encore clair à quoi il ressemblera finalement. Parmi les navigateurs, seul Chromium travaille actuellement sur une implémentation publique de preuve de concept.Streaming vidéo DASH et HLS
Pour la vidéo non en direct (comme YouTube et Netflix), les navigateurs utilisent généralement les protocoles Dynamic Adaptive Streaming over HTTP (DASH) ou HTTP Live Streaming (HLS). Les deux signifient essentiellement que vous encodez vos vidéos en plus petits morceaux (de 2 à 10 secondes) et différents niveaux de qualité (720p, 1080p, 4K, etc.).
Au moment de l'exécution, le navigateur estime la qualité la plus élevée que votre réseau peut gérer (ou la plus optimale pour un cas d'utilisation donné), et il demande les fichiers pertinents au serveur via HTTP. Parce que le navigateur n'a pas d'accès direct à la pile TCP (comme cela est généralement implémenté dans le noyau), il fait parfois quelques erreurs dans ces estimations, ou il faut un certain temps pour réagir aux conditions changeantes du réseau (conduisant à des décrochages vidéo) .
Étant donné que QUIC est implémenté dans le cadre du navigateur, cela pourrait être considérablement amélioré, en donnant aux estimateurs de flux un accès aux informations de protocole de bas niveau (telles que les taux de perte, les estimations de bande passante, etc.). D'autres chercheurs ont également expérimenté le mélange de données fiables et non fiables pour le streaming vidéo, avec des résultats prometteurs.Protocoles autres que HTTP/3
QUIC étant un protocole de transport à usage général, nous pouvons nous attendre à ce que de nombreux protocoles de couche application qui s'exécutent désormais sur TCP soient également exécutés sur QUIC. Certains travaux en cours incluent DNS-over-QUIC, SMB-over-QUIC et même SSH-over-QUIC. Étant donné que ces protocoles ont généralement des exigences très différentes de HTTP et du chargement de pages Web, les améliorations de performances de QUIC dont nous avons discuté pourraient bien mieux fonctionner pour ces protocoles.
Qu'est-ce que tout cela veut dire?
La version 1 de QUIC n'est qu'un début . De nombreuses fonctionnalités avancées axées sur les performances que Google avait précédemment expérimentées n'ont pas été intégrées à cette première itération. Cependant, l'objectif est de faire évoluer rapidement le protocole, en introduisant de nouvelles extensions et fonctionnalités à une fréquence élevée. Ainsi, avec le temps, QUIC (et HTTP/3) devrait devenir nettement plus rapide et plus flexible que TCP (et HTTP/2).
Conclusion
Dans cette deuxième partie de la série, nous avons discuté des nombreuses fonctionnalités et aspects de performance différents de HTTP/3 et en particulier de QUIC. Nous avons vu que même si la plupart de ces fonctionnalités semblent avoir beaucoup d'impact, en pratique, elles pourraient ne pas faire grand-chose pour l'utilisateur moyen dans le cas d'utilisation du chargement de pages Web que nous avons envisagé.
Par exemple, nous avons vu que l'utilisation d'UDP par QUIC ne signifie pas qu'il peut soudainement utiliser plus de bande passante que TCP, ni qu'il peut télécharger vos ressources plus rapidement. La fonctionnalité 0-RTT souvent louée est en réalité une micro-optimisation qui vous évite un aller-retour, dans lequel vous pouvez envoyer environ 5 Ko (dans le pire des cas).
La suppression du blocage HoL ne fonctionne pas bien en cas de perte de paquets en rafale ou lorsque vous chargez des ressources bloquant le rendu. La migration de connexion est très situationnelle et HTTP/3 n'a pas de nouvelles fonctionnalités majeures qui pourraient le rendre plus rapide que HTTP/2.
En tant que tel, vous pourriez vous attendre à ce que je vous recommande de simplement ignorer HTTP/3 et QUIC. Pourquoi s'embêter, non ? Cependant, je ne ferai certainement rien de tel! Même si ces nouveaux protocoles n'aident pas beaucoup les utilisateurs sur les réseaux rapides (urbains), les nouvelles fonctionnalités ont certainement le potentiel d'avoir un impact considérable sur les utilisateurs très mobiles et les personnes sur des réseaux lents.
Même sur les marchés occidentaux comme ma propre Belgique, où nous avons généralement des appareils rapides et un accès aux réseaux cellulaires à haut débit, ces situations peuvent affecter 1 à 10 % de votre base d'utilisateurs, selon votre produit. Par exemple, quelqu'un dans un train essaie désespérément de rechercher une information essentielle sur votre site Web, mais doit attendre 45 secondes pour qu'elle se charge. Je sais certainement que j'ai été dans cette situation, souhaitant que quelqu'un ait déployé QUIC pour m'en sortir.
Cependant, il y a d'autres pays et régions où les choses sont encore bien pires. Là, l'utilisateur moyen pourrait ressembler beaucoup plus aux 10 % les plus lents de Belgique, et les 1 % les plus lents pourraient ne jamais voir une page chargée. Dans de nombreuses régions du monde, la performance Web est un problème d'accessibilité et d'inclusivité.
C'est pourquoi nous ne devons jamais simplement tester nos pages sur notre propre matériel (mais aussi utiliser un service comme Webpagetest) et aussi pourquoi vous devez absolument déployer QUIC et HTTP/3 . Surtout si vos utilisateurs sont souvent en déplacement ou peu susceptibles d'avoir accès à des réseaux cellulaires rapides, ces nouveaux protocoles pourraient faire toute la différence, même si vous ne remarquez pas grand-chose sur votre MacBook Pro câblé. Pour plus de détails, je recommande fortement le post de Fastly sur la question.
Si cela ne vous convainc pas entièrement, considérez que QUIC et HTTP/3 continueront d'évoluer et de s'accélérer dans les années à venir. Une première expérience avec les protocoles sera payante sur la route, vous permettant de profiter des avantages des nouvelles fonctionnalités dès que possible. De plus, QUIC applique les meilleures pratiques de sécurité et de confidentialité en arrière-plan, ce qui profite à tous les utilisateurs du monde entier.
Enfin convaincu ? Passez ensuite à la partie 3 de la série pour savoir comment utiliser les nouveaux protocoles dans la pratique.
- Partie 1 : Historique HTTP/3 et concepts de base
Cet article s'adresse aux personnes qui découvrent HTTP/3 et les protocoles en général, et il aborde principalement les bases. - Partie 2 : Fonctionnalités de performances HTTP/3
Celui-ci est plus approfondi et technique. Les personnes qui connaissent déjà les bases peuvent commencer ici. - Partie 3 : Options pratiques de déploiement HTTP/3
Ce troisième article de la série explique les défis liés au déploiement et au test de HTTP/3 vous-même. Il détaille comment et si vous devez également modifier vos pages Web et vos ressources.