
Création d'un flux de travail de test d'intégration continue à l'aide d'actions GitHub
Publié: 2022-03-10Lorsque vous contribuez à des projets sur des plates-formes de contrôle de version telles que GitHub et Bitbucket, la convention est qu'il existe la branche principale contenant la base de code fonctionnelle. Ensuite, il existe d'autres branches dans lesquelles plusieurs développeurs peuvent travailler sur des copies de la principale pour soit ajouter une nouvelle fonctionnalité, corriger un bogue, etc. Cela a beaucoup de sens car il devient plus facile de surveiller le type d'effet que les modifications entrantes auront sur le code existant. S'il y a une erreur, elle peut facilement être tracée et corrigée avant d'intégrer les modifications dans la branche principale. Il peut être fastidieux de parcourir manuellement chaque ligne de code à la recherche d'erreurs ou de bogues, même pour un petit projet. C'est là qu'intervient l'intégration continue.
Qu'est-ce que l'intégration continue (IC) ?
"L'intégration continue (CI) est la pratique consistant à automatiser l'intégration des modifications de code de plusieurs contributeurs dans un seul projet logiciel."
— Atlassian.com
L'idée générale derrière l'intégration continue (CI) est de s'assurer que les modifications apportées au projet ne "cassent pas la construction", c'est-à-dire ne ruinent pas la base de code existante. La mise en œuvre de l'intégration continue dans votre projet, selon la configuration de votre flux de travail, créerait une génération chaque fois que quelqu'un apporterait des modifications au référentiel.
Alors, qu'est-ce qu'une construction ?
Une construction - dans ce contexte - est la compilation du code source dans un format exécutable. Si cela réussit, cela signifie que les modifications entrantes n'auront pas d'impact négatif sur la base de code et qu'elles sont prêtes à partir. Cependant, si la construction échoue, les modifications devront être réévaluées. C'est pourquoi il est conseillé d'apporter des modifications à un projet en travaillant sur une copie du projet sur une branche différente avant de l'incorporer dans la base de code principale. De cette façon, si la construction échoue, il serait plus facile de déterminer d'où vient l'erreur, et cela n'affecte pas non plus votre code source principal.
« Plus tôt vous détectez les défauts, moins ils coûtent cher à réparer. »
— David Farley, Livraison continue : versions de logiciels fiables grâce à l'automatisation de la construction, des tests et du déploiement
Plusieurs outils sont disponibles pour vous aider à créer une intégration continue pour votre projet. Ceux-ci incluent Jenkins, TravisCI, CircleCI, GitLab CI, GitHub Actions, etc. Pour ce tutoriel, j'utiliserai GitHub Actions.
Actions GitHub pour l'intégration continue
CI Actions est une fonctionnalité relativement nouvelle sur GitHub et permet la création de flux de travail qui exécutent automatiquement la construction et les tests de votre projet. Un workflow contient un ou plusieurs travaux qui peuvent être activés lorsqu'un événement se produit. Cet événement peut être un push vers l'une des branches du référentiel ou la création d'une pull request. J'expliquerai ces termes en détail au fur et à mesure.
Commençons!
Conditions préalables
Il s'agit d'un didacticiel pour les débutants, je parlerai donc principalement de GitHub Actions CI au niveau de la surface. Les lecteurs doivent déjà être familiarisés avec la création d'une API Node JS REST à l'aide de la base de données PostgreSQL, Sequelize ORM et l'écriture de tests avec Mocha et Chai.
Vous devez également avoir les éléments suivants installés sur votre machine :
- NodeJS,
- PostgreSQL,
- MNP,
- VSCode (ou n'importe quel éditeur et terminal de votre choix).
Je vais utiliser une API REST que j'ai déjà créée et appelée countries-info-api . C'est une API simple sans autorisations basées sur les rôles (comme au moment de la rédaction de ce tutoriel). Cela signifie que n'importe qui peut ajouter, supprimer et/ou mettre à jour les détails d'un pays. Chaque pays aura un identifiant (UUID généré automatiquement), un nom, une capitale et une population. Pour y parvenir, j'ai utilisé Node js, express js framework et Postgresql pour la base de données.
Je vais expliquer brièvement comment j'ai configuré le serveur, la base de données avant de commencer à écrire les tests pour la couverture des tests et le fichier de workflow pour l'intégration continue.
Vous pouvez cloner le dépôt country countries-info-api pour suivre ou créer votre propre API.
Technologies utilisées : Node Js, NPM (un gestionnaire de paquets pour Javascript), base de données Postgresql, sequelize ORM, Babel.
Configuration du serveur
Avant de configurer le serveur, j'ai installé certaines dépendances de npm.
npm install express dotenv cors npm install --save-dev @babel/core @babel/cli @babel/preset-env nodemonJ'utilise le framework express et j'écris au format ES6, j'aurai donc besoin de Babeljs pour compiler mon code. Vous pouvez lire la documentation officielle pour en savoir plus sur son fonctionnement et comment le configurer pour votre projet. Nodemon détectera toute modification apportée au code et redémarrera automatiquement le serveur.
Remarque : les packages Npm installés à l'aide de l' --save-dev ne sont requis que pendant les étapes de développement et sont visibles sous devDependencies dans le fichier package.json .
J'ai ajouté ce qui suit à mon fichier index.js :
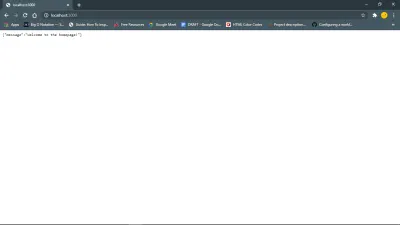
import express from "express"; import bodyParser from "body-parser"; import cors from "cors"; import "dotenv/config"; const app = express(); const port = process.env.PORT; app.use(bodyParser.json()); app.use(bodyParser.urlencoded({ extended: true })); app.use(cors()); app.get("/", (req, res) => { res.send({message: "Welcome to the homepage!"}) }) app.listen(port, () => { console.log(`Server is running on ${port}...`) }) Cela configure notre API pour qu'elle s'exécute sur tout ce qui est attribué à la variable PORT dans le fichier .env . C'est également là que nous déclarerons des variables auxquelles nous ne voulons pas que d'autres aient facilement accès. Le dotenv npm charge nos variables d'environnement à partir de .env .
Maintenant, quand je lance npm run start dans mon terminal, j'obtiens ceci :
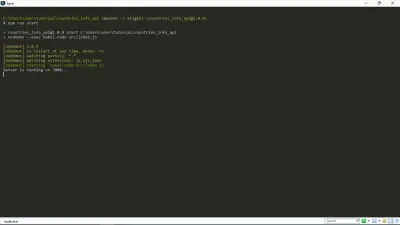
Comme vous pouvez le voir, notre serveur est opérationnel. Yay!
Ce lien https://127.0.0.1:your_port_number/ dans votre navigateur Web devrait renvoyer le message de bienvenue. Autrement dit, tant que le serveur est en cours d'exécution.
Ensuite, base de données et modèles.
J'ai créé le modèle de pays à l'aide de Sequelize et je me suis connecté à ma base de données Postgres. Sequelize est un ORM pour Nodejs. Un avantage majeur est qu'il nous fait gagner du temps lors de l'écriture de requêtes SQL brutes.
Puisque nous utilisons Postgresql, la base de données peut être créée via la ligne de commande psql en utilisant la commande CREATE DATABASE database_name . Cela peut également être fait sur votre terminal, mais je préfère PSQL Shell.
Dans le fichier env, nous allons configurer la chaîne de connexion de notre base de données, en suivant ce format ci-dessous.
TEST_DATABASE_URL = postgres://<db_username>:<db_password>@127.0.0.1:5432/<database_name>Pour mon modèle, j'ai suivi ce tutoriel de séquelle. Il est facile à suivre et explique tout sur la configuration de Sequelize.
Ensuite, je vais écrire des tests pour le modèle que je viens de créer et mettre en place la couverture sur Coverall.
Tests d'écriture et couverture des rapports
Pourquoi écrire des tests ? Personnellement, je pense que l'écriture de tests vous aide en tant que développeur à mieux comprendre comment votre logiciel est censé fonctionner entre les mains de votre utilisateur, car il s'agit d'un processus de brainstorming. Il vous aide également à découvrir les bugs à temps.
Essais :
Il existe différentes méthodes de test de logiciels, cependant, pour ce tutoriel, j'ai utilisé des tests unitaires et de bout en bout.
J'ai écrit mes tests en utilisant le framework de test Mocha et la bibliothèque d'assertions Chai. J'ai également installé sequelize-test-helpers pour aider à tester le modèle que j'ai créé à l'aide sequelize.define .

Couverture de test:
Il est conseillé de vérifier la couverture de vos tests car le résultat indique si nos cas de test couvrent réellement le code et également la quantité de code utilisée lorsque nous exécutons nos cas de test.
J'ai utilisé Istanbul (un outil de couverture de test), nyc (le client CLI d'Instabul) et Coveralls.
Selon la documentation, Istanbul instrumente votre code JavaScript ES5 et ES2015+ avec des compteurs de ligne, afin que vous puissiez suivre la façon dont vos tests unitaires exercent votre base de code.
Dans mon fichier package.json , le script de test exécute les tests et génère un rapport.
{ "scripts": { "test": "nyc --reporter=lcov --reporter=text mocha -r @babel/register ./src/test/index.js" } } Au cours du processus, il créera un dossier .nyc_output contenant les informations de couverture brutes et un dossier de coverage contenant les fichiers de rapport de couverture. Les deux fichiers ne sont pas nécessaires sur mon référentiel, je les ai donc placés dans le fichier .gitignore .
Maintenant que nous avons généré un rapport, nous devons l'envoyer à Coveralls. Une chose intéressante à propos de Coveralls (et d'autres outils de couverture, je suppose) est la façon dont il rapporte votre couverture de test. La couverture est ventilée fichier par fichier et vous pouvez voir la couverture pertinente, les lignes couvertes et manquées, et ce qui a changé dans la couverture de construction.
Pour commencer, installez le package coveralls npm. Vous devez également vous connecter aux combinaisons et y ajouter le dépôt.
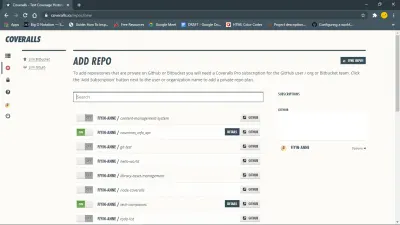
Configurez ensuite les combinaisons pour votre projet javascript en créant un fichier coveralls.yml dans votre répertoire racine. Ce fichier contiendra votre repo-token de dépôt obtenu à partir de la section des paramètres pour votre dépôt sur les combinaisons.
Un autre script nécessaire dans le fichier package.json est les scripts de couverture. Ce script sera utile lorsque nous créerons une version via Actions.
{ "scripts": { "coverage": "nyc npm run test && nyc report --reporter=text-lcov --reporter=lcov | node ./node_modules/coveralls/bin/coveralls.js --verbose" } }Fondamentalement, il exécutera les tests, obtiendra le rapport et l'enverra aux combinaisons pour analyse.
Passons maintenant au point principal de ce tutoriel.
Créer un fichier de flux de travail Node JS
À ce stade, nous avons configuré les tâches nécessaires que nous exécuterons dans notre action GitHub. (Vous vous demandez ce que signifient les « emplois » ? Continuez à lire.)
GitHub a facilité la création du fichier de workflow en fournissant un modèle de démarrage. Comme indiqué sur la page Actions, il existe plusieurs modèles de flux de travail à des fins différentes. Pour ce tutoriel, nous utiliserons le workflow Node.js (que GitHub a déjà gentiment suggéré).
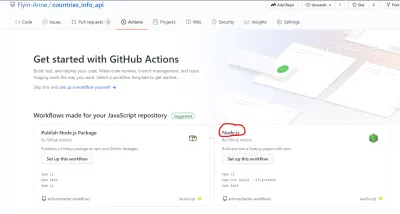
Vous pouvez modifier le fichier directement sur GitHub mais je créerai manuellement le fichier sur mon dépôt local. Le dossier .github/workflows contenant le fichier node.js.yml sera dans le répertoire racine.
Ce fichier contient déjà quelques commandes de base et le premier commentaire explique ce qu'elles font.
# This workflow will do a clean install of node dependencies, build the source code and run tests across different versions of nodeJe vais y apporter quelques modifications afin qu'en plus du commentaire ci-dessus, il gère également la couverture.
Mon fichier .node.js.yml :
name: NodeJS CI on: ["push"] jobs: build: name: Build runs-on: windows-latest strategy: matrix: node-version: [12.x, 14.x] steps: - uses: actions/checkout@v2 - name: Use Node.js ${{ matrix.node-version }} uses: actions/setup-node@v1 with: node-version: ${{ matrix.node-version }} - run: npm install - run: npm run build --if-present - run: npm run coverage - name: Coveralls uses: coverallsapp/github-action@master env: COVERALLS_REPO_TOKEN: ${{ secrets.COVERALLS_REPO_TOKEN }} COVERALLS_GIT_BRANCH: ${{ github.ref }} with: github-token: ${{ secrets.GITHUB_TOKEN }}Qu'est-ce que ça veut dire?
Décomposons-le.
-
name
Ce serait le nom de votre flux de travail (NodeJS CI) ou travail (build) et GitHub l'affichera sur la page d'actions de votre référentiel. -
on
Il s'agit de l'événement qui déclenche le workflow. Cette ligne dans mon fichier indique essentiellement à GitHub de déclencher le flux de travail chaque fois qu'une poussée est effectuée vers mon référentiel. -
jobs
Un flux de travail peut contenir au moins un ou plusieurs travaux et chaque travail s'exécute dans un environnement spécifié parruns-on. Dans l'exemple de fichier ci-dessus, il n'y a qu'un seul travail qui exécute la construction et exécute également la couverture, et il s'exécute dans un environnement Windows. Je peux également le séparer en deux tâches différentes comme celle-ci :
Mise à jour du fichier Node.yml
name: NodeJS CI on: [push] jobs: build: name: Build runs-on: windows-latest strategy: matrix: node-version: [12.x, 14.x] steps: - uses: actions/checkout@v2 - name: Use Node.js ${{ matrix.node-version }} uses: actions/setup-node@v1 with: node-version: ${{ matrix.node-version }} - run: npm install - run: npm run build --if-present - run: npm run test coverage: name: Coveralls runs-on: windows-latest strategy: matrix: node-version: [12.x, 14.x] steps: - uses: coverallsapp/github-action@master env: COVERALLS_REPO_TOKEN: ${{ secrets.COVERALLS_REPO_TOKEN }} with: github-token: ${{ secrets.GITHUB_TOKEN }}-
env
Celui-ci contient les variables d'environnement qui sont disponibles pour tous les travaux et étapes spécifiques du flux de travail. Dans le travail de couverture, vous pouvez voir que les variables d'environnement ont été "masquées". Ils peuvent être trouvés dans la page des secrets de votre référentiel sous les paramètres. -
steps
Il s'agit essentiellement d'une liste des étapes à suivre lors de l'exécution de ce travail. - Le travail de
buildfait un certain nombre de choses :- Il utilise une action de paiement (v2 signifie la version) qui extrait littéralement votre référentiel afin qu'il soit accessible par votre flux de travail ;
- Il utilise une action setup-node qui configure l'environnement de nœud à utiliser ;
- Il exécute les scripts d'installation, de construction et de test trouvés dans notre fichier package.json.
-
coverage
Cela utilise une action coverallsapp qui publie les données de couverture LCOV de votre suite de tests sur coveralls.io pour analyse.
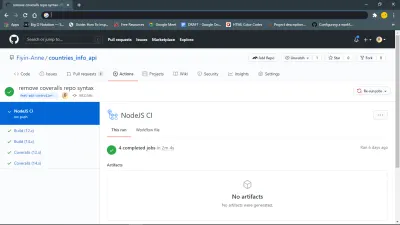
J'ai d'abord fait un push vers ma branche feat-add-controllers-and-route et j'ai oublié d'ajouter le repo_token de Coveralls à mon fichier .coveralls.yml , donc j'ai eu l'erreur que vous pouvez voir à la ligne 132.
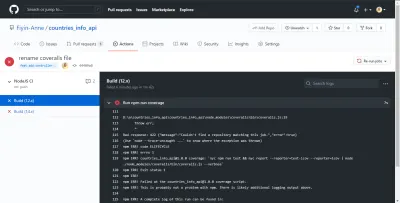
Bad response: 422 {"message":"Couldn't find a repository matching this job.","error":true} Une fois que j'ai ajouté le repo_token , ma construction a pu s'exécuter avec succès. Sans ce jeton, les combinaisons ne seraient pas en mesure de rapporter correctement mon analyse de couverture de test. Heureusement, notre GitHub Actions CI a signalé l'erreur avant qu'elle ne soit poussée vers la branche principale.
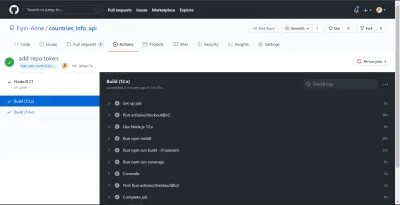
NB : Celles-ci ont été prises avant que je sépare le poste en deux postes. De plus, j'ai pu voir le résumé de la couverture et le message d'erreur sur mon terminal car j'ai ajouté l'indicateur --verbose à la fin de mon script de couverture
Conclusion
Nous pouvons voir comment mettre en place une intégration continue pour nos projets et également intégrer une couverture de test à l'aide des Actions mises à disposition par GitHub. Il existe de nombreuses autres façons de l'ajuster pour répondre aux besoins de votre projet. Bien que l'exemple de référentiel utilisé dans ce didacticiel soit un projet vraiment mineur, vous pouvez voir à quel point l'intégration continue est essentielle, même dans un projet plus important. Maintenant que mes tâches ont été exécutées avec succès, je suis sûr de fusionner la branche avec ma branche principale. Je vous conseillerais toujours de lire également les résultats des étapes après chaque exécution pour voir qu'il est complètement réussi.