
Marcos de datos en Python: Tutorial detallado de Python 2022
Publicado: 2021-01-09Si es un desarrollador o codificador que trabaja en el lenguaje de programación Python, debe estar familiarizado con una de las bibliotecas de administración de datos más sorprendentes que existen: Pandas, una de las mejores bibliotecas de Python que existen. A lo largo de los años, Pandas se ha convertido en una herramienta estándar para el análisis y la gestión de datos mediante Python. Lea sobre otras herramientas importantes de Python.
Pandas es, sin duda, el paquete de Python más versátil para la ciencia de datos y con razón. Proporciona estructuras de datos potentes, expresivas y flexibles para una fácil manipulación y análisis de datos, y Data Frames en Python es una de estas estructuras.
Estos son precisamente nuestros temas de discusión en esta publicación: le presentaremos el formato de datos básico para Pandas, es decir, el marco de datos de Pandas.
Tabla de contenido
¿Qué es un marco de datos?
De acuerdo con la documentación de la biblioteca Pandas , un marco de datos es una "estructura de datos tabulares bidimensionales, de tamaño variable y potencialmente heterogénea con ejes etiquetados (filas y columnas)". En palabras simples, un marco de datos es una estructura de datos en la que los datos se alinean de forma tabular, es decir, en filas y columnas.
Un Data Frame suele tener las siguientes características:
- Puede tener varias filas y columnas.
- Si bien cada fila representa una muestra de datos, cada columna comprende una variable diferente que describe las muestras (filas).
- Los datos de cada columna suelen ser del mismo tipo de datos (por ejemplo, números, cadenas, fechas, etc.).
- A diferencia de los conjuntos de datos de Excel, evita que falten valores, por lo que no hay espacios ni valores vacíos entre filas o columnas.
En un marco de datos de Pandas, también puede especificar los nombres de índice y columna para su marco de datos. Mientras que el índice indica la diferencia en las filas, los nombres de las columnas muestran la diferencia en las columnas.
Cómo crear un marco de datos en Python (usando Pandas)
La creación de un marco de datos es el primer paso para la manipulación de datos en Python. Puede crear un marco de datos de Pandas usando entradas como:
- dictado
- Liza
- Serie
- Numpy "ndarray"
- Otro marco de datos
- Archivos externos como CS
- Creación de un marco de datos vacío
Es bastante fácil crear un marco de datos básico, también conocido como un marco de datos vacío. Aquí hay un ejemplo:
Aporte -

Producción -

- Creación de un marco de datos a partir de listas
Puede crear un marco de datos utilizando una sola lista o varias listas.
Aporte -

Producción -

- Creación de un marco de datos a partir de dictados de "ndarrays" o listas
Para crear un marco de datos a partir de un dict de ndarrays, todos los ndarrays deben tener la misma longitud. Además, si está indexado, la longitud del índice debe ser igual a la longitud de las matrices. Sin embargo, si no está indexado, el índice será range(n) de forma predeterminada, donde 'n' denota la longitud de la matriz.
Aporte -

Producción -

Aquí los valores 0,1,2,3 son el índice predeterminado asignado a cada fila usando la función range(n).
¿Cuáles son las operaciones fundamentales del marco de datos?
Ahora que hemos visto tres formas de crear marcos de datos en Python, es hora de aprender sobre las diferentes operaciones dentro de un marco de datos.
- Selección de un índice o columna de un marco de datos de Pandas
Es importante saber cómo seleccionar un índice o una columna antes de poder comenzar a agregar, eliminar y cambiar el nombre de los componentes dentro de un DataFrame. Supongamos que este es su marco de datos:

Desea acceder al valor bajo el índice 0 en la columna 'A'; el valor es 1. Hay muchas formas de acceder a este valor, pero dos de las más importantes son: .loc[] y .iloc[].
Aporte -
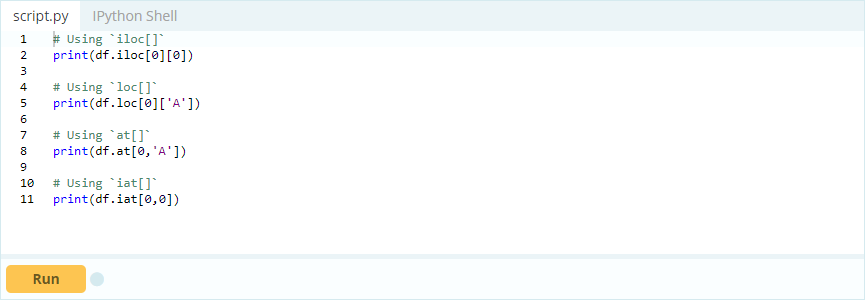
Producción -
Entonces, como puede ver, puede acceder a los valores llamándolos por su etiqueta o declarando su posición en el índice o columna. Si bien esto fue seleccionar un valor de un marco de datos, ¿cómo puede seleccionar filas y columnas del mismo?
Así es como:
Aporte -
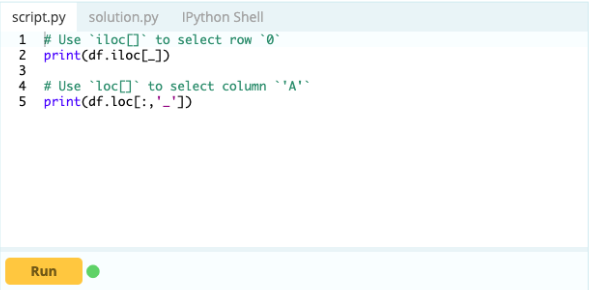
Producción-

- Cómo agregar un índice, una fila o una columna a un marco de datos de Pandas
Una vez que aprenda cómo acceder a los valores y seleccionar columnas de un marco de datos, puede aprender a agregar índices, filas o columnas en un marco de datos de Pandas.
Agregar un índice:
Al crear un marco de datos, puede optar por agregar una entrada al argumento 'índice'. Esto asegura que pueda acceder fácilmente al índice que desee. Si no especifica el índice, de forma predeterminada, se le agregará un índice de valor numérico que comienza con 0 y continúa hasta la última fila del DataFrame. Aunque, incluso después de especificar el índice de forma predeterminada, puede usar una columna y convertirla en un índice llamando a la función set_index() en el marco de datos.

Agregar una fila:
Puede agregar filas a un DataFrame usando la función de agregar.
Aporte -

Producción -

También puede usar .loc para insertar filas en su DataFrame así:
Aporte -
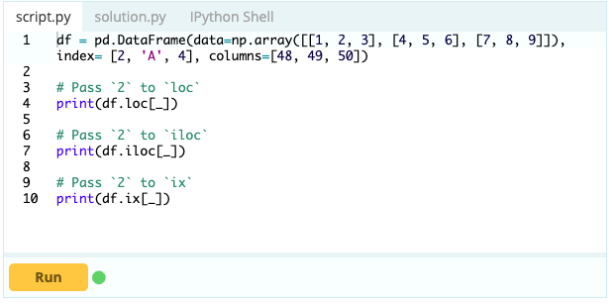
Producción -
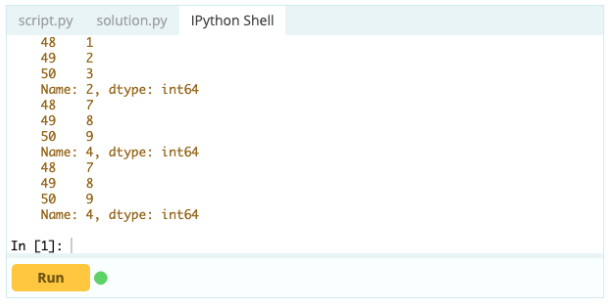
Agregar una columna
Si desea que un índice forme parte de un marco de datos, puede tomar una columna del marco de datos o hacer referencia a una columna que aún no se ha creado y asignarla a la propiedad .index de esta manera:
Aporte -
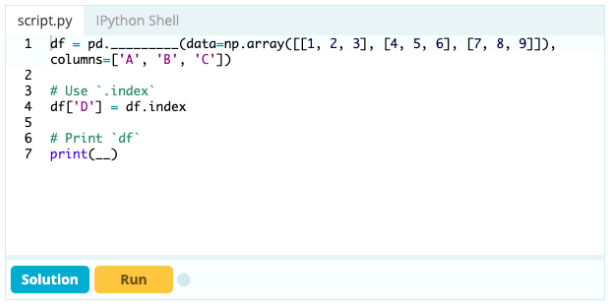
Producción -

Para agregar columnas a un marco de datos, también puede usar el mismo enfoque que usaría para agregar un índice al marco de datos, es decir, puede usar la función .loc[ ] o .iloc[ ]. Por ejemplo:
Aporte -

Producción
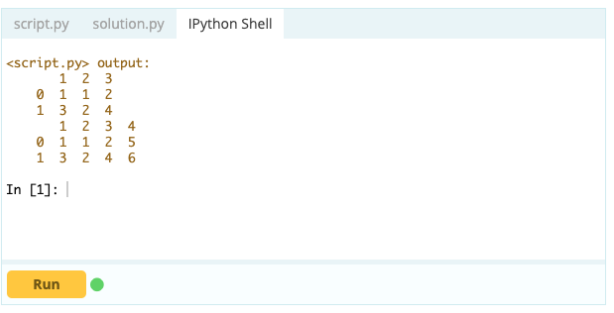
Con .loc[ ], puede agregar una serie a un marco de datos existente. Dado que un objeto Serie es bastante similar a una columna de un Marco de datos, es muy fácil agregar una Serie a un Marco de datos existente.
- ¿Cómo restablecer el índice de un marco de datos?
Puede restablecer el índice de un marco de datos si no tiene la forma deseada. Puede usar la función .reset_index() para hacer esto.
Aporte -
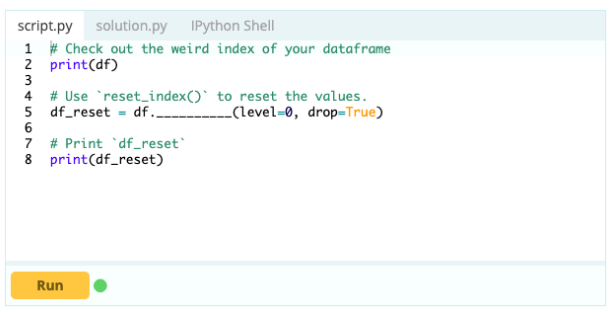
Producción -
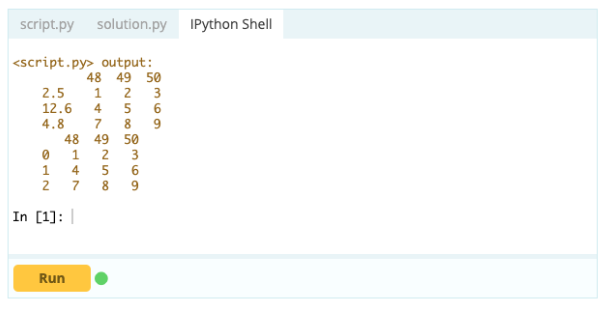
- Cómo eliminar un índice, una fila o una columna en un marco de datos de Pandas
Eliminación de un índice
- Restablecimiento del índice del marco de datos.
- Elimine el nombre del índice (si lo hay) mediante la función del df.index.name.
- Eliminar un índice junto con una fila.
- Elimine todos los valores de índice duplicados restableciendo el índice, descartando los duplicados de la columna de índice que se agregó al marco de datos y restableciendo la nueva columna (sin un índice duplicado) nuevamente como índice.
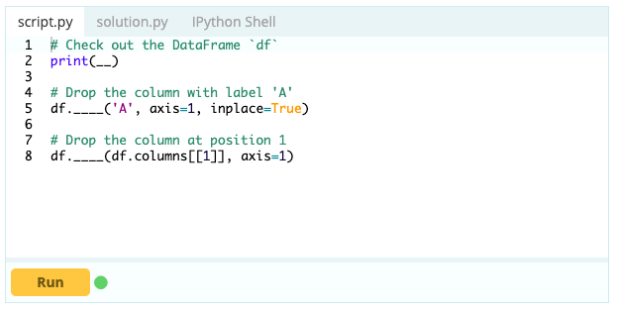
Eliminación de una columna
Para eliminar columnas de un marco de datos, puede usar la función drop().
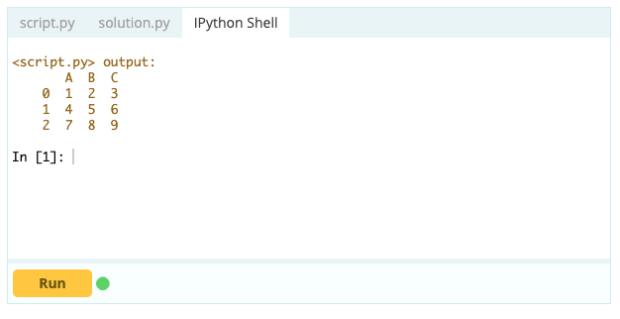
Aporte -
Producción -
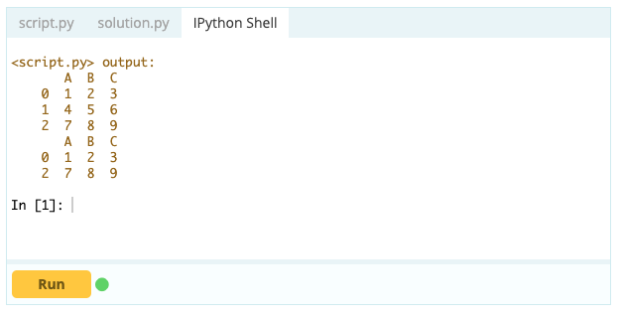
Eliminación de una fila
Para eliminar una fila de un marco de datos, puede usar la función drop() utilizando la propiedad index para especificar el índice de las filas que desea eliminar del marco de datos.
Aporte -

Producción -
Sin embargo, para eliminar filas duplicadas, puede usar la función df.drop_duplicates().
Aporte -
Producción -

Fuentes: Tutorialspoint Datacamp
Conclusión
Entonces, hay un tutorial básico para Data Frame en Python usando Pandas.
Si está interesado en aprender Python, ciencia de datos, consulte el Diploma PG en ciencia de datos de IIIT-B y upGrad, creado para profesionales que trabajan y ofrece más de 10 estudios de casos y proyectos, talleres prácticos, tutoría con expertos de la industria, 1 a 1 con mentores de la industria, más de 400 horas de aprendizaje y asistencia laboral con las mejores empresas.
¿Por qué Pandas es una de las bibliotecas preferidas para crear marcos de datos en Python?
Se considera que la biblioteca de Pandas es la más adecuada para crear marcos de datos, ya que proporciona varias funciones que hacen que sea eficiente para crear un marco de datos. Algunas de estas características son las siguientes: Pandas nos proporciona varios marcos de datos que no solo permiten una representación eficiente de los datos, sino que también nos permiten manipularlos. Proporciona características eficientes de alineación e indexación que brindan formas inteligentes de etiquetar y organizar los datos. Algunas características de Pandas hacen que el código sea limpio y aumentan su legibilidad, haciéndolo así más eficiente. También puede leer múltiples formatos de archivo. JSON, CSV, HDF5 y Excel son algunos de los formatos de archivo compatibles con Pandas. La fusión de múltiples conjuntos de datos ha sido un verdadero desafío para muchos programadores. Los pandas también superan esto y fusionan múltiples conjuntos de datos de manera muy eficiente.
¿Cuáles son las otras bibliotecas y herramientas que complementan la biblioteca de Pandas?
Pandas no solo funciona como una biblioteca central para crear marcos de datos, sino que también funciona con otras bibliotecas y herramientas de Python para ser más eficiente. Pandas se basa en el paquete NumPy Python, lo que indica que la mayor parte de la estructura de la biblioteca de Pandas se replica desde el paquete NumPy. El análisis estadístico de los datos en la biblioteca de Pandas es operado por SciPy, las funciones de trazado en Matplotlib y los algoritmos de aprendizaje automático en Scikit-learn. Jupyter Notebook es un entorno interactivo basado en web que funciona como un IDE y ofrece un buen entorno para Pandas.
¿Cuáles son las operaciones fundamentales del marco de datos?
Es importante seleccionar un índice o una columna antes de iniciar cualquier operación, como agregar o eliminar. Una vez que aprenda cómo acceder a los valores y seleccionar columnas de un marco de datos, puede aprender a agregar índices, filas o columnas en un marco de datos de Pandas. Si el índice en el marco de datos no resulta ser el deseado, puede restablecerlo. Para restablecer el índice, puede utilizar la función "reset_index()".