
Ultimativer Leitfaden zur Objekterkennung mit Deep Learning [2022]
Veröffentlicht: 2021-01-08Inhaltsverzeichnis
Einführung
Die Objekterkennung ist vereinfacht gesagt eine Methode, mit der verschiedene Objekte in einem Bild oder Video erkannt und erkannt und gekennzeichnet werden, um diese Objekte zu klassifizieren. Die Objekterkennung verwendet typischerweise verschiedene Algorithmen, um diese Erkennung und Lokalisierung von Objekten durchzuführen, und diese Algorithmen nutzen Deep Learning , um aussagekräftige Ergebnisse zu generieren.
Objekterkennung
Die Objekterkennungstechnik hilft bei der Erkennung, Erkennung und Lokalisierung mehrerer visueller Instanzen von Objekten in einem Bild oder Video. Es bietet ein viel besseres Verständnis des Objekts als Ganzes als nur eine grundlegende Objektklassifizierung. Diese Methode kann verwendet werden, um die Anzahl der Instanzen von eindeutigen Objekten zu zählen und ihre genauen Positionen zusammen mit der Beschriftung zu markieren. Mit der Zeit hat sich auch die Leistung dieses Prozesses erheblich verbessert, was uns bei Echtzeit-Anwendungsfällen hilft. Alles in allem beantwortet es die Frage: „Welcher Gegenstand ist wo und wie viel davon ist da?“.
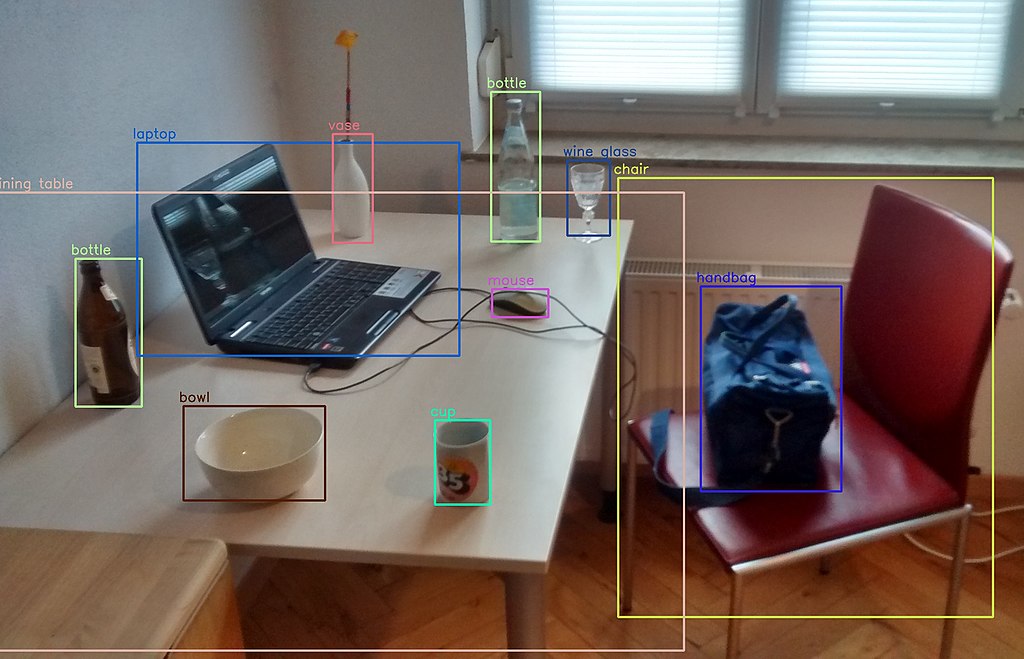
Quelle
Was ist ein Objekt?
Ein Objekt ist ein visuell darstellbares Element. Die physikalischen Eigenschaften eines Objekts weisen keine große Schwankungsbreite auf. Ein Objekt muss halbstarr sein, um erkannt und unterschieden zu werden.
Geschichte der Objekterkennung
In den letzten 20 Jahren hat der Fortschritt der Objekterkennung im Allgemeinen zwei bedeutende Entwicklungsperioden durchlaufen, beginnend mit den frühen 2000er Jahren:
1. Traditionelle Objekterkennung – Anfang der 2000er bis 2014.

2. Deep-Learning-basierte Erkennung – nach 2014.
Die technische Evolution der Objekterkennung begann in den frühen 2000er Jahren und den damaligen Detektoren. Sie folgten der Low-Level- und Mid-Level-Vision und folgten der Methode der „Erkennung anhand von Komponenten“. Diese Methode ermöglichte die Objekterkennung als Maß für die Ähnlichkeit zwischen den Objektkomponenten, Formen und Konturen, und die berücksichtigten Merkmale waren Abstandstransformationen, Formkontexte und Kantenlosigkeit usw. Die Dinge liefen nicht gut und dann maschinelle Erkennungsmethoden begann ins Bild zu kommen, um dieses Problem zu lösen.
Eine skalenübergreifende Erkennung von Objekten sollte durch die Berücksichtigung von Objekten mit „unterschiedlichen Größen“ und „unterschiedlichen Seitenverhältnissen“ erfolgen. Dies war in den Anfangsphasen eine der größten technischen Herausforderungen bei der Objekterkennung . Aber nach 2014, mit der Zunahme des technischen Fortschritts, wurde das Problem gelöst. Dies brachte uns zur zweiten Phase der Objekterkennung , in der die Aufgaben mithilfe von Deep Learning gelöst wurden.
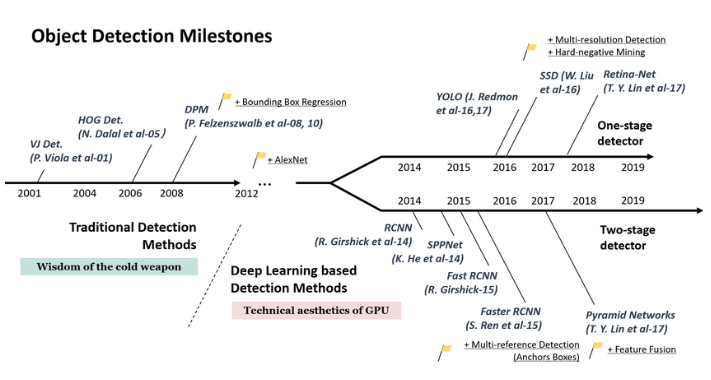
Quelle
Konzept
Das Hauptkonzept hinter diesem Prozess ist, dass jedes Objekt seine Eigenschaften hat. Diese Merkmale können uns helfen, Objekte von den anderen zu trennen. Die Objekterkennungsmethodik verwendet diese Merkmale, um die Objekte zu klassifizieren. Das gleiche Konzept wird für Dinge wie Gesichtserkennung, Fingerabdruckerkennung usw. verwendet.
Nehmen wir ein Beispiel: Wenn wir zwei Autos auf der Straße haben, können wir sie mithilfe des Objekterkennungsalgorithmus klassifizieren und kennzeichnen.
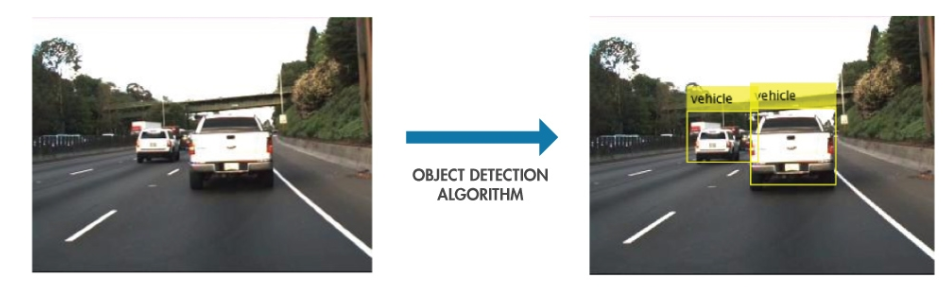
Quelle :
Definition
Die Objekterkennung ist ein Prozess, bei dem alle möglichen Instanzen realer Objekte wie menschliche Gesichter, Blumen, Autos usw. in Bildern oder Videos in Echtzeit mit höchster Genauigkeit gefunden werden. Die Objekterkennungstechnik verwendet abgeleitete Merkmale und Lernalgorithmen, um alle Vorkommen einer Objektkategorie zu erkennen. Die realen Anwendungen der Objekterkennung sind Bildabruf, Sicherheit und Überwachung, fortschrittliche Fahrerassistenzsysteme, auch bekannt als ADAS, und viele andere.
Lesen Sie: Top 10 Deep-Learning-Techniken
Allgemeine Beschreibung der Objekterkennung
Wir Menschen können verschiedene Objekte erkennen, die vor uns vorhanden sind, und wir können sie auch alle mit Genauigkeit identifizieren. Es ist für uns sehr einfach, mehrere Objekte ohne Aufwand zu zählen und zu identifizieren. Jüngste technologische Entwicklungen haben zur Verfügbarkeit großer Datenmengen geführt, um effiziente Algorithmen zu trainieren und Computer dazu zu bringen, die gleiche Aufgabe der Klassifizierung und Erkennung zu übernehmen.
Es gibt so viele Begriffe im Zusammenhang mit der Objekterkennung wie Computer Vision, Objektlokalisierung, Objektklassifizierung usw. und es könnte Sie als Anfänger überfordern, also teilen Sie uns all diese Begriffe und ihre Definitionen Schritt für Schritt mit:
- Computer Vision: Es ist ein Bereich der künstlichen Intelligenz, der es uns ermöglicht, Computern beizubringen, die visuellen Elemente von Bildern und Videos mithilfe von Algorithmen und Modellen zu verstehen und zu interpretieren.
- Bildklassifizierung: Es geht um die Erkennung und Kennzeichnung von Bildern mithilfe künstlicher Intelligenz. Diese Bilder werden anhand der von den Benutzern angegebenen Merkmale klassifiziert.
- Objektlokalisierung: Es beinhaltet die Erkennung verschiedener Objekte in einem bestimmten Bild und zieht eine Grenze um sie herum, meistens eine Box, um sie zu klassifizieren.
- Objekterkennung: Es umfasst beide Prozesse und klassifiziert die Objekte, zieht dann Grenzen für jedes Objekt und beschriftet sie gemäß ihren Merkmalen.
Alle diese Merkmale bilden den Objekterkennungsprozess.
Wie funktioniert die Objekterkennung?
Jetzt, da wir die Objekterkennung durchlaufen haben und wissen, was es ist, ist es jetzt an der Zeit zu wissen, wie es funktioniert und was es zum Funktionieren bringt. Wir können eine Vielzahl von Ansätzen haben, aber es gibt zwei Hauptansätze – einen maschinellen Lernansatz und einen Deep-Learning-Ansatz. Beide Ansätze sind in der Lage, die Objekte zu lernen und zu identifizieren, aber die Ausführung ist sehr unterschiedlich.
Lesen Sie auch: TensorFlow-Tutorial zur Objekterkennung
Methoden zur Objekterkennung
Die Objekterkennung kann durch einen maschinellen Lernansatz und einen Deep-Learning-Ansatz erfolgen. Der maschinelle Lernansatz erfordert, dass die Merkmale mithilfe verschiedener Methoden definiert werden und dann eine beliebige Technik wie Support Vector Machines (SVMs) verwendet wird, um die Klassifizierung durchzuführen. Der Deep-Learning-Ansatz hingegen ermöglicht es, den gesamten Erkennungsprozess durchzuführen, ohne die Merkmale für die Klassifizierung explizit zu definieren. Der Deep-Learning-Ansatz basiert hauptsächlich auf Convolutional Neural Networks (CNNs).
Methoden des maschinellen Lernens
- Skalierungsinvariante Merkmalstransformation (SIFT)
- Histogram of Oriented Gradients (HOG) Features
- Viola-Jones-Framework zur Objekterkennung
Deep-Learning-Methoden
- Regionsvorschläge (R-CNN, Fast R-CNN, Faster R-CNN)
- Du schaust nur einmal (YOLO)
- Verformbare Faltungsnetzwerke
- Refinement Neuronales Netzwerk zur Objekterkennung (RefineDet)
- Retina-Netz
Wir werden die Deep-Learning-Methoden im Detail kennenlernen, aber lassen Sie uns zuerst wissen, was maschinelles Lernen ist, was Deep Learning ist und was der Unterschied zwischen ihnen ist.
Was ist maschinelles Lernen?
Maschinelles Lernen ist die Anwendung künstlicher Intelligenz, um Computer dazu zu bringen, aus den ihnen gegebenen Daten zu lernen und dann ähnlich wie Menschen selbstständig Entscheidungen zu treffen. Es gibt Computern die Fähigkeit zu lernen und Vorhersagen zu treffen, basierend auf den Daten und Informationen, die ihnen zugeführt werden, sowie auf realen Interaktionen und Beobachtungen. Maschinelles Lernen ist im Grunde der Prozess, bei dem Algorithmen verwendet werden, um Daten zu analysieren und dann daraus zu lernen, um Vorhersagen zu treffen und Dinge auf der Grundlage der gegebenen Daten zu bestimmen.
Machine-Learning-Algorithmen können Entscheidungen selbst treffen, ohne explizit dafür programmiert zu sein. Diese Algorithmen erstellen mathematische Modelle auf der Grundlage der gegebenen Daten, die als „Trainingssatz“ bekannt sind, um die Vorhersagen zu treffen. Bei maschinellen Lernalgorithmen müssen wir dem System die Funktionen bereitstellen, damit sie das Lernen basierend auf den gegebenen Funktionen durchführen. Dieser Prozess wird Feature Engineering genannt.
Die alltäglichen Beispiele für Anwendungen des maschinellen Lernens sind Sprachassistenten, E-Mail-Spam-Filterung, Produktempfehlungen usw.
Was ist Deep Learning?
Deep Learning, das manchmal auch als Deep Structured Learning bezeichnet wird, ist eine Klasse von Algorithmen für maschinelles Lernen. Deep Learning verwendet einen mehrschichtigen Ansatz, um High-Level-Features aus den bereitgestellten Daten zu extrahieren. Es erfordert nicht, dass die Merkmale manuell zur Klassifizierung bereitgestellt werden, sondern versucht stattdessen, seine Daten in eine abstrakte Darstellung umzuwandeln. Es lernt einfach anhand von Beispielen und verwendet es für zukünftige Klassifizierungen. Deep Learning wird durch die in unserem Gehirn vorhandenen künstlichen neuronalen Netze (KNN) beeinflusst.
Die meisten Deep-Learning-Methoden implementieren neuronale Netze, um die Ergebnisse zu erzielen. Alle Deep-Learning-Modelle erfordern enorme Rechenleistung und große Mengen an gekennzeichneten Daten, um die Merkmale direkt aus den Daten zu lernen. Die täglichen Anwendungen von Deep Learning sind Nachrichtenaggregation oder Betrugsnachrichtenerkennung, visuelle Erkennung, Verarbeitung natürlicher Sprache usw.

 Quelle
Quelle
Objekterkennung mit Deep Learning
Nachdem wir uns nun sehr gut mit Objekterkennung und Deep Learning auskennen, sollten wir wissen, wie wir Objekterkennung mit Deep Learning durchführen können .
Dies sind die am häufigsten verwendeten Deep-Learning-Modelle zur Objekterkennung:
1. R-CNN-Modellfamilie: Sie steht für Region-based Convolutional Neural Networks
- R-CNN
- Schnelles R-CNN
- Schnelleres R-CNN
2. YOLO-Modellfamilie: Sie steht für You Look Only Once
- YOLOv1
- YOLOv2 und YOLOv3
Lassen Sie uns sie einzeln betrachten und verstehen, wie sie funktionieren.
Der Objekterkennungsprozess umfasst die folgenden Schritte:
- Das Visuelle als Input nehmen, entweder durch ein Bild oder ein Video.
- Unterteilen Sie das Eingabebild in Abschnitte oder Regionen.
- Nehmen Sie jeden Abschnitt einzeln auf und bearbeiten Sie ihn als einzelnes Bild
- Übergeben dieser Bilder an unser Convolutional Neural Network (CNN), um sie in mögliche Klassen zu klassifizieren.
- Nach der Klassifizierung können wir alle Bilder kombinieren und das ursprüngliche Eingabebild generieren, aber auch mit den erkannten Objekten und ihren Etiketten.
Regionsbasierte Convolutional Neural Networks (R-CNN)-Familie
Unter der R-CNN-Familie gibt es mehrere Objekterkennungsmodelle. Diese Erkennungsmodelle basieren auf den Regionenvorschlagsstrukturen. Diese Funktionen haben sich im Laufe der Zeit stark weiterentwickelt und die Genauigkeit und Effizienz erhöht.
Die verschiedenen Modelle unter R-CNN sind:
- R-CNN
Die R-CNN-Methode verwendet einen Prozess namens selektive Suche, um die Objekte aus dem Bild zu finden. Dieser Algorithmus generiert eine große Anzahl von Regionen und bearbeitet diese gemeinsam. Diese Sammlungen von Bereichen werden auf das Vorhandensein von Objekten geprüft, wenn sie irgendein Objekt enthalten. Der Erfolg dieser Methode hängt von der Genauigkeit der Klassifizierung von Objekten ab.
- Schnell-RCNN
Das Fast-RCNN-Verfahren verwendet die Struktur von R-CNN zusammen mit dem SPP-Netz (Spatial Pyramid Pooling), um das langsame R-CNN-Modell schneller zu machen. Das Fast-RCNN verwendet das SPP-Netz, um die CNN-Darstellung für das gesamte Bild nur einmal zu berechnen. Es verwendet dann diese Darstellung, um die CNN-Darstellung für jeden Patch zu berechnen, der durch den selektiven Suchansatz von R-CNN erzeugt wird. Das Fast-RCNN macht den Prozesszug von Ende zu Ende.
Das Fast-RCNN-Modell umfasst neben dem Trainingsprozess auch die Bounding-Box-Regression. Dadurch werden sowohl der Lokalisierungs- als auch der Klassifizierungsprozess in einem einzigen Prozess ausgeführt, was den Prozess beschleunigt.
- Schneller-RCNN
Das Faster-RCNN-Verfahren ist sogar noch schneller als das Fast-RCNN. Das Fast-RCNN war schnell, aber der Prozess der selektiven Suche und dieser Prozess wird in Faster-RCNN durch die Implementierung von RPN (Region Proposal Network) ersetzt. Das RPN beschleunigt den Auswahlprozess, indem es ein kleines Faltungsnetzwerk implementiert, das wiederum interessierende Regionen erzeugt. Zusammen mit RPN verwendet diese Methode auch Ankerboxen, um die verschiedenen Seitenverhältnisse und den Maßstab von Objekten zu handhaben. Faster-RCNN ist einer der genauesten und effizientesten Objekterkennungsalgorithmen.
| R-CNN | Schnell-RCNN | Schneller-RCNN | |
| Testzeit pro Bild | 50 Sekunden | 2 Sekunden | 0,2 Sekunden |
| Geschwindigkeit | 1x | 25x | 250x |
You Look Only Once (YOLO) Familie
Der R-CNN-Ansatz, den wir oben gesehen haben, konzentriert sich auf die Aufteilung eines Bildmaterials in Teile und konzentriert sich auf die Teile, die mit höherer Wahrscheinlichkeit ein Objekt enthalten, während sich das YOLO-Framework auf das gesamte Bild als Ganzes konzentriert und die Begrenzungsrahmen vorhersagt , berechnet dann seine Klassenwahrscheinlichkeiten, um die Kästchen zu beschriften. Die Familie der YOLO-Frameworks sind sehr schnelle Objektdetektoren.
Die verschiedenen Modelle von YOLO werden im Folgenden besprochen:
- YOLOv1
Dieses Modell wird auch als YOLO Unified bezeichnet, da dieses Modell die Objekterkennung und das Klassifizierungsmodell als ein einziges Erkennungsnetzwerk vereint. Dies war der erste Versuch, ein Netzwerk zu schaffen, das Objekte in Echtzeit sehr schnell erkennt. YOLO sagt nur eine begrenzte Anzahl von Begrenzungsrahmen voraus, um dieses Ziel zu erreichen.
- YOLOv2 und v3
YOLOv2 und YOLOv3 sind die erweiterten Versionen des YOLOv1-Frameworks. YOLOv2 wird auch YOLO9000 genannt. Das YOLOv1-Framework macht mehrere Lokalisierungsfehler, und YOLOv2 verbessert dies, indem es sich auf den Abruf und die Lokalisierung konzentriert. Das YOLOv2 verwendet Batch-Normalisierung, Ankerboxen, hochauflösende Klassifikatoren, feinkörnige Funktionen, mehrstufige Klassifikatoren und Darknet19. All diese Funktionen machen v2 besser als v1. Der Darknet19 Feature Extractor enthält 19 Faltungsschichten, 5 Max-Pooling-Schichten und eine Softmax-Schicht für die Klassifizierung von Objekten, die im Bild vorhanden sind.
Die YOLOv3-Methode ist die schnellste und genaueste Objekterkennungsmethode. Es klassifiziert die Objekte mithilfe logistischer Klassifikatoren im Vergleich zum Softmax-Ansatz von YOLOv2 genau. Dadurch sind wir in der Lage, Multi-Label-Klassifizierungen vorzunehmen. Das YOLOv3 verwendet auch Darknet53 als Feature Extractor, das 53 Faltungsschichten hat, mehr als das von v2 verwendete Darknet19, und das macht es genauer. Es verwendet auch einen Detektor für kleine Objekte, um alle im Bild vorhandenen kleinen Objekte zu erkennen, die mit v1 nicht erkannt werden konnten.
Muss gelesen werden: Schritt-für-Schritt-Methoden zum Erstellen Ihres eigenen KI-Systems heute
Zusammenfassung
Ich hoffe, der obige Überblick über die Objekterkennung und ihre Implementierung mit Deep Learning war hilfreich für Sie und hat Ihnen die Kernidee der Objekterkennung und ihre Implementierung in der realen Welt mit verschiedenen Methoden und insbesondere mit Deep Learning verständlich gemacht.
Die Objekterkennung kann in vielen Bereichen eingesetzt werden, um den menschlichen Aufwand zu reduzieren und die Effizienz von Prozessen in verschiedenen Bereichen zu steigern. Objekterkennung sowie Deep Learning sind Bereiche, die in Zukunft aufblühen und in zahlreichen Bereichen präsent sein werden. In diesen Bereichen gibt es viel Spielraum und auch viele Verbesserungsmöglichkeiten.
Kurse von upGrad
u pGrad hat umfassende Online-Schulungsprogramme zu Deep Learning und maschinellem Lernen entwickelt, die den Erwartungen der Branche entsprechen. Die Trainingsmodule und der Bildungsansatz von upGrad helfen den Schülern, schnell zu lernen und sich auf jede Aufgabe vorzubereiten.
Die wichtigsten Bildungsprogramme, die upGrad anbietet, sind für den Berufseinstieg und die Karrieremitte geeignet
1. PG-Diplom in maschinellem Lernen und KI : Es eignet sich für Berufstätige, die maschinelles Lernen von Grund auf erlernen und ihre Karriererollen auf Machine Learning Engineer, Data Scientist, AI Architect, Business Analyst oder Product Analyst verlagern möchten.
2. Master of Science in maschinellem Lernen und KI: Es handelt sich um ein umfassendes 18-monatiges Programm, das Einzelpersonen hilft, einen Master in diesem Bereich zu erwerben und sich Kenntnisse auf diesem Gebiet anzueignen sowie praktische Erfahrungen in einer Vielzahl von Projekten zu sammeln.
3. Fortgeschrittene Zertifizierung in maschinellem Lernen und Cloud von IIT Madras: Dies ist ein fortgeschrittener Kurs, der von IIT Madras für die Bereiche maschinelles Lernen und Cloud-Technologien angeboten wird.
4. PG-Zertifizierung in Machine Learning und Deep Learning: Dieser Kurs konzentriert sich auf Machine Learning und Deep Learning. Mit diesem Kurs können sich Studenten für Positionen wie Machine Learning Engineer und Data Scientist bewerben.
5. PG-Zertifizierung in maschinellem Lernen und NLP: Es ist ein gut strukturierter Kurs zum Erlernen von maschinellem Lernen und Verarbeitung natürlicher Sprache. Die Berufsmöglichkeiten für die Lernenden sind Data Scientist und Data Analyst.
upGrad hat den Lehrplan dieser Programme für maschinelles Lernen und Deep Learning unter Berücksichtigung der Prinzipien, Aspekte und Hauptkomponenten des maschinellen Lernens und der Beschäftigungsmöglichkeiten entwickelt, sodass Fähigkeiten von Grund auf neu entwickelt werden. Nach Abschluss des Programms von upGrad erwarten Sie enorme Karrieremöglichkeiten im Bereich maschinelles Lernen in verschiedenen Branchen und verschiedenen Rollen.
Das Endergebnis
Studenten können jeden der oben genannten Wege einschlagen, um ihre Karriere im maschinellen Lernen und Deep Learning aufzubauen. Die Vermittlungsunterstützung von upGrad hilft Studenten dabei, ihre Berufschancen durch spannende Karrieremöglichkeiten auf dem Jobportal, Karrieremessen und Hackathons sowie Vermittlungsunterstützung zu verbessern. Die Zukunft des Deep Learning ist rosiger mit steigender Nachfrage und Wachstumsaussichten und auch vielen Personen, die in diesem Bereich Karriere machen wollen. Nehmen Sie an einem dieser Kurse und vielen weiteren Kursen teil, die von upGrad angeboten werden, um in die Karrieremöglichkeiten des maschinellen Lernens einzutauchen, die auf Sie warten.
Welche Deep-Learning-Algorithmen werden bei der Objekterkennung verwendet?
Die Objekterkennung ist eine Computer-Vision-Aufgabe, die sich auf den Prozess des Lokalisierens und Identifizierens mehrerer Objekte in einem Bild bezieht. Deep-Learning-Algorithmen wie YOLO, SSD und R-CNN erkennen Objekte auf einem Bild mithilfe von Deep Convolutional Neural Networks, einer Art künstlichem neuronalem Netzwerk, das vom visuellen Kortex inspiriert ist. Deep Convolutional Neural Networks sind die beliebteste Klasse von Deep-Learning-Algorithmen zur Objekterkennung. Die Deep Convolutional Networks werden mit großen Datensätzen trainiert. Diese Netzwerke können Objekte viel effizienter und genauer erkennen als bisherige Verfahren.
Welcher Algorithmus eignet sich am besten zur Objekterkennung?
Es gibt viele Algorithmen zur Objekterkennung, die von einfachen Kästchen bis hin zu komplexen Deep Networks reichen. Der Industriestandard ist derzeit YOLO, die Abkürzung für You Only Look Once. YOLO ist ein einfaches und leicht zu implementierendes neuronales Netzwerk, das Objekte mit relativ hoher Genauigkeit klassifiziert. Kurz gesagt, ein neuronales Netzwerk ist ein System miteinander verbundener Schichten, die simulieren, wie Neuronen im Gehirn kommunizieren. Jede Schicht hat ihren eigenen Satz von Parametern, die entsprechend den bereitgestellten Daten optimiert werden. Die Daten, die aus jeder Schicht kommen, werden in die nächste Schicht eingespeist und so weiter, bis wir eine endgültige Vorhersage als Ausgabe erhalten.
Auf welche Schwierigkeiten sind Sie bei der Objektidentifikation gestoßen?
Es gibt viele Schwierigkeiten, denen wir bei der Objektidentifikation gegenüberstehen. Eine der Schwierigkeiten besteht darin, wenn das Objekt ein Bild einer Szene ist. In solchen Fällen müssen wir die Position der Kamera in der Vergangenheit kennen und wir sollten die Position des sich bewegenden Objekts schätzen. Aufgrund der Änderungen im Laufe der Zeit erhalten wir möglicherweise ein völlig anderes Bild, das nicht angepasst werden kann. Eine Möglichkeit, dieses Problem zu lösen, besteht darin, die Hilfe der Bewegungsschätzung in Anspruch zu nehmen. Eine andere besteht darin, die Neuberechnung mit Zeitunterschied durchzuführen.